20199318 2019-2020-2 《网络攻防实践》第十周作业
20199318 2019-2020-2 《网络攻防实践》第十周作业
1.知识点梳理与总结
1.1 软件安全基本知识
1.1.1 软件安全困境
软件安全困境三要素:复杂性、可扩展性和连通性
- 复杂性:软件规模越来越大,越来越复杂,也就意味着软件的bug会越来越多。
- 可扩展性:现代可扩展软件本身的特性使得安全保证更加困难,很难阻止攻击者和恶意代码以不可预测的扩展方式来入侵软件和系统,因此在设计每一种软件的可扩展机制时,都必须考虑安全特性,然而很多软件厂商并不能做到这一点,往往在推出一个基本没有任何安全考虑的扩展机制,遭受攻击者利用造成重大危害之后,才会关注和完善安全保护机制。
- 连通性:高度的连通性使得一个小小的软件缺陷就有可能影响非常大的范围,从而引发巨大的损失,蝠虫的大规模传播就验证了连通性对软件安全的影响作用。
1.1.2 软件安全漏洞类型
软件安全漏洞类型从技术上主要包括如下几类:
- 内存安全违规类:内存安全违规类漏洞是在软件开发过程中在处理RAM (random-access memory)内存访问时所引入的安全缺陷,如缓冲区溢出漏洞和Double Free、Use-after-Free等不安全指针问题等。
- 输入验证类:输入验证类安全漏洞是指软件程序在对用户输入进行数据验证存在的错误,没有保证输入数据的正确性、合法性和安全性,从而导致可能被恶意攻击与利用。
- 竞争条件类:竞争条件类缺陷是系统或进程中一类比较特殊的错误,通常在涉及多进程或多线程处理的程序中出现,是指处理进程的输出或者结果无法预测,并依赖于其他进程事件发生的次序或时间时,所导致的错误。
- 权限混淆与提升类:权限混淆与提升类漏洞是指计算机程序由于自身编程疏忽或被第三方欺骗,从而滥用其权限,或赋予第三方不该给予的权限。权限混淆与提升类漏洞的具体技术形式主要有Web 应用程序中的跨站请求伪造(Cross-Site Request Forgery,CSRF)、Clickjacking、FTP反弹攻击、权限提升、“越狱” (jailbreak)等。
1.2 缓冲区溢出基础概念
1.2.1 缓冲区溢出基本概念
缓冲区溢出是计算机程序中存在的一类内存安全违规类漏洞,在计算机程序向特定缓冲区内填充数据时,超出了缓冲区本身的容量,导致外溢数据覆盖了相邻内存空间的合法数据,从而改变程序执行流程破坏系统运行完整性。理想情况下,程序应检査每个输入缓冲区的数据长度,并不允许输入超出缓冲区本身分配的空间容量,但是大量程序总是假设数据长度是与所分配的存储空间是相匹配的,因而很容易产生缓冲区溢出漏洞。
1.2.2 缓冲区溢出攻击原理
缓冲区溢出漏洞根据缓冲区在进程内存空间中的位置不同,又分为栈溢出、堆溢出和内核溢出这三种具体技术形态,栈溢出是指存储在栈上的一些缓冲区变景由于存在缺乏边界保护问题,能够被溢出并修改栈上的敏感信息(通常是返回地址),从而导致程序流程的改变。堆溢出则是存储在堆上的缓冲区变量缺乏边界保护所遭受溢出攻击的安全问题,内核溢出漏洞存在于一些内核模块或程序中,是由于进程内存空间内核态中存储的缓冲区变量被溢出造成的。其中栈溢出在各类缓冲区溢出漏洞中是最容易理解,也是最早被发现和利用的技术形态。
栈溢出安全漏洞示例:

在上述示例代码中的return_input()函数中定义了一个局部变最array,为30字节长度 的字符串缓冲区,按照我们对进程内存空间布局和各类型变鼠存储位置的了解,函数局部变量:将被存储在栈上,并位于main()函数调用时压栈的下一条指令(即“return O;”)返回地址之下,而在return_input()函数中执行gets函数将用户终端输入至array缓冲区时,没有进行缓冲区边界检査和保护,因此如果用户输入超出30字节的字符串时,输入数据将会溢出array缓冲区,从而覆盖array缓冲区上方的EBP和RET, 一旦覆盖了RET返回地址之后,在return_input()函数执行完毕返回main。