安装Hadoop
本次作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
1.安装Linux,MySql
2.windows 与 虚拟机互传文件
3.安装Hadoop
还不能从windows复制文件的,可在虚拟机里用浏览器下载安装文件,课件:
提取文件:hadoop-2.7.1.tar.gz
链接: https://pan.baidu.com/s/1HIVd9JCZstWm0k7sAbXQCg
提取码: 2thj
1.安装Linux,MySql
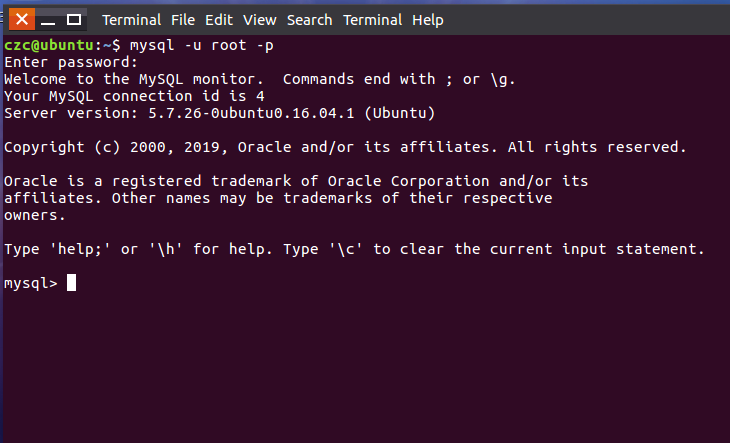
这里使用vmware workstation进行安装具体步骤见https://zhuanlan.zhihu.com/p/38797088
- 安装mysql成功

- mysql启动成功

- 测试数据库
2共享文件
安装 vmware tools
VMware下ubuntu与Windows实现文件共享的方法
.
在本机新建Share作为共享文件夹

在Vm虚拟机查看实现了文件共享

把Hadoop-2.7.1解压到/usr/local
3安装Hadoop
还不能从windows复制文件的,可在虚拟机里用浏览器下载安装文件,课件:
提取文件:hadoop-2.7.1.tar.gz
链接: https://pan.baidu.com/s/1HIVd9JCZstWm0k7sAbXQCg
提取码: 2thj
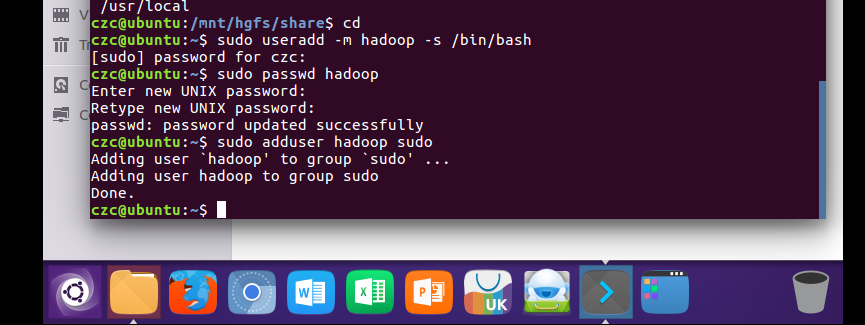
创建hadoop用户首先打开ctrl+alt+t打开终端窗口,输入如下命令创建新用户
退出并用Hadoop登录

更新apt
安装SSH、配置SSH无密码登陆
Ubuntu默认已安装SSH client,此外还需要安装SSH server
安装后,使用ssh localhost按提示操作可以登录本机

为了方便设置无密码登录
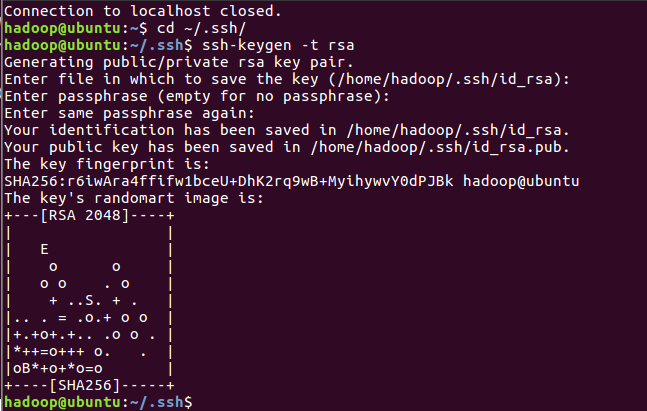
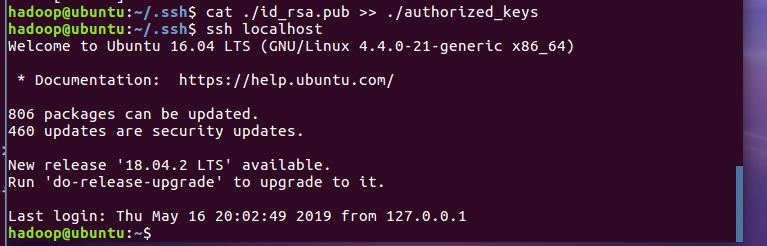
再次登录就可以无密码了

