
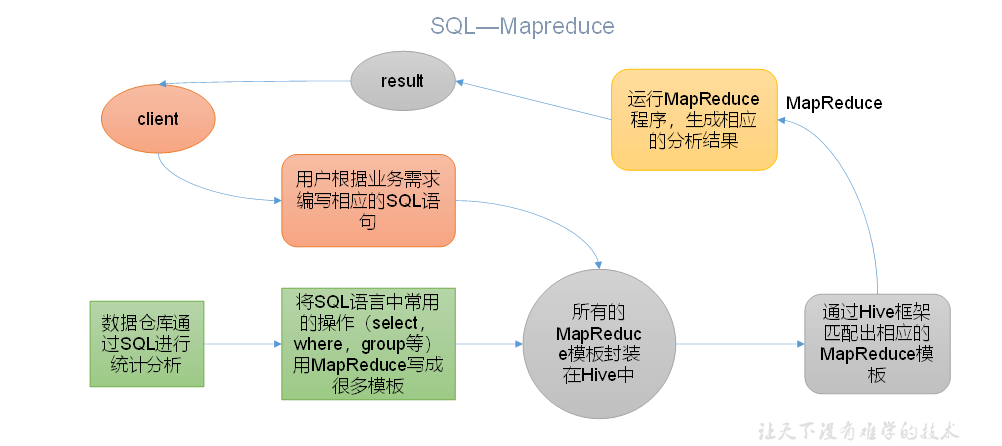
HIVE
本质: 将HQL转化成MapReduce程序
-
Hive处理的数据存储在HDFS
-
Hive分析数据底层的实现是MapReduce
-
执行程序在Yarn上
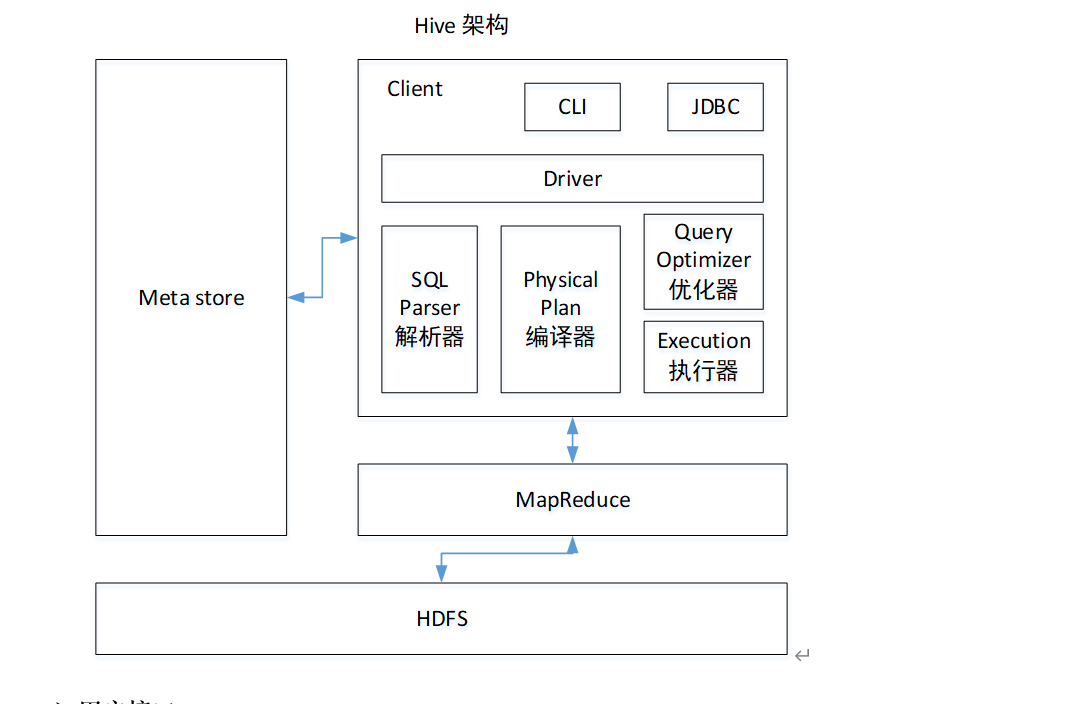
Hive架构原理
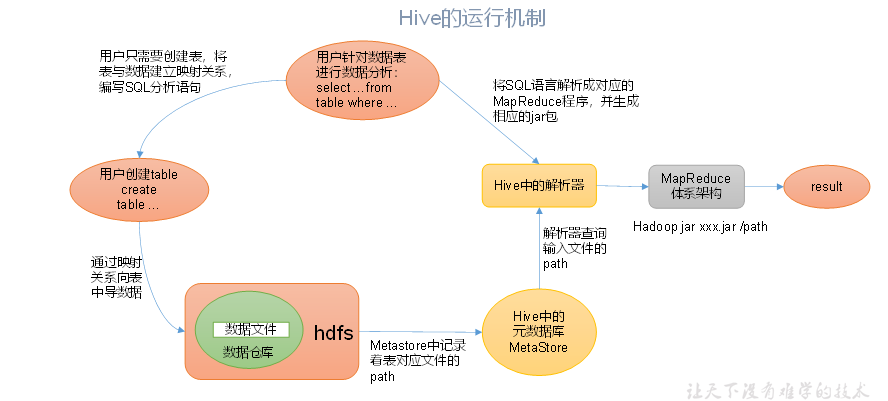
运行机制
HiveJDBC访问
1.启动beeline客户端:beeline -u jdbc:hive2://hadoop102:10000 -n sun
2."-e"不进入hive的交互窗口执行sql
3.退出hive的窗口:exit 先隐形提交数据,在退出。 quit:不提交数据,退出。
4.在hive的cli命令窗口查看hdfs文件系统 dfs -ls /
5.查看.hivehistory文件 cat .hivehistory
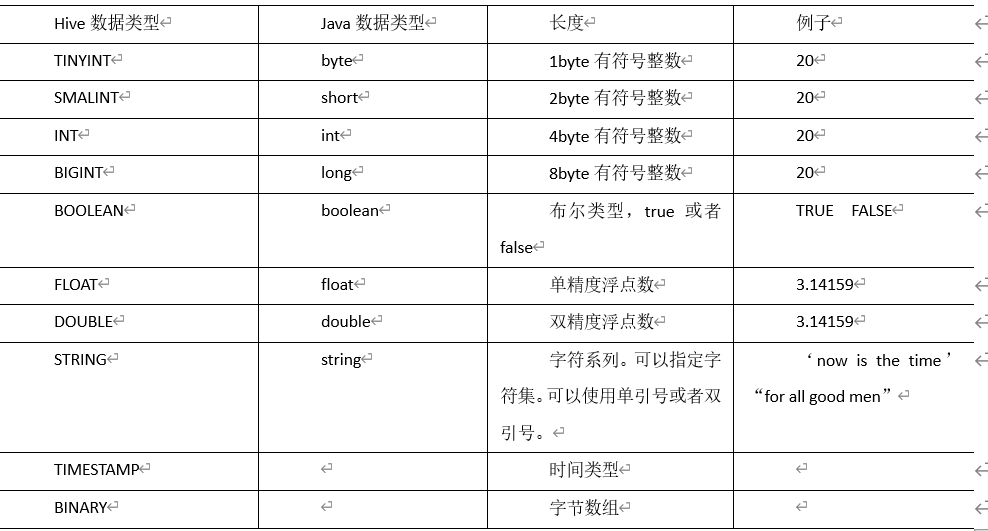
Hive的基本数据类型
集合数据类型
Hive有三种复杂数据类型ARRAY、MAP 和STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
类型转化
1)隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
2)可以使用CAST操作显示进行数据类型转换
例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
DDL数据定义
创键数据库:
CREATE DATABASE [IF NOT EXISTS] database_name //创键数据数如果不存在
[COMMENT database_comment] //对数据库的描述
[LOCATION hdfs_path] // 数据库存放的位置
[WITH DBPROPERTIES (property_name=property_value, ...)];
查询数据库:
-
显示数据库:show databases;
-
过滤显示查询的数据库 show databases like 'db_name'
-
显示数据库信息:desc database db_hive
-
显示数据库详细信息 desc database extended db_name
-
切换当前数据库 use 'db_name'
修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
alter database db_name set dbproperties('')
删除数据库
-
删除空数据库 drop database if exists db_name;
-
如果数据库不为空,可以采用cascade命令,强制删除
drop database db_name cascade
创建表
1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
2.字段说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY创建分区表
(5)CLUSTERED BY创建分桶表
(6)SORTED BY不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称, hive使用Serde进行行对象的序列与反序列化。
(8)STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在HDFS上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE允许用户复制现有的表结构,但是不复制数据。
管理表
-
默认创建的表都是管理表又称为内部表,当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
外部表
-
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉
