OO Unit1 ViewBack
 OO第一单元总结
OO第一单元总结

综述
本单元作业主要处理函数的求导问题,分为3次作业。第一次单纯求取幂函数的导数,第二次作业加入三角函数 sin(x) 和 cos(x) 的求导问题,并支持项中含有多个因子;第三次作业加入了括号的支持。三次作业整体度过平稳。
自我代码分析
第一次作业
-
UML图
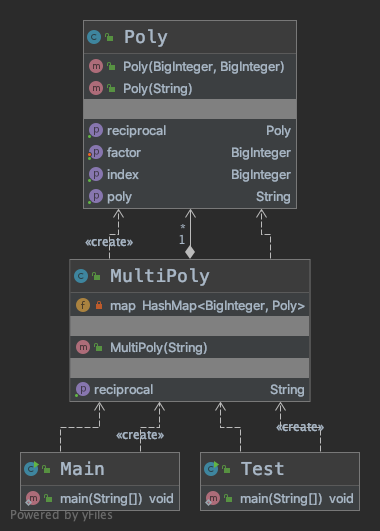
-
度量分析
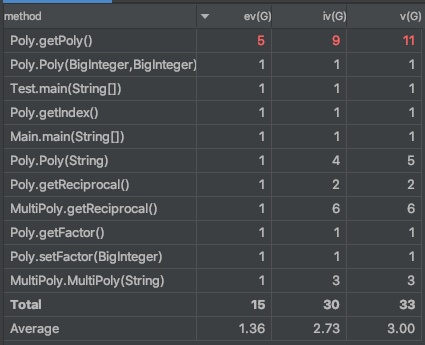
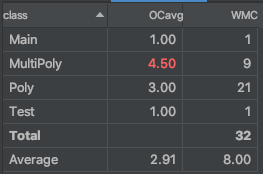
-
整体思路
第一次作业要处理的情况在不考虑迭代的情况下只有一种,在形式化表达中称为项:\[a*x^b \]之后多个项相加或者相减得到多项式。
而要进行的行为是求导,考虑求导的情况,项的求导行为与多项式的行为不一致,因而设置了两个类:- Poly,存储项,解决项的求导和输出;
- MultiPoly,存储多项式,解决多项式求导和输出。
而为了满足同类项合并问题,在MultiPoly中用HashMap存储Poly,用Poly的指数作为Key,如果Key相同则进行合并。
为了性能最佳(输出有效字符最少),在两个类进行toString操作时进行了一系列判断。 -
分析
- 复杂度
由于作业本身就并不复杂,整体代码的复杂度也并不高。上述图片中,Poly类的getPoly方法被认为复杂度最高,但其原因是在进行输出时,为了性能,作出了一系列判断;而MultiPoly类被认为整体复杂度高,是因为它承担着分割输入字符与优化输出但双重任务。
个人认为,两个类并没有进行多余的任务操作,但可以考虑用单独一类进行输出的优化操作。 - 设计缺陷
虽然考虑到了程序的迭代需要,已经进行了一些层次化设计,但完全没想到后期作业发展向了完全没有想到的方向(是自己菜没问题了)。本次作业我把常数因子作为了幂函数的系数处理,从而在加入新因子时,直接选择了重构。
- 复杂度
-
Bug与修复
自己本地测试时首先使用了指导书上给出的样例,之后自己构造了一些比较极端的数据。其实要是只找运算的Bug的话,只需要几组正常数据,接下来全部测极端样例就可以。
由于作业本身比较简单,自己本地测试完成之后,中测、强测、互测都没有被找出Bug。 -
互测
