
websocket+probuf.原理篇
1、WebSocket
WebSocket,大家都知道,既然名字包含Socket,那么和Socket肯定差别不大,对,你没有搞错,的确差别不大。
在网络编程中,我们一般的协议都是基于TCP/IP,WebSocket也不例外。和HTTP一样,他也有自己的头部和具体的数据而已。
来看看。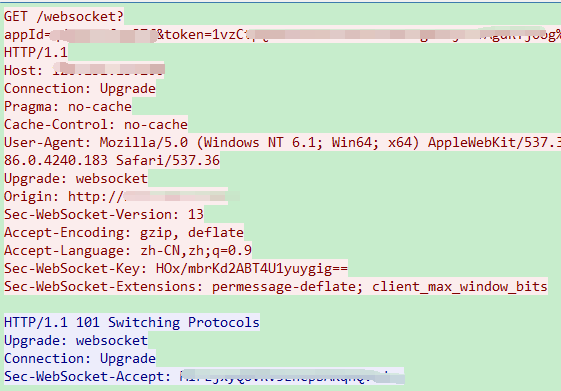
这是一个,websocket发起的连接,首先一个http的请求,告诉服务器,我要发送WebSocket的连接,服务器,返回一段ok.后面就可以继续使用这个连接,进行基本的WebSocket请求了。
其实,WebSocket和普通的Socket没啥差别,都是send,receive,收发数据,只是数据的格式化需要特殊处理一下。下面来说明一下。
WebSocket的发送的数据格式(接收和发送是一样的):
来张网图:
来段网文:解释一下:
FIN,指明Frame是否是一个Message里最后Frame(之前说过一个Message可能又多个Frame组成)RSV1-3,必须是0,除非有扩展定义了非零值的意义。Opcode,这个比较重要,有如下取值是被协议定义的-
%x0 denotes a continuation frame
-
%x1 表示一个text frame
-
%x2 表示一个binary frame
-
%x3-7 are reserved for further non-control frames
-
%x8 表示连接关闭
-
%x9 表示 ping (心跳检测相关,后面会讲)
-
%xA 表示 pong (心跳检测相关,后面会讲)
-
%xB-F are reserved for further control frames
-
Mask,这个是指明“payload data”是否被计算掩码。这个和后面的Masking-key有关(如果=0,不需要计算结果:结果明文,如果是=1,name就配合后面四个字节的masking-key,来处理解码操作。字节按位异或,四个一次循环。)
if(mask == 1){
byte[] payload = xxxx; // 这里假设已经得到
byte[] mask_key = new byte[4];// 这里假设已经得到
for(int i=0;i<payload.Count;i++){
payload[i] = (byte)(payload[i] ^ mask_key[i%4]);
}
// 这样就可以解码出来明文了
}else{
// 明文的情况,2字节后面或者4字节,12字节后面就是具体的数据了,(真实情况,根据具体的数据来)。
}
Payload len,数据的总长度,有三种情况[<126,>126 && <= 65535,> 65535], 这三种情况,占位不同,第一种,默认占位(它本身),(后续字节是数据或者masking-key(mask为1才有masking-key))
Masking-key,加密作用Payload data,帧真正要发送的数据,可以是任意长度,但尽管理论上帧的大小没有限制,但发送的数据不能太大,否则会导致无法高效利用网络带宽,正如上面所说Websocket提供分片。
2、Probuf
我们网络中常常会对数据进行编码然后传输,一般我们回用到的一些方式 content原文,xml,json,还有就是我们呼之欲出的probuf了。
这种编码有什么好处呢,大大减少了网络带宽的消耗,同时减少了了数据解析的时间损耗。
再来一波网图吧,数据的排列规则。
图1: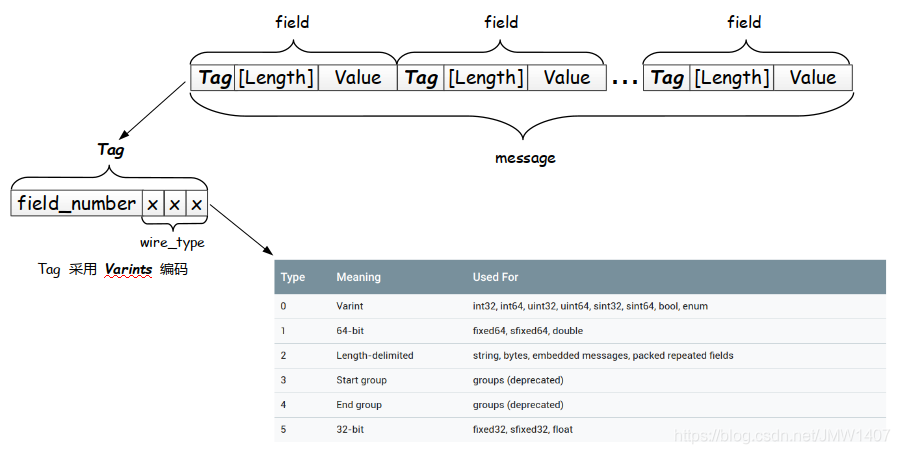