2. 创建外部表 create external table t_name();
-
查看表格式化数据 desc formatted dept;
管理表与外部表的互相转换
-
修改内部表student2为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');修改外部表student2为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
修改表
-
重名明表
ALTER TABLE table_name RENAME TO new_table_name-
更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]-
增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
-
DML数据操作
数据导入
-
向表中装载数据(Load)
load data [local] inpath
'/opt/module/datas/student.txt' [overwrite] into table student [partition
(partcol1=val1,…)];-
load data:表示加载数据
-
local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
-
inpath:表示加载数据的路径
-
overwrite:表示覆盖表中已有数据,否则表示追加
-
into table:表示加载到哪张表
-
student:表示具体的表
-
partition:表示上传到指定分区
-
通过查询语句向表中插入数据(Insert)
-
创建一张分区表
create table student_par(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t'; -
基本插入数据
insert into table student_par partition(month='201709') values(1,'wangwu'),(2,'zhaoliu'); -
基本模式插入(根据单张表查询结果)
insert overwrite table student partition(month='201708')
select id, name from student where month='201709';
[注意]insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表或分区中已存在的数据
注意:insert不支持插入部分字段
-
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
-
创建表时通过Location指定加载数据路径
create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student;
-
Import数据到指定Hive表中
<!--注意:先用export导出后,再将数据导入。-->
import table student2 partition(month='201709') from
'/user/hive/warehouse/export/student';
-
数据导出
-
Insert导出
-
将查询的结果导出到本地
insert overwrite local directory '/opt/module/datas/export/student'
select * from student;
-
将查询的结果格式化导出到本地
insert overwrite local directory '/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;
-
将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/user/atguigu/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
