目标检测-基础知识
------------恢复内容开始------------
------------恢复内容开始------------
边界框:正好能框住物体的矩形框,bounding box(bbox)。它有两种表示方法,xyxy格式与xywh
真实框:数据集中标注的框,ground truth box(gt_box)
预测框:由模型预测输出的可能包含目标物体的边界框prediction box(pred_box)
检测任务输出:[L,P,x1,y1,x2,y2],L是类别标签,P是所属类别的概率,一张图片会对应多个预测框。
锚框:是人为构造出来的假想框,以某种指定的规则生成。生成方式:在图像上选取一个点,然后指定锚框生成的宽度和高度,例如,下图在(300,500)这个像素点生成了三个锚框

在目标检测任务中,一般是如下图方式:

预测框:在锚框基础上进行微调,由模型预测调整的幅度,每个候选区域(锚框)打上标签就可以建立模型了。
锚框跟真实框的重合度:交并比(Intersection of Union,简称:Iou)
YOLOv3--设计思想

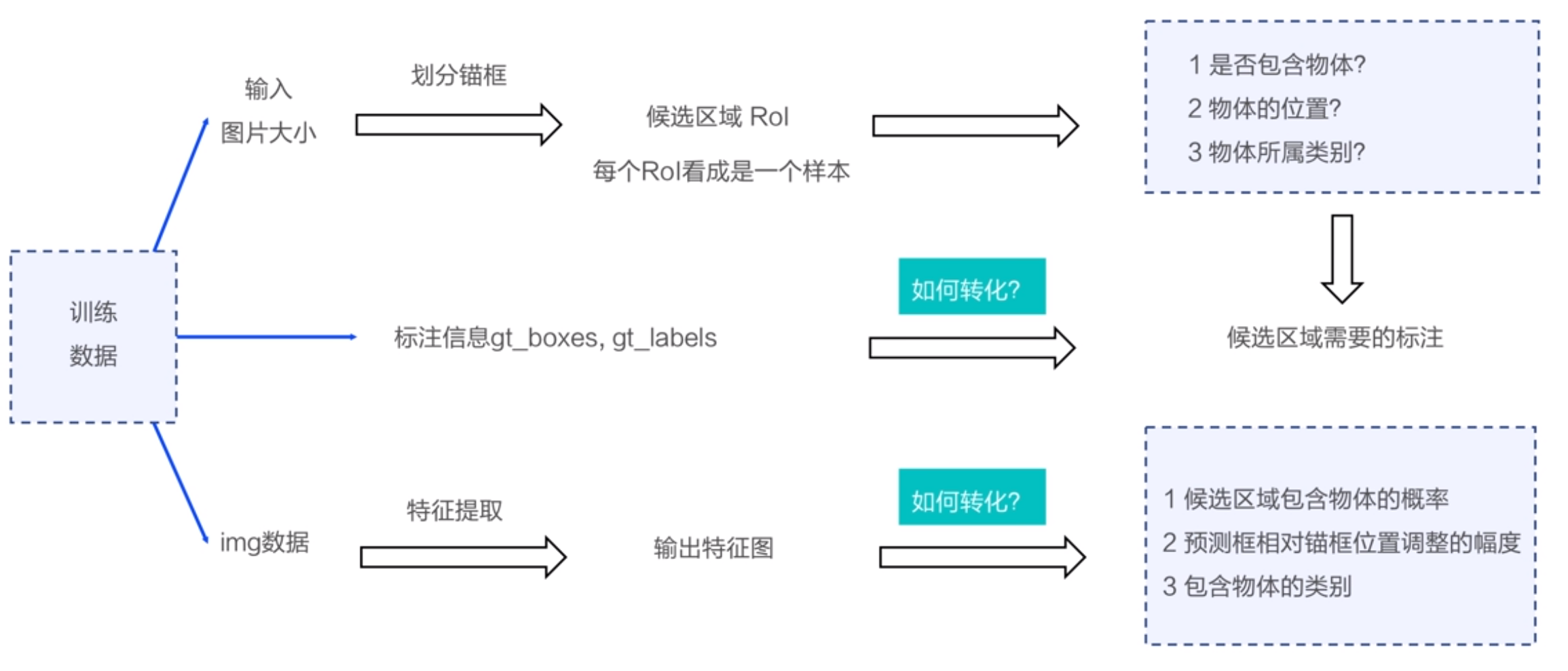
首先知道输入图片大小,平均分小格子,取每个格子中心点生成锚框(例如生成3个)。然后通过自己标注的信息gt_box,gt_labels给每个锚框标注三个东西(1.是否包含物体,2.物体的位置,3.物体所属类别),这时每个锚框相当于一条训练数据。同时图像数据经过卷积网络提取特征后,输出的特征图有三个信息(1.包含物体的概率,2.预测框相对于锚框位置调整的幅度,3.物体所属类别)。通过这三个信息(相当于是预测值),与每个锚框(相当于真实值)建立损失函数。开启端到端的训练。
YOLOv3--生成锚框
step1:将原图划分成多个小格子区域
step2:选取小格子中心点,生成一系列锚框
生成锚框规则:生成的宽高有3种[w,h]:[116,90]、[156,198]、[373,326]
例子:假设现在有一张900*900尺寸的输入图片,我使用30*30大小的格子,那么会划分出30*30个小格子。取每个小格子的中心点,生成[116,90]、[156,198]、[373,326]的区域。也即是每个小格子产生3个锚框。此时这张输入图片将产生30*30*3=2700个锚框(候选区域)。
YOLOv3--生成预测框
预测框:可以看作是在锚框的基础上做微调,可以调整中心坐标和宽度、高度。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号