

jmeter数据分析,压测实现
 1.开始之前,先介绍下压测的一些基本插件:线程组常用分为三类:user thread , step thread ,ultimate thread :
1.开始之前,先介绍下压测的一些基本插件:线程组常用分为三类:user thread , step thread ,ultimate thread :
user thread :最通用的最原始的线程实现;分为循环实现线程,可以实现线程delay延时;
step thread :能够实现一些较复杂场景,比如常见爬坡类类型,以及持续在线场景
This Group will start 10 threads:这次的测试总共会起10个线程。 First , wait for 0 seconds:等待0s后开始起线程,也就是不等待直接起线程。 Then start 0 threads;从0个线程开始持续增加。 Next,add 2 threads every 3 seconds:每增加2个线程后会运行3s,再起余下的2个线程,再运行3s,以此类推。 Using ramp-up 6seconds:前面每起2个线程的时候花6s,与上面结合起来即6s内起2个线程,运行3s,然后再再6s内再起2个线程,再运行3s,以此类推。 Then hold load for 30 seconds. :全部的线程起来后,运行30s 后开始停止。 Finally , stop 2 threads every 1 seconds:最后停止线程,2个线程停一次,等1s再
ultimate thread:
参数含义解释: Start Threads Count:当前行启动的线程总数 Initial Delay/sec:延时启动当前行的线程,单位:秒 Startup Time/sec:启动当前行所有线程达峰值所需时间,单位:秒 Hold Load For/sec:当前行线程达到峰值后的稳定加载时间,单位:秒 Shutdown Time:停止当前行所有线程所需时间,单位:秒
2。关于同步定时器syn timer:

它有两个参数:1.模拟用户组数量,我这里把他称为集合释放阈值意思,就是当你想实现用户达到一定数量时一起同时请求目的,他会根据你的 timeout时间设置决定什么时间发送已经集结的thread请求requests,
2. time out in millionseconds 简称ttl ,意思是超时时间
你需要注意的有以下:
1.模拟用户数量的值不能够大于线程组user thread 的线程数所填写的值
2、syn timer 的超时时间为0表示定时器会等到模拟用户数达到设置数量才会一次发出所有请求
3、非0时,如过设置时间内还未达到集合要求数量,将不会在等待后面还未到达请求,直接发送所有已集结threads 的requests;
如果你的模拟用户组数量也就是集结数量默认为0,它会按照user thread 线程数进行等待,
对于超时时间研究过一个小技巧就是time>模拟用户组数量*1000/user thread number/loop count 可以避免因为设置 timeout =0 时,出现一直等待模拟用户组数量卡死现象情况
3.关于插件: tps trt, activate thread ,监控汇总以及图形插件下载地址:Extras.jar,下载完成后丢进jmeter 的lib/ext下面重启jmeter插件就会生效
https://github.com/chen1932390299/JavaProject/raw/JmeterJavaBranch/lib_jtlChange/ext/JMeterPlugins-Extras.jar
当然如果你有其他的插件也想下载可以使用下面这个old jmeter plugin,不知道什么时间放弃维护,应该是国内源download速度比官网快很多:
https://jmeter-plugins.org/downloads/old/
4.数据分析:对于压力测试很多人都不考虑持续压力测试的这种情况,以较短时间的一段数据来衡量整个服务性能数据是很不科学的:
首先什么是虚拟用户数,什么是并发量,甚至有些pm在表达自己或者用户需求时都没搞清并发和用户数的具体区别,jmeter用户模拟是通过线程实现,一个线程代表着一个虚拟用户;很多新手一上来就是线程数等于并发数堆上去,就是干,更有甚者直接拿着一台windows模拟出5000,甚至更高的数据并发,被很多经验丰富的技术人员所diss,实际上根本不能达到效果,而且一旦出现ko你分不清ko的请求哪些是服务器无法处理导致的error还是因为本地内存资源耗尽导致的request的error;
或许有人会讲了并发本就没有真正意义的并发的确我们并发不可能一点点时间都不差,我们终不过是实现一个更接近并发场景的场景构造就和我们极限求导一个思想,无限逼近那个理想效果;广义并发我们称为同一时刻发生的所有用户行为,可以做不同的事,也可以做相同的事;狭义来讲,我们认为并发是同一时间做相同的事;那么有没有想过为什么不能上面那些新手那样直接怼就是干呢,首先线程启动是又先后顺序的,其次压力机器的资源是有限的当达到上限会对线程排队;再者,单台机器内存有限不可能无限制启动5000甚至上万线程那样本地早就oom了,想要实现更高的并发需要通过分布式压测来解决资源问题分摊请求压力一台master执行机器可以对应多台slave 负载机器实现高并发的请求
gpt推荐配置 一般是负载机配置: 16core 64g , 核心数*1000-300=期望施压机器的负载并发线程数的能力值
以下是Extras的监听器部分插件:
activate thread 活跃线程数监控:

transcations thrououtput/threads监控 :
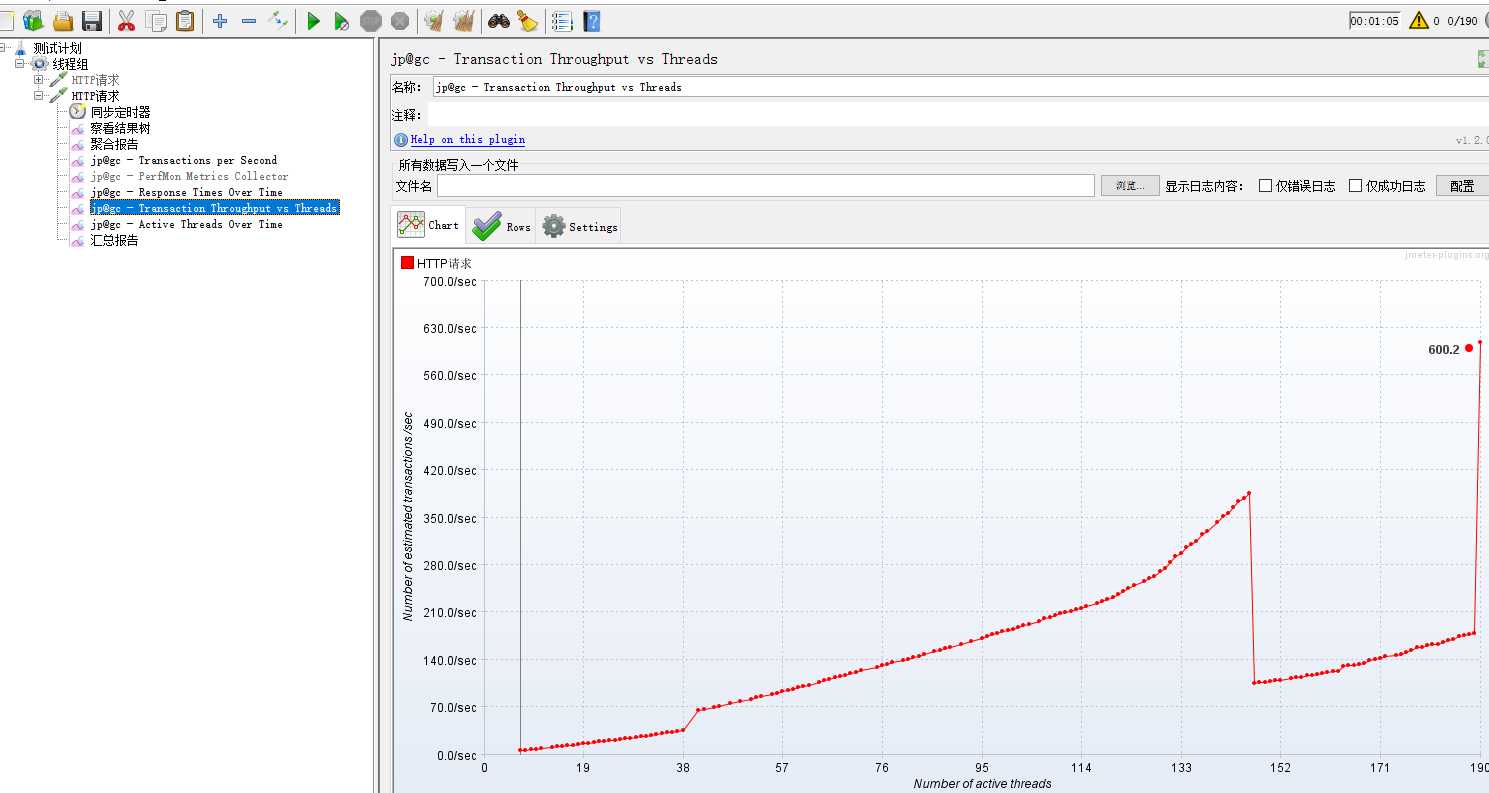
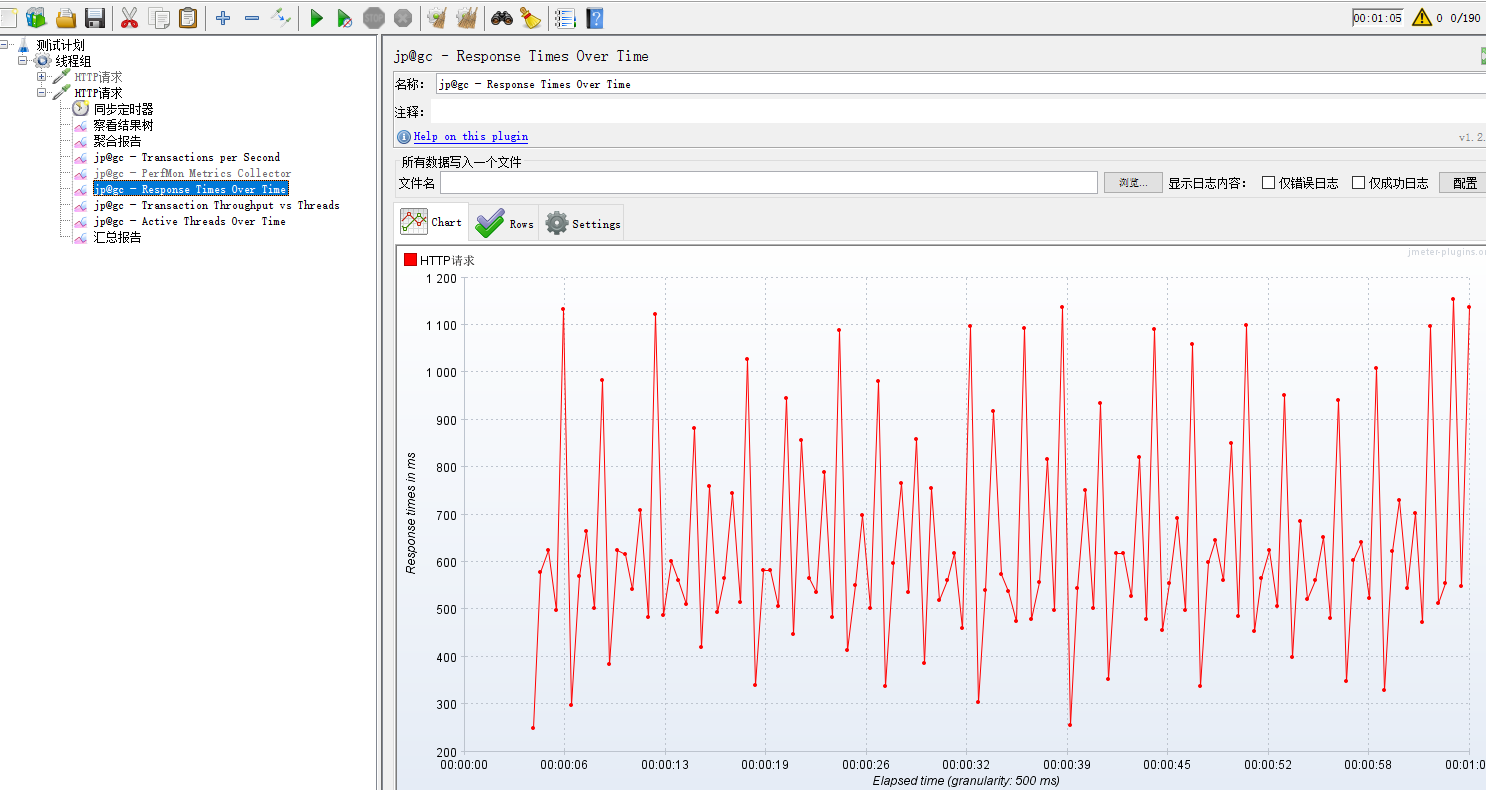
rtt 响应时间监控:
transcations persecond 秒处理事务数 监控数据:

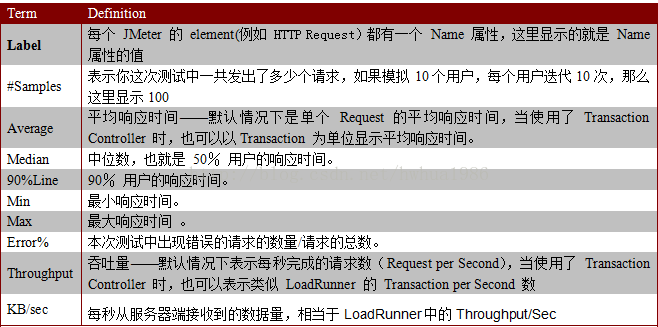
聚合报告:

插件功能解释:

在文章的最后我想推荐一篇国外期刊给大家:让你学习如何通过十二种方式去分析性能数据,如何成为一名优秀的专业的技术人员:
https://octoperf.com/blog/2017/10/19/how-to-analyze-jmeter-results/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号