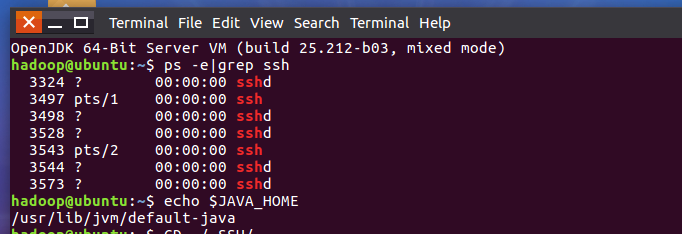
查看是否安装成功

安装java环境
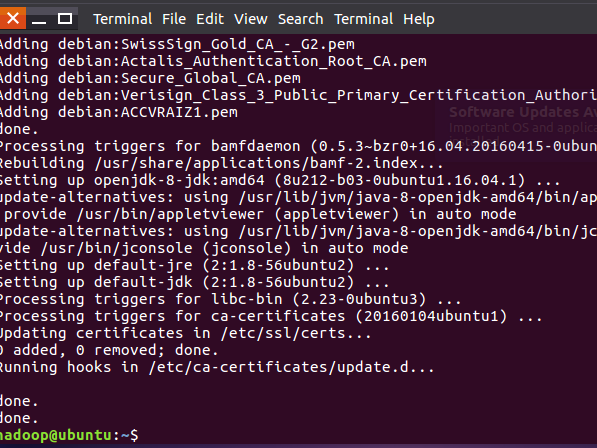
安装成功
使用命令 gedit ~/.bashrc 配置环境变量文件.bashrc
注意:gedit提示找不到文件的话
sudo apt-get update
sudo apt-get install gedit-gmate
sudo apt-get install gedit-plugins
sudo apt-get remove gedit
sudo apt-get install gedit

3.配置Java的环境变量,在文件最前面或最后面添加如下一行(等号前后不能有空格),然后保存退出

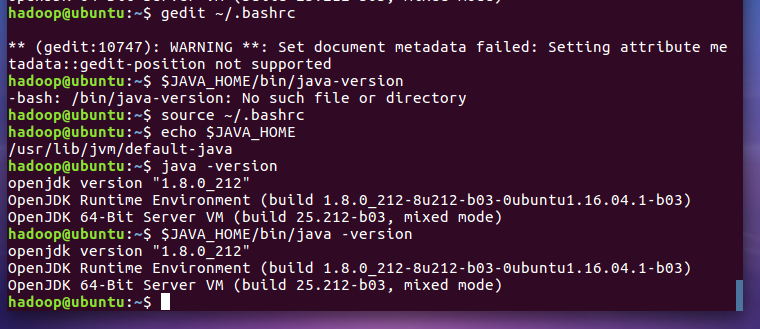
执行source ~/.bashrc让环境变量立即生效。然后检验是否设置正确 java环境安装成功
伪分布式配置
hadoop安装云盘下载地址:验证码:2thj
通过win文件共享下载的hadoop安装包到虚拟机中,若文件共享不成功,可以在Ubuntu系统中下载。倘若在Ubuntu系统无法使用云盘下载,可在win系统下载完后发到qq邮箱,然后再Ubuntu系统中登录qq邮箱,然后在下载。
进行前先确认hadoop可用
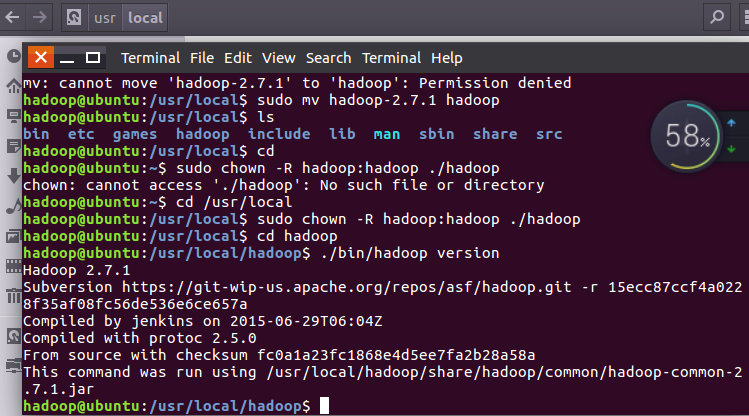
修改共享的hadoop文件名 修改文件夹权限 检查hadoop是否可用
Hadoop生态的配置
我的博客https://www.cnblogs.com/MissDu/p/8831525.html
复制配置文件代码。
运行Hadoop单机模式的例子