-
Export导出到HDFS上
export table default.student to
'/user/hive/warehouse/export/student';
<!--export和import主要用于两个Hadoop平台集群之间Hive表迁移。-->
-
清除表中数据(Truncate)
<!--runcate只能删除管理表,不能删除外部表中数据-->
truncate table student; -
查询
基本查询
查询语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
-
算数运算符
运算符 描述 A+B A和B 相加 A-B A减去B A*B A和B 相乘 A/B A除以B A%B A对B取余 A&B A和B按位取与 A|B A和B按位取或 A^B A和B按位取异或 ~A A按位取反 -
常用函数
COUNT() 个数 MAX() 最大值 MIN() 最小值 SUM() 累加 AVG() 平均值 -
Limit语句,LIMIT子句用于限制返回的行数。
-
使用WHERE子句,将不满足条件的行过滤掉,WHERE子句紧随FROM子句
-
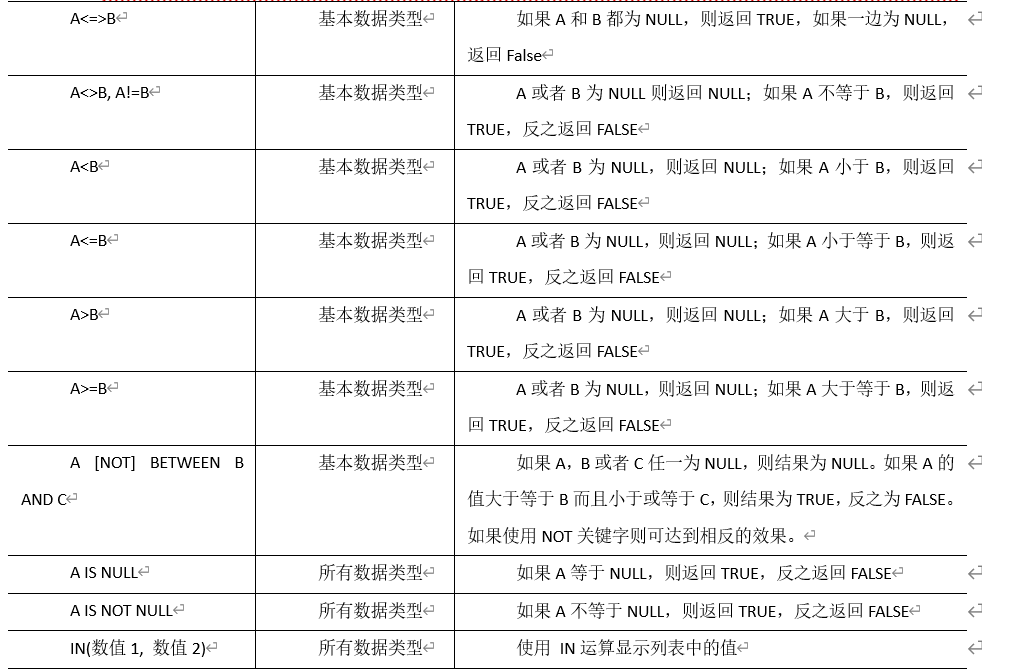
比较运算符(Between/In/ Is Null)
![]()
![]()
![]()
-
Like和RLike
like :选择条件可以包含字符或数字:% 代表零个或多个字符(任意个字符)。_ 代表一个字符。RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
-
逻辑运算符(And/Or/Not)
操作符 含义 AND 逻辑并 OR 逻辑或 NOT 逻辑否 -


分组
-
Group By语句:GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作
-
Having语句
having只用于groupby分组统计语句。
Join
等值Join,内连接,左外连接,右外连接,满外连接,多表连接
排序
1全局排序(order by)
ASC:升序,DESC:降序
2每个MapReduce内部排序(Sort By)
Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序
3分区排序(Distribute By)
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用。 对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
4 Cluster By
当distribute by和sortsby字段相同时,可以使用cluster by方式,但是排序只能是升序排序,不能指定排序规则为ASC或者DESC
抽样查询
x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
函数
1. 系统内置函数
查看系统自带的函数:show functions
显示自带的函数用法:desc function upper
详细显示自带的函数的用法:desc function extended upper
2. 常用内置函数
-
空字段赋值:NVL:给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
-
CASE WHEN
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id; -
行转列
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
-
列转行
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlia
3. 窗口函数
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随 着行的变而变化。
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
日期相关:
current_date返回当前日期
date_add,date_sub 日期的加减
两个日期之间的日期差:datediff()
4.自定义函数
根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚合函数,多进一出 类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如lateral view explore()
压缩和存储
-
开启Map输出阶段压缩
-
开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true; -
开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true; -
设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
-
-
开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
-
开启hive最终输出数据压缩功能
set hive.exec.compress.output=true; -
开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true; -
set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
-
-
列式存储和行式存储(Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET)
-
行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
-
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
-
分区和分桶表
分区表:
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
-
创建分区表:
hive (default)> create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
-
加载数据到分区表中
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201709');
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201708');
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201707');
-
增加分区
alter table dept_partition add partition(month='201705') partition(month='201704'); -
删除分区
alter table dept_partition drop partition (month='201705'), partition (month='201706'); -
查看分区表有多少分区
show partitions dept_partition; -
查看分区表结构
desc formatted dept_partition;
分桶表:
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分区针对的是数据的存储路径;分桶针对的是数据文件。
-
创建分桶表
-
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中
优化
-
Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算,在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
-
小表、大表Join

 浙公网安备 33010602011771号
浙公网安备 33010602011771号