在Hack别人时,自己首先阅读了其他人的代码,着重分析了他们的读入——大多数用的是正则表达式——以及输出。这样成功分析出了两个人拥有的Bug。其他则盲测了一些极端数据,不过不出所料没有Hack成功。
第二次作业
- UML图
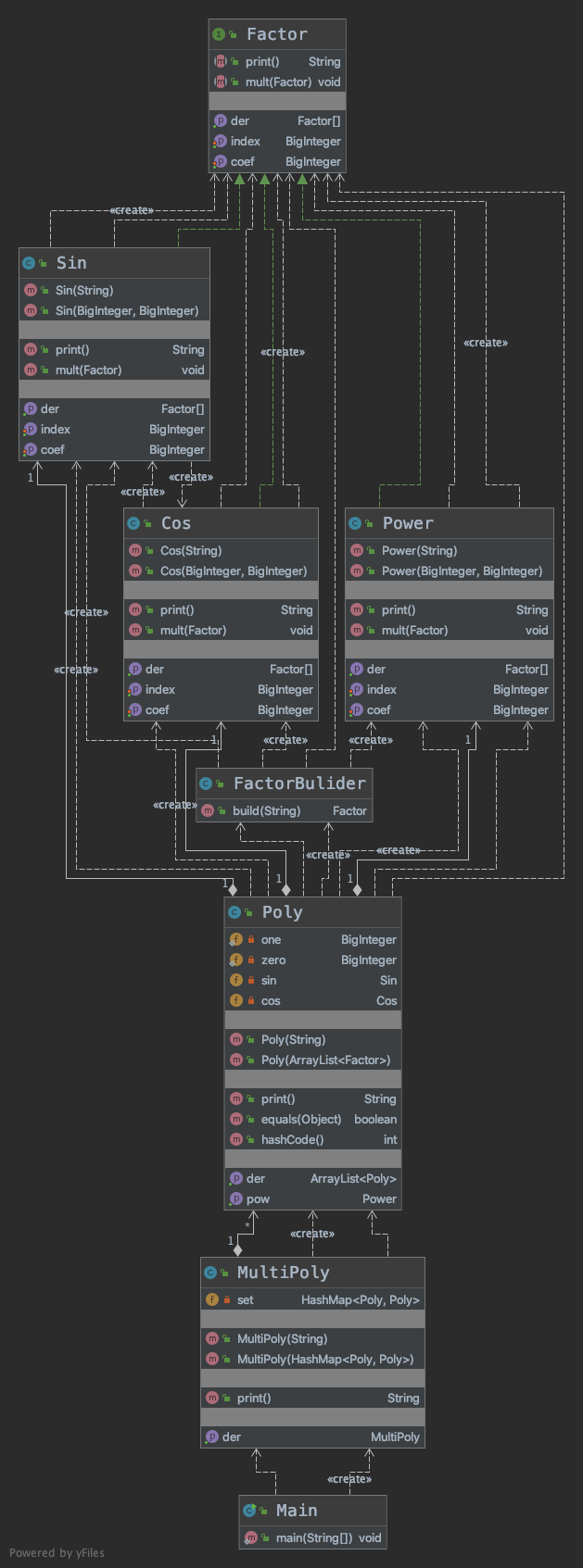
- 度量分析
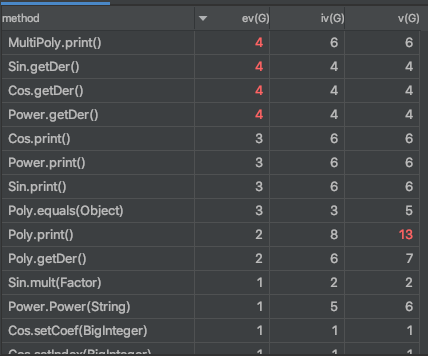
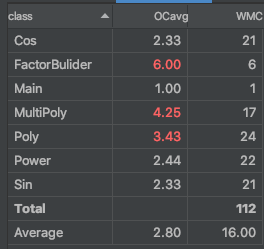
- 整体思路
正像之前所说,本次作业选择了重构。
考虑到因子种类增多,本次选择了用统一的接口管理所有的因子,并构造了工厂类用于创建因子类。Poly与MultiPoly类仍然存在,前者用ArrayList存放了因子,后者则用HashMap存放了Poly。Poly重写了equils和getHashCode两个函数用于存入HashMap。但自己做法强暴而危险,会在后续分析中指出。 - 分析
-
复杂度
整体复杂度较第一次作业有极大上升。但整体来说,复杂度最高的仍然是Poly的输出用函数;各种因子的求导方法也被认为是复杂度较高。输出的复杂仍然是为性能(有效输出长度)考虑,但求导方法复杂与自己的设计缺陷有关。 -
设计缺陷
自己对于Poly类的设计有明显缺陷。- 在求hashCode和判断是否相等时,只判断存储的sin、cos、x的指数是否相等,而不考虑系数。虽然完成了合并同类项的任务,但这么设计明显不安全;
- 在Poly类中强硬地存储了x、sin、cos因子各一个,并初始化系数为1,指数为0.如果Poly中含有常数项,则存放在幂函数因子的类里面。虽然不会出现错误,但显然扩展性、可迭代性不足。
对于各类因子,受到第一次作业的影响,我仍然用BigInteger存放它们的系数和指数,这与Poly中的处理有关,也明显不合适,最终增加了复杂度。
-
- Bug与修复
本次作业虽然需要判断输入错误的时候,但是不考虑空字符非法的情况使非法输入的判断较为简单。总体上本地测试时我使用的想法与第一次类似,但增加了更多的正常数据测试,并对WF情况进行了大量测试。
中测、强测、互测依然没有被测出Bug。虽然因为交的文件带自己学号被…… - 互测
仍然采用了阅读代码方法找Bug,但代码较长,部分代码理解困难,例如有些同学循环中会改变输入的字符串内容,不太好想象。而且更多时候找出来的是同学们面对WF数据的Bug。最终靠着极端数据Hack成功两次。