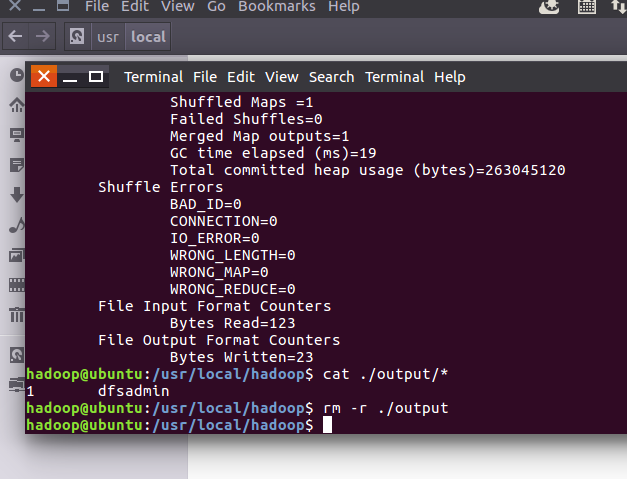
运行成功后查看
Hadoop默认不会覆盖结果文件,再次运行上面实例会提示错误,需要现将 ./output 删除
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式.
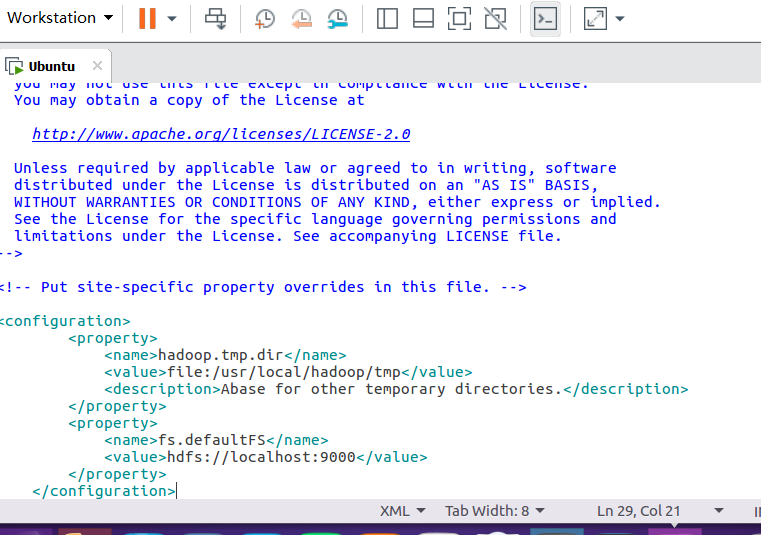
修改配置文件 core-site.xml:
通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml

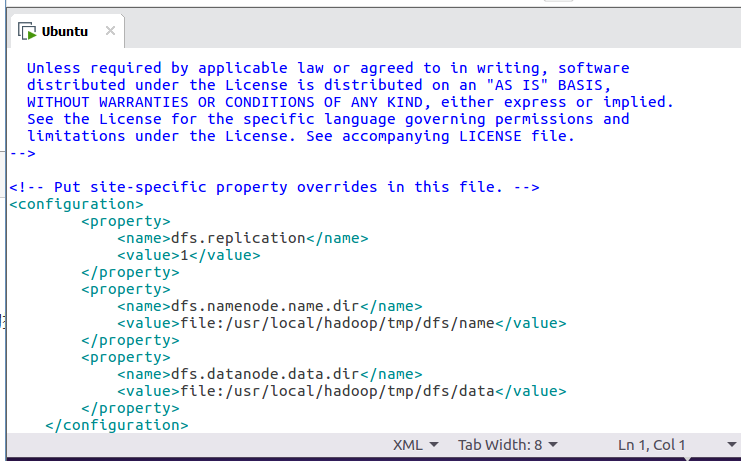
修改配置文件 hdfs-site.xml:
gedit ./etc/hadoop/hdfs-site.xml
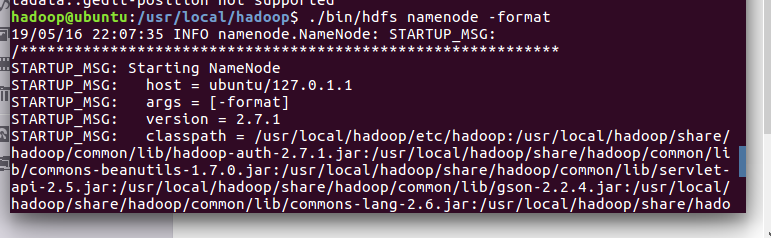
文件配置完成后,执行 NameNode 的格式化
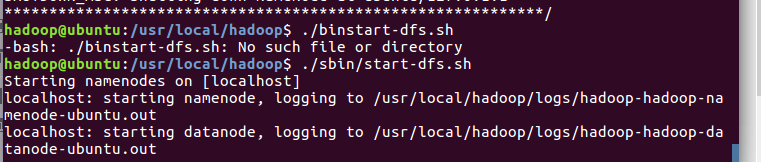
开启NameNode和DataNode
通过jps命令判断是否成功