函数时,EIP寄存器将会装载栈中RET位置保存的值,此时该位置已经被溢出改写为“AAAA”(即0x41414141),而该地址可能是进程无法读取的空间,所以造成程序的段错误(',Segmentation faulf).使用GDB来对这个示例程序进行调试,可以看到在程序执行造成段错误时,通过infomgisters査看EBP和EIP寄存器的值均为0x41414141,这说明我们输入的超出长度限制的A溢出了缓冲区,并修改了栈中原先保存的EBP和RET值。
1.3 Linux平台上的栈溢出也shellcode
1.3.1 Linux平台栈溢出攻击技术
Linux平台中的栈溢出攻击按照攻击数据的构造方式不同,主要有NSR、RNS、和RS三种模式
-
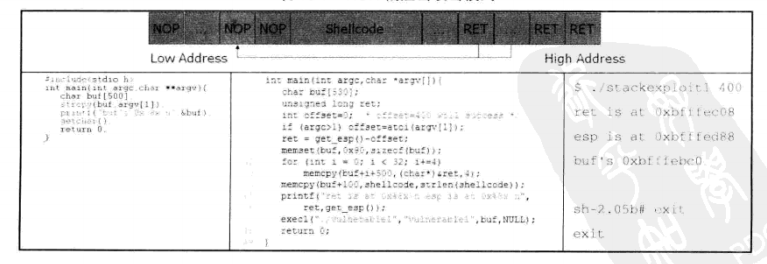
NSR模式:NSR模式主要适用于被溢出的缓冲区变最比较大,足以容纳Shellcode的情况,其攻击数据从低地址到高地址的构造方式是一堆Nop指令(即空操作指令)之后填充Shellcode,再加上一些期望覆盖RET返回地址的跳转地址,从而构成了NSR攻击数据缓冲区,如下表所示。通过将这个攻击缓冲区作为vulnerable1.c漏洞程序输入,夏制至其局部变量buf时,将溢出并改写main函数的返回地址,从而使得程序执行流程跳转至Nop指令所填充出来的“着陆区”中,无论跳转至哪个Nop指令上:,程序都会继续执行,并最终运行Shellcode,向攻击者给出Shell.
![]()
-
RNS模式:一般用于被溢出的变量比较小,不足以容纳shellcode的情况,如下表所示。攻击数据从低地址到高地址的构造方式是首先填充一些期望覆盖RET返回地址的跳转地址,然后一堆Nop指令填充出“着陆区”,最后再是Shellcode。在溢出攻击之后,攻击数据将在RET区段即溢出了目标漏洞程序的小缓冲区,并覆盖了栈中的返回地址,然后跳转至Nop指令所构成的“着陆区”,并最终执行shellcode。
![]()
-
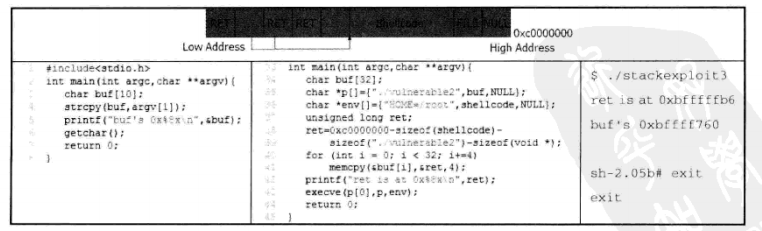
RS模式:
第三种Linux平台上的栈溢出攻击模式是RS模式,如下所示,在这种模式下能够精确地定位出Shellcode在目标漏洞程序进程空间中的起始地址,因此也就无须引入Nop空指令构建“着陆区”。这种模式是将Shellcode放置在目标漏洞程序执行时的环境变量中,由于环境变量是位于Linux进程空间的栈底位置,因而不会受到各种变量内存分配与对齐因素的影响,其位置是固定的,可以通过如下公式进行计算:ret=0x0000000-sizeof(void*)-sizeof(FILENAME)-sizeof(Shellcode)
![]()

1.3.2 Linuxd平台的Shellcode实现技术
-
Linux本地Shellcode实现机制
Linux系统本地Shellcode通常提供的功能就是为攻击者启动一个命令行Shell.
Shellcide的通用方法包含5个步骤:
① 先用高级编程语言,通常用C,来编写Shellcode程序;
② 编译并反汇编调试这个Shellcode程序:
③ 从汇编语言代码级别分析程序执行流程;
④ 整理生成的汇编代码,尽量减小它的体积并使它可注入,并可通过嵌入C语言进行运行测试和调试:
⑤ 提取汇编代码所对应的。pcode二进制指令,创建Shellcode指令数组。 -
Linux远程shellcode实现机制
Linux系统上的远程Shellcode的实现原理与本地Shellcode完全一致,也是通过执行一系列的系统调用来完成指定的功能实现方法步骤也是首先给出高级语言的功能代码实现,然后通过反汇编调试编译后的二进制程序,提取、优化和整理所获得的汇编代码,并最终产生opcode二进制指令代码.