第三次作业
- UML图
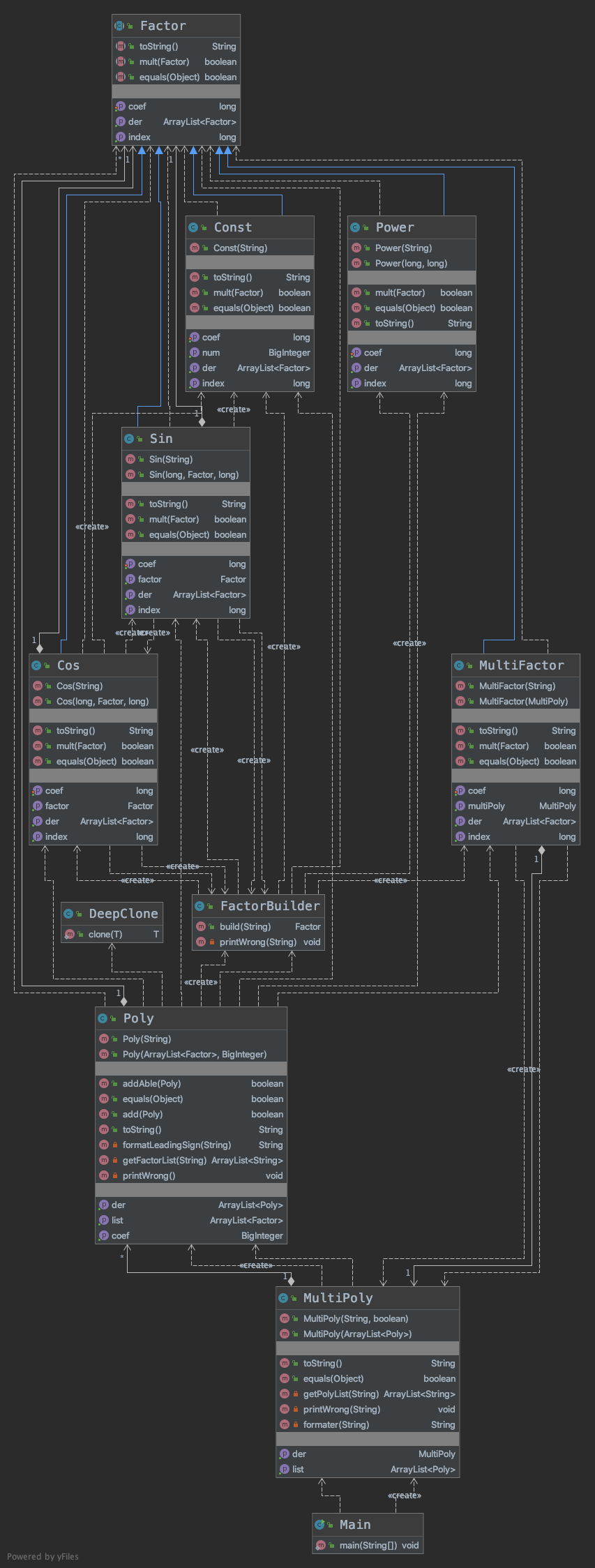
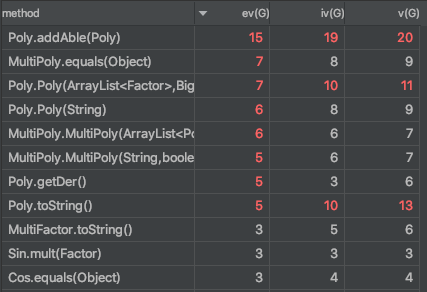
- 度量分析

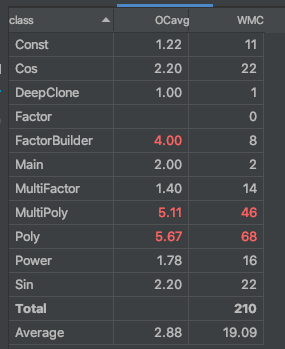
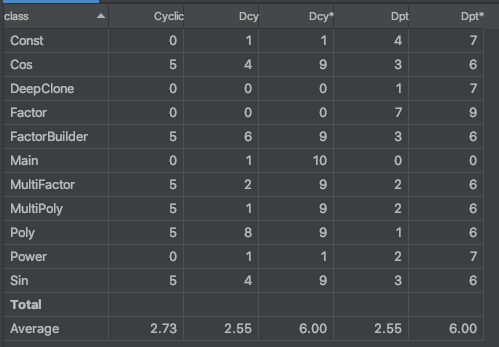
- 整体思路
由于之前的Poly的强硬操作,本次代码再一次进行了重构。
开始时受到第二次作业的影响,想先判断完成空字符是否合法后去除所有空字符再进行处理,这样可以部分保留原来的工厂模式下的因子类和工厂类,但由于总是不能很好解决含有正负号的常数项的空字符判断,导致中测都未能通过,因而后来放弃了先处理空字符位置。
Poly与MultiPoly中的合并问题比作业二复杂了许多,因而放弃了运用树存储,转而全部使用ArrayList。
之后,为了程序冗杂程度更低(其实本来就应该这样做),新设立了常数因子类和表达式因子类。三角函数因子的两类也增加新的属性:因子,来存放括号内内容。
这样层次划分下来,其实是针对形式化表述的每一层分别设置了类。每个类各司其职。
同时,由于更新的数据限制,指数的存放由原先的BigInteger类改为了长整形;也由于单独的常数因子类的出现,其他因子类中的系数设置为了整形。之所以没有取消存储系数是因为其在求导时可以保存过程值。 - 分析
- 复杂度
本次作业整体设计复杂度上升极大,与作业难度有很大关系。但可以发现,在拆分出表达式因子类和常数因子类之后,各因子类的复杂度有所下降;相应的用于创建用的FactorBuilder则复杂度上升。Poly和MultiPoly类则由于把正则表达式分割表达式的方法改为了用有限状态机分割字符串的方法,复杂度急剧上升——但其实性能本身应当比正则表达式强。
同时,为了仍然完成同类项的合并,除了主类其他类都重写了equils,上层次的类(项和多项式)判断运用递归而较为复杂。
要改进的话可以考虑为Poly、MultiPoly类中的分割用FSM单建立一类,就像使用Matcher类一样。 - 设计缺陷
在返回求导结果时和返回toString结果时,自己写的方法返回了NULL值用于表示求导为0等,造成了一些混乱。