明显,这里就可以看出来,Tag占用一个位置,length占用一个位置,一般情况,如果是数据很长,namelength就可能占用多个字节了。根据length的首位判定。(length也是第一位是标识是否需要第二个直接加入计算,一次类推,这里解释一下:
Varint:一种,把首位,作为判断条件,来对length进行计算的方式。
0-0111 1111,一个字节可以表示范围: [0,0x7f]的大小,
1000 0000 - 0000 0001 ----- 1111 1111 - 0111 1111 , 二个字节可以表示范围:[1<<7, 0x7f<<7 + 0x7f]
1000 0000 - 0000 0000 - 0000 0001 ----- 1111 1111 - 1111 1111 - 0111 1111 , 三个字节可以表示范围:[1 << 7 * 2, 0x7f<<7 <<7 + 0x7f<<7 + 0x7f]
这样一般来说,就只需要小部分直接寄可以处理大部分数据了。
所以诞生了probuf的说明或者解析文件:(来个栗子)
message DownStreamMessages { repeated DownStreamMessage list = 1; required int64 syncTime = 2; optional bool finished = 3; } message DownStreamMessage { required string fromUserId = 1; required ChannelType type = 2; optional string groupId = 3; required string classname = 4; required bytes content = 5; required int64 dataTime = 6; required int64 status = 7; optional int64 extra = 8; optional string msgId = 9; optional int32 direction = 10; optional int32 plantform =11; optional int32 isRemoved = 12; optional string source = 13; optional int64 clientUniqueId = 14; optional string extraContent = 15; } enum ChannelType { PERSON = 1; PERSONS = 2; GROUP = 3; TEMPGROUP = 4; CUSTOMERSERVICE = 5; NOTIFY = 6; MC=7; MP=8; }
这里面有几个关键字需要处理一下:(bool和enum都是作为整数处理即可),字段后面的 = 1; = 2 表面这个的filed_number.值。
required 一般都是必须的
optional 非必须的
repeated 重复的,一个表示集合。
网图奉上:
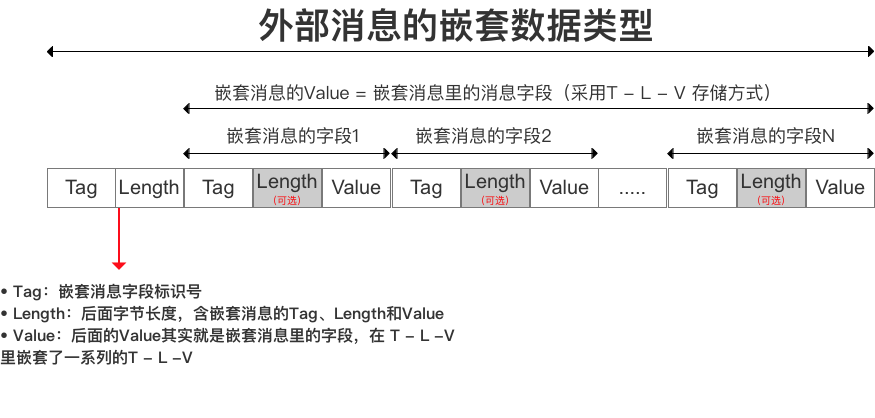
编码数据长度。

上图就是数据的 排列规则了,数据比较紧凑。
特别说明repeat的情况,repeat后面的length是指读取这个需要用到的字节数。而不是重复的个数。
参考:https://juejin.im/post/6844903582290935822
参考:https://blog.csdn.net/carson_ho/article/details/70568606
参考:https://blog.csdn.net/JMW1407/article/details/107197938/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号