运行Hadoop伪分布式实例
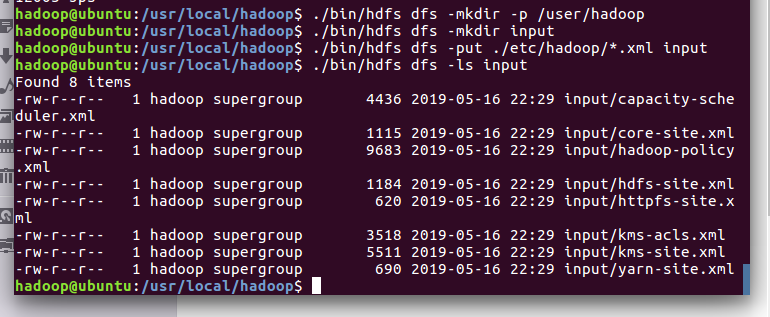
1.在 HDFS 中创建用户目录
2.创建目录 input,其对应的绝对路径就是 /user/hadoop/input
3.将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中
4.查看文件列表
5.伪分布式运行 MapReduce 作业
运行
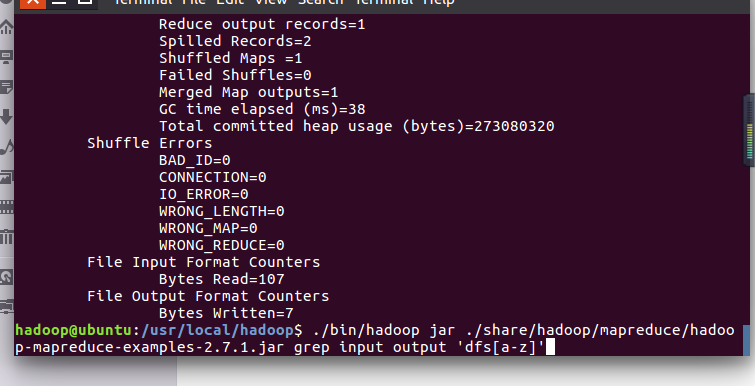
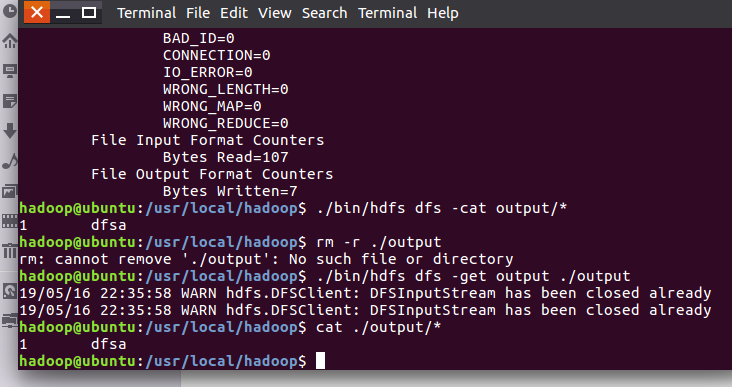
.查看位于HDFS中的输出结果并取回本地
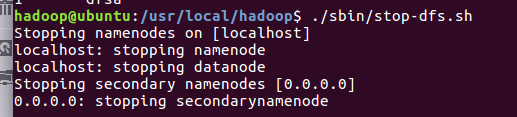
关闭hadoop
注意
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 开启 NameNode 和 DataNode 守护进程就可以


 浙公网安备 33010602011771号
浙公网安备 33010602011771号