- 复杂度
- Bug与修复
-
WF判断
开始时选择先集中判断空字符位置,之后去除所有空字符再进行进一步处理。
这样做造成了诸多不便,首先是判断空字符错误的情况很多,用于判断的正则表达式很长,效率堪忧;
开始时因为同时判断sin、cos不连续导致的WF和其他空白字符导致的WF,在识别sin后Matcher类不会再向后匹配,导致了一定错误;
之后发现很难在一开始的整个字符串中对 有符号整数 和 前有加减运算符的无符号整数 两种情况进行区分。
所以如前所述,放弃了先处理空字符位置判断。转为分割到以因子为单位判断WF。 -
返回NULL而爆栈
如前所述,自己在对 求导用方法 和 输出用方法 设置返回值时,设置了返回NULL的情况,这导致了一些调用空指针的问题。
修改后,在调用返回值时,增加了对返回值是否为NULL的判断,避免了此类错误。 -
把 $ x^2 $ 输出为 xx 导致输出格式错误
因为性能(有效字符长度)原因增加了这一优化,出错后放弃了这个优化。
样例: sin(x**2)
错误输出: cos(x * x)2*x -
在表达式因子输出时判断加括号问题出错
同样因为性能(有效字符长度)原因增加了这一优化,因为自己用于判断表达式项内多项式是否为单一因子的判断用正则表达式有问题。
样例(求导后的结果): x(sin(x)+(x))
错误的判断表达式会把上式括号内的 sin(x)+(x) 判断为一个表达式因子。
在修改了判断用正则表达式之后成功修复。
坑点:不要乱用 "." -
ArrayList浅拷贝导致的问题
通过序列化的方法实现类深拷贝。
参考了这篇博客,首先将每一个会被拷贝的类增加Serializable接口:- 对于因子类,将其统一接口改为抽象类,并实现Serializable;
- 对于Poly、MultiPoly,实现Serializable。
进而增加了用于实现深拷贝的类DeepClone。
-
未设置中间变量导致的性能问题
自己的程序在运行多括号嵌套时会运行超时。
样例: (((((((((((((((((x)))))))))))))))))