1.4 Windows平台上的栈溢出与Shellcode
1.4.1 Windows平台栈溢出攻击技术
- Windows平台栈溢出攻击技术原理
Windows操作系统平台在很多方而与Linux操作系统具有显著不同的实现机制,而在这些差异中,与成功攻击应用程序中栈溢出漏洞密切相关的主要有如下三点。
(1)对程序运行过程中废弃栈的处理方式差异程序运行过程拥有大量的函数调用,而当一个函数调用完成返回至调用者,执行下一条指令之前,会有恢复栈基和栈顶指针的过程,同时一些操作系统对调用函数的废弃栈中的数据会进行一些处理,Windows平台会向废弃栈中写入一些随机的数据,而Linux则不进行任何的处理。这点差异导致了实施栈溢出攻击时,Windows平台中构建攻击缓冲区数据在栈中植入恶意指令时,会面临一些限制。
(2)进程内存空间的布局差异
Windows操作系统的进程内存空间布局与Linux存在着不同,Linux进程内存空间中栈底指针在OxcOOOOOOO之下,即一般栈中变量的位置都在OxbffT地址附近,在这些地址中没有空字节。Windows平台的栈位置处于OxOOFFFFFF以下的用戸内存空间,一般为0x0012地址附近,而这些内存地址的首字节均为0x00空字节。
(3)系统功能调用的实现方式差异
Windows平台上进行操作系统功能调用的实现方式较Linux也更加复杂,Linux系统中通过“int 80”中断处理来调用系统功能,而Windows系统则是通过操作系统中更为复杂的API及内核处理例程调用链来完成系统功能调用,对应用程序直接可见的是应用层中如Kemd32.dll、User32.dll等系统动态链接库中导出的一些系统API接口函数。
1.4.2 Windows平台Shellcode实现技术
- Windows本地Shellcode
在Windows平台上,典型的本地Shellcode同样也是启动一个命令行Shell,即"command.com"或"cmd.exe", Windows 32的系统API中提供了system。函数调用,可以用于启动指定程序或运行特定命令,在调用system(“command.com”)之后即可启动命令行程序。 - Windows远程Shellcode
与Linux系统类似,更为常用的Shellcode是可以在远程渗透攻击中使用的,能够给出shell网络访问的远程Shellcode.在Linux中,可以用dup2()复制标准I/O的文件句柄,然后执行(“/bin/sh” )即可,在Windows系统虽然原理是一样的。
1.5 堆溢出攻击
堆溢出(Heap Overflow)是缓冲区溢出中第二种类型的攻击方式,由于堆中的内存分配与管理机制较栈更为复杂,不同操作系统平台的实现机制都具有显著的差异,同时通过堆中的缓冲区溢出控制目标程序执行流程需要更精妙的构造,因此堆溢出攻击的难度较栈溢出要复杂很多,真正掌握、理解并运用堆溢出攻击也更为困难一些。
-
函数指针改写
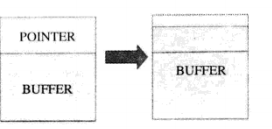
堆溢出进行函数指针改写攻击的示意如图所示,需要被溢出的缓冲区临近全局函数指针存储地址,且在其低地址方向。在符合这种变量布局的条件下,当向缓冲区填充数据时,如果没有边界判断和控制的话,那么缓冲区溢出之后就会自然地覆盖函数指针所在的内存区,从而改写函数指针的指向地址,攻击者只要能够将该函数指针指向恶意构造的Sellcode入口地址,在程序使用函数指针调用原先期望的函数时,就会转而执行Shellcode。
![]()
-
C++类对象虚函数表改写
C++类通过虚函数提供了一种Late binding运行过程绑定的机制,编译器为每个包含虚函数的类建立起虚函数表(viable)、存放虚函数的地址,并在每个类对象的内存区中放入一个指向虚函数表的指针,通常称为虚函数指针vptr。对于使用了虚函数机制的C++类,如果它的类成员变量中存在可被溢出的缓冲区,那么就可以进行堆溢出攻击,通过覆盖类对象的虚函数指针,使其指向--个特殊构造的虚函数表,从而转向执行攻击者恶意注入的指令。
1.6 缓冲区溢出攻击的防御技术
-
尝试杜绝溢出的防御技术
解决缓冲区溢出攻击最根本的办法是编写iE确的、不存在缓冲区溢出安全漏洞的软件代
码,但由于C/C++语言作为效率优先的语言,很容易就会出现缓冲区溢出。炒管花了很多时间使得具有安全意识和开发经验的程序员知道了如何编写安全的程序,怛具有安全漏洞的软件代码仍然大规模地出现,因此研究人员开发了一些T.具和技术来帮助经验不足的程序员编写安全正确的程序,包括一些高级的査销程序,如fault injection等,通过Fuzz注入测试来寻找代码的安全漏洞,还有一些分析工具用于侦测缓冲区溢出漏洞是否存在。虽然这些工具可以帮助程序员开发出更为安全的程序,但是由于C/C++语言的特点,这些工具也不可能找出所有的缓冲区溢出漏洞,因此并不能完全地消除缓冲区溢出攻击的可能性。 -
允许溢出但不让程序改变执行流程的防御技术
第二种防御技术允许溢出发生,但对可能影响到程序流程的关键数据结构实施严密的安全保护,不让程序改变其执行流程,从而阻断溢出攻击. -
无法让攻击代码执行的防御技术
第三种防御技术尝试解决冯•诺伊曼体系的本质缺陷,通过堆栈不可执行限制来防御缓冲区溢出攻击。
2.动手实践
未完待续。。。。
3.遇到的问题
未完待续。。。。
4.学习感悟、思考
未完待续。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号