Failed to create Spark client for Spark session
最近在hive里将mr换成spark引擎后,执行插入和一些复杂的hql会触发下面的异常:
org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session c5924990-6187-4a15-a760-ec3b1afbc199
未能创建spark客户端的原因有这几个:
1,spark没有打卡
2,spark和hive版本不匹配
3,hive连接spark客户端时长过短
解决方案:
1,在进入hive之前,需要依次启动hadoop,spark,hiveservice,这样才能确保hive在启动spark引擎时能成功
spark启动:
cd /opt/spark ./sbin/start-all.sh
2,版本问题是最常见也是出现最多的问题,我用的版本依次为hadoop3.3.0,hive3.1.2,spark2.4.7,之前测试过spark3.0.1,发现和hive不兼容
这里还需要注意Apache官网的提供了如图所示的几个spark包版本:

但在集成hive时spark本身不能自带hive配置,所以只有第三个是可以用的,但是我测试了一下在我的电脑上还是报错,所以我选择了自己编译,下载最后一个源码包,解压后进入spark目录
输入命令:
./dev/make-distribution.sh --name without-hive --tgz -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.0 -Pparquet-provided -Porc-provided -Phadoop-provided
但是发现编译卡住了,原来编译会自动下载maven,scala,zinc,存放在build目录下,如图:
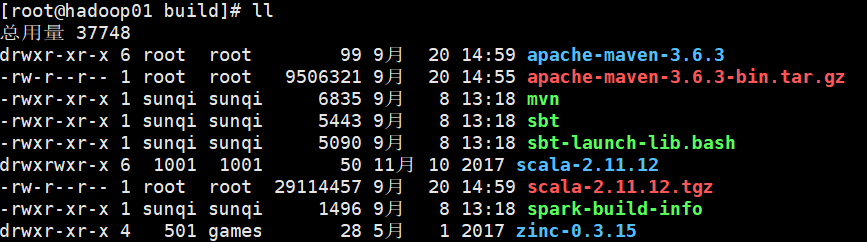
由于下载过于缓慢,这里直接将这三个包放在build目录下,解压好,编译时会自动识别,可以省去很多时间,快速进入编译,需要压缩包的可以关注公众号:Tspeaker97 给我发消息找我要
编译过程比较慢,我花了30分钟才将spark编译好,中间还网络断流卡住失败了一次,如果不能访问外网的,建议将maven镜像改为阿里云。
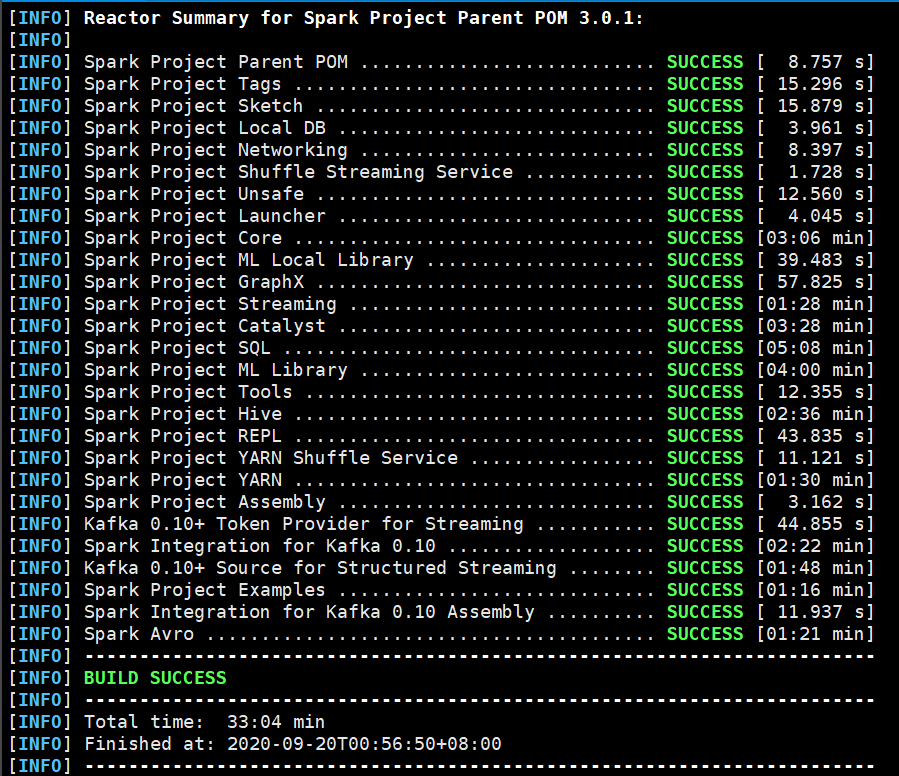
编译完成后在spark目录下就可以看到编译出的tgz包,解压到对应目录:
vim spark-env.sh 插入如下代码: export SPARK_DIST_CLASSPATH=$(hadoop classpath)
接下来就是hive的设置,这里我用的是公司编译好的版本,大小比Apache官网大一点,想要可以微信扣我
进入hive/conf目录:
