Hadoop完全分布式搭建
1.准备并克隆好三台虚拟机(网卡配置文件,hosts配置文件),可参考我的这篇 https://www.cnblogs.com/Supre/p/13777059.html
2.下载jdk1.8,选择rpm包
3.安装jdk:【root@hadoop100 softwares】# rpm -i --prefix=/export/servers jdk-8u271-linux-x64.rpm
此时可以输入java version,如果输出java版本号,就安装成功了
4.配置jdk环境变量
打开bash_profile文件,在里面加入:
export JAVA_HOME=/export/servers/jdk1.8.0_271
export PATH=$PATH:$JAVA_HOME/bin
然后保存退出,运行source .bash_profile ,使得刚刚修改的该文件立即生效。
echo $JAVA_HOME,此时会输出刚刚配置的环境变量
5.配置免密码登录
1、先打开/etc/sysconfig/network ,配置以下内容:
NETWORKING=yes
HOSTNAME=hadoop100
2、配置ip和主机名字的映射关系
打开/etc/hosts文件,配置以下内容:
192.168.126.100 hadoop100
192.168.126.101 hadoop101
192.168.126.102 hadoop102
注意:这里的ip和主机名根据自己的写,这里的配置了,后续的配置文件中写入了hadoop100时,就类似写入了对应的IP:192.168.126.100
3、SSH免密码登录设置
1)、以hadoop100为中心,设置到其他机器的SSH免密码登录
输入ssh-keygen命令,然后一直回车操作
2)、进入.ssh文件夹。输入ls,查看生成的id_rsa私钥文件,id_rsa.pub公钥文件
3)、将公钥文件复制到hadoop100、hadoop101、hadoop102节点上,注意hadoop100本身也需要做免密码登录设置
ssh-copy-id -i ./id_rsa.pub root@hadoop100
ssh-copy-id -i ./id_rsa.pub root@hadoop101
ssh-copy-id -i ./id_rsa.pub root@hadoop102
4)、完成以上之后,测试ssh免密码登录
ssh hadoop101
此时,如果不需要输入hadoop101的密码,直接就登录成功的话,表示设置成功
6、配置hadoop
1)、下载解压缩hadoop
tar zxvf /export/softwares/hadoop-3.3.0.tar.gz -C /export/servers/
2)、配置hadoop-env.sh文件
export JAVA_HOME=/export/servers/jdk1.8.0_271
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
注意:这几个是hadoop3为了提升安全性而加入的,所以网上很多找不到这个配置方法,一开始我也踩了坑
3)、core-site.xml文件配置
这个配置方法在官网上有,在左下角configuration,给出了几个文件的配置方法

配置如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/hadoopdata</value>
</property>
</configuration>
4)、hdfs-site.xml文件
<configuration>
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop101:9868</value>
</property>
</configuration>
</configuration>
5)、配置workers文件
在该文件中加入以下三行:
hadoop100
hadoop101
hadoop102
6)、到此,文件都配置完成,但是不要忘记啊,还要去.bash_profile文件中配置HADOOP_HOME环境变量,并加入PATH中
export JAVA_HOME=/export/servers/jdk1.8.0_271
export HADOOP_HOME=/export/servers/hadoop-3.3.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME
保存后依然不要忘记source .bash_profile
7、将hadoop复制到其他节点
执行命令:
scp -r ./hadoop-3.3.0 root@hadoop101:/export/servers/
scp -r ./hadoop-3.3.0 root@hadoop102:/export/servers/
8、格式化
第一次安装Hadoop需要格式化,以后就不要,千万记住,不要手残去格式化,这是个坑。格式化会导致namenode的id变,而datanode的id不会变化,这样执行hdfs命令会出现路径之类的错误。总之,初始化一次就够了。万一初始化多次造成错误,可以留言!!
hdfs namenode -format
9、启动命令
我比较喜欢用 start-all.sh
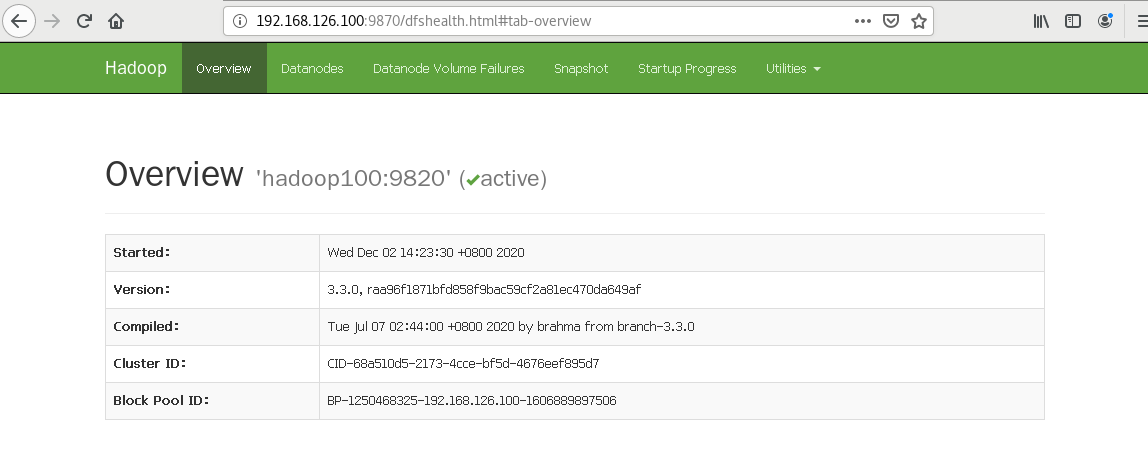
10、打开浏览器查看HDFS监听页面,到此才算成功了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号