检查程序发现由于自己非常吝惜设置中间变量——比如之前所说对于调用求导方法是否返回值为空时,我原来会写成这样:if (x.getDer() != null) { ...... arrayListExample.add(x.getDer); }这样就会多次调用求导方法。在括号嵌套少时,程序运行没有明显问题,但括号嵌套多到一定程度时,由于对表达式因子求导会导致递归,多次递归会导致内存开销过大,且以此种写法递归(上述代码在要进行递归对程序中)会导致开销指数级别的增长。
修改后,设置了中间变量,减少递归次数,程序运行速度极大提升。
-
- 互测
终于到了读不下去大家代码的时候了(划掉),于是我选择了更多的极端数据来Hack。因为是C room,所以成功了不少。选择数据时尽量排除了相同“Bug点”的数据,尽力保证每一个数据对应一种Bug。数据来源则是自己已经测出的自己的Bug加自己认为的极端数据。
应用对象创建模式
- 整体分析
整体来说,个人认为本单元作业还是最适合用工厂模式进行解决。把要处理的表达式分层次来看,一个多项式包含了很多项,一个项则包含了很多因子。与项、多项式的相对单一不同,表达式有很多种,发展到作业三时,拥有了三角函数因子、幂函数因子、常数因子和表达式因子4种,其中三角函数因子还分为sin、cos两种。若要把各种因子“平级化”和“无差别化”,方便Poly(项)类的存储与操作,便自然想到了把所有因子继承自一个类或者实现统一接口。进而便想到了工厂模式。 - 自己的改变过程
作业一时完全没有想到后续作业如何展开,因而只是很保守的只分为了两个层次:多项式与项。可扩展性极差,因此后续选择重构。
作业二和作业三有了一定的迭代特征,基本保持了架构的不变。
但可以看出作业二仍然没有设计具有良好的扩展性。特别是Poly类中如前文中所说的“强硬”的操作,其重写equils()和getHashcode()时的做法等,显然在面对作业三时不得不被删除。作业三则较为具有扩展性,各类基本保证了“各司其职”。 - 作业三还可能的改进
- 改简单工厂模式为抽象工厂的模式。
目前作业三使用简单工厂模式,原因一是其要求工厂类对输入进行格式检查和类型判断——这两者可以同时进行;原因二是目前因子种类并不是很多。要是进一步增加复杂度,便需要作出改变。 - 分离Poly与MultiPoly中的部分方法。
目前上述两类复杂程度较高,仍需要考虑分离出部分方法成立新的类。
- 改简单工厂模式为抽象工厂的模式。
对比优秀作业
- 可以对字符串的处理单分一类
如前文所说,作业三中Poly和MultiPoly类中复杂度最高的方法都是处理字符串用的方法。虽然这个方法只适用于此类,但要缩减复杂度,亦可以认为这些方法行为相同而归为新但一类。 - 把整个过程拆分更细致