vim spark-defaults.conf 插入如下代码: spark.master yarn spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop01:9820/spark-history spark.executor.memory 2g
在hdfs创建对应目录并拷贝jar包:
hadoop fs -mkdir /spark-history hadoop fs -mkdir /spark-jars hadoop fs -put /opt/spark/jars/* /spark-jars
在hive/conf/hive-site.xml中增加:(这里特地延长了hive和spark连接的时间,可以有效避免超时报错)
<!--Spark依赖位置--> <property> <name>spark.yarn.jars</name> <value>hdfs://hadoop01:9820/spark-jars/*</value> </property> <!--Hive执行引擎--> <property> <name>hive.execution.engine</name> <value>spark</value> </property> <!--Hive和spark连接超时时间--> <property> <name>hive.spark.client.connect.timeout</name> <value>100000ms</value> </property>
然后启动spark服务,hive服务,并进入hive客户端,执行hql:
set hive.exec.mode.local.auto=true; create table visit(user_id string,shop string) row format delimited fields terminated by '\t'; load data local inpath '/opt/hive/datas/user_id' into table visit; SELECT t1.shop, t1.user_id, t1.count, t1.rank FROM (SELECT shop, user_id, count(user_id) COUNT, rank() over(partition BY shop ORDER BY count(user_id) DESC) rank FROM visit GROUP BY user_id, shop ORDER BY shop ASC, COUNT DESC ) t1 WHERE rank <4;
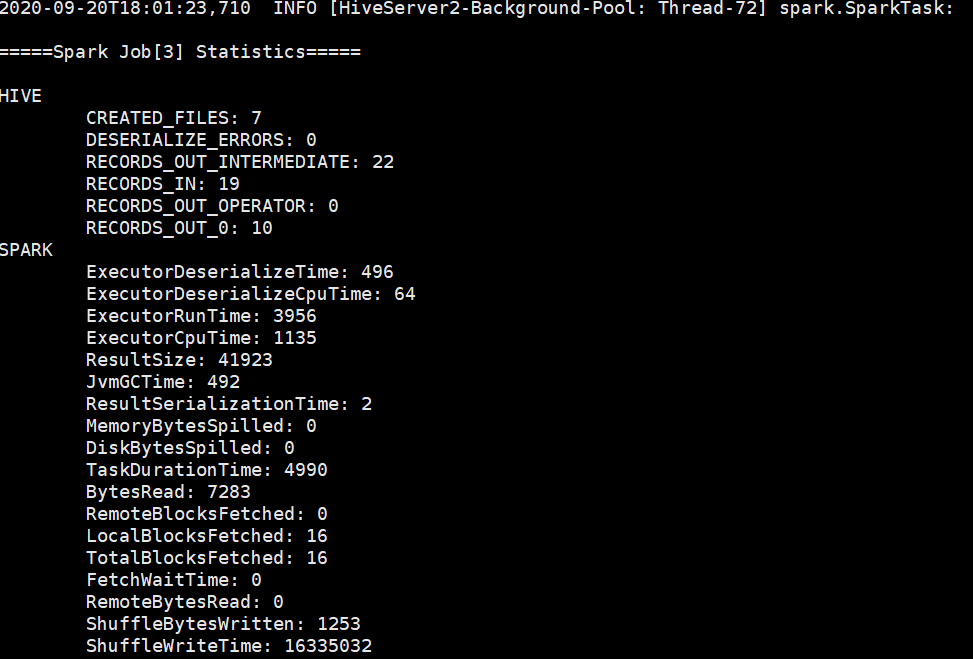
spark引擎成功启动:
如果有其他问题,欢迎叨扰:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号