Scrapy原理
1.架构组成
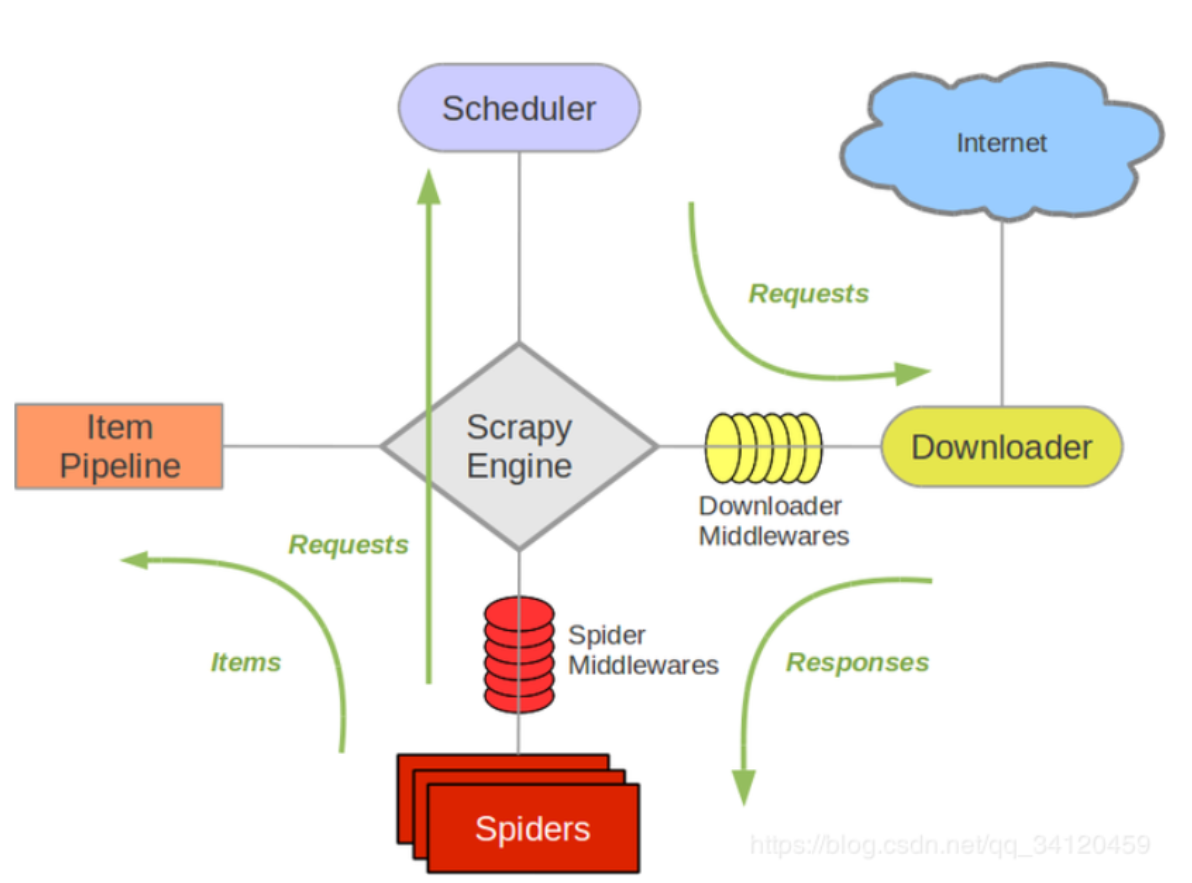
- 引擎:自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
- 下载器:从引擎处获取到请求对象后,请求数据
- spiders :Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例
如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。 - 调度器 :有自己的调度规则,无需关注
- 管道(Item pipeline):最终处理数据的管道,会预留接口供我们处理数据
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行
一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
2.工作原理
-
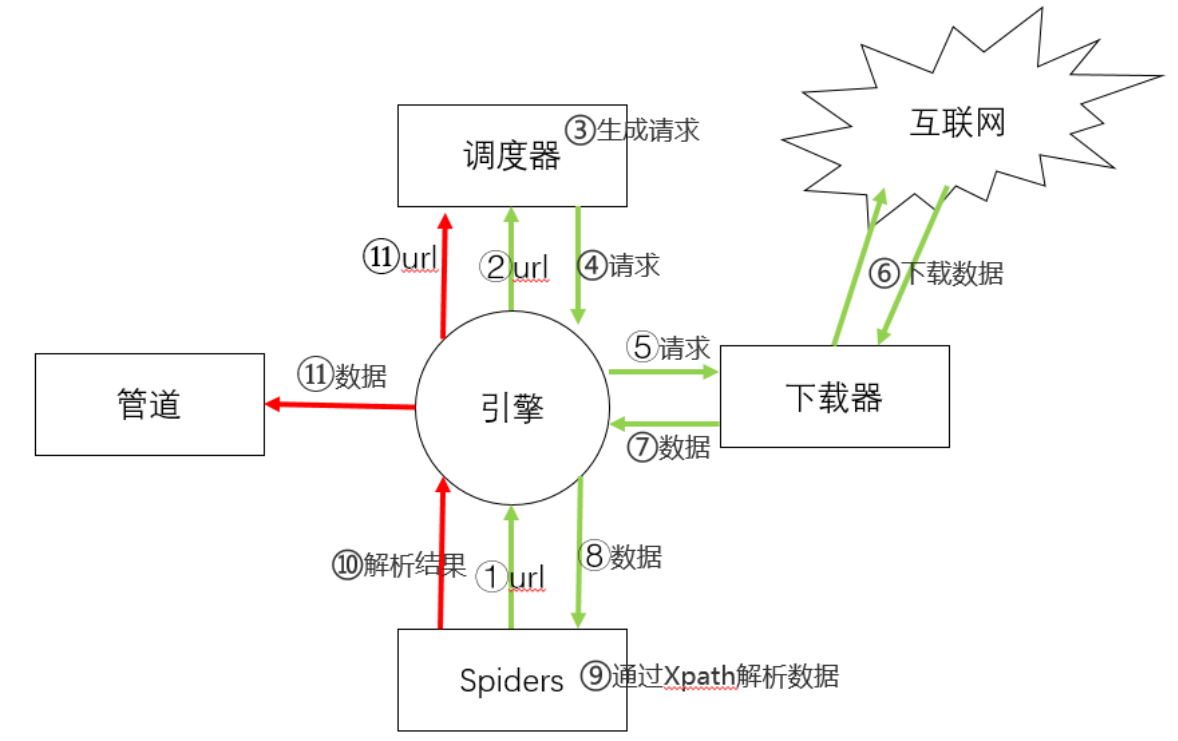
引擎(Engine)向Spiders要url
-
引擎将要爬取的url给调度器(Scheduler)
-
调度器将url生成请求对象放入到指定的队列中
-
从队列中出队一个请求
-
引擎将请求交给下载器进行处理
-
下载器发送请求获取互联网数据
-
下载器将数据返回给引擎
-
引擎将数据再次给到Spiders
-
Spiders通过XPath解析该数据,得到数据或者url
-
Spiders将数据或者url给到引擎
-
引擎判断是数据还是url
数据,交给管道(item pipeline)处理,
url,交给调度器处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号