目前我的作业三分成了三个模块:读入、处理、输出;而大多数推荐代码分为了四个模块:读入、求导处理、优化处理、输出。或许把处理部分的求导和优化分开可以降低代码复杂度。 - 合理分包
目前为止程序仍然不太复杂,但还是要考虑到分包问题,层次化的结构对应层次化的文件,更加清晰。 - 每个人对表达式理解不同
直到作业三我仍然认为系数和指数为一个因子的属性,而项之间的加减操作看成是项自己系数的正负不同。而阅读代码发现有的大佬以栈的方式处理表达式中的每一种操作——加、减、乘、指数……这是对于表达式的观察角度不同,但后者但视角写出的程序划分会更加细腻。
心得体会
- 高瞻远瞩的不可能性。
或许是自己很悲观,抑或是自己太过菜了,感觉完全预测作业走向是不太可能的。即使预测到了一部分,如果不真的上手去做的话你很难理解其中的困难所在。想要做到真正的不重构代码,除了提供所有可能的扩展性和制造分离度更高的代码,别无他法。 - 代码要分模块进行开发和测试。
比如本次作业,应当分为读入、优化、输出三个部分,尽量减少每部分的重合度。可以分析出,优化部分的代码想要在作业间进行复用十分困难。而读入部分从第二次到第三次作业可能只是更改正则表达式的问题。 - 对异常情况的判断导致的Bug比正常运行程序导致的Bug多而难改
第三次作业的WF判断让我吃尽了苦头,最终直接导致了自己对Poly和MultiPoly类分割数据的方法从正则表达式转变为了FSM。
其实也可以理解——WF的情况比程序正常运行的情况多得多。我们不能针对每一种情况进行独有处理,而一旦出现Bug,很可能是多段代码关联起来导致的Bug,这必然会导致如上结果。
事实上,在作业二和作业三互测阅读他人代码时,自己最先发觉的Bug都和WF有关——当然互测不允许WF数据,这多少让我有些失落。 - 对自己好一点,别没事返回NULL
- 不要在作业中提交自己的个人信息!!!不要相信IDEA内置的git,它会莫名奇妙添加一些东西……
- OO道路漫长
接受面向对象的思想是个漫长的过程,就像它自己本身的发展一样;同时,面向对象自己本身有很多问题答案不唯一。只有更好的解决方法,没有最好的解决方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号