04.Spark的核心组件
Spark核心组件
1. RDD
1.1.变换(transformation): map() flatMap(压扁) filter()(过滤) reduceByKey
1.2.动作(action): collect() save()(保存) reduce() count()(计算个数)
[reduce源码]
reduce(f:((String,List[(String,Int)])),(String,List[String,Int]))=>(String,List[(String,Int)]).....
def reduce(f:(T,T)=>T):T=wotjScpe //聚合的结果是T,不是RDD。它是典型的一个动作。
RDD的概念
resilient distributed dataset,弹性分布式数据集。每一个RDD都有个数问题。都可以用 count() ,count()的返回值是Long,Long就是一个action动作。rdd是延迟计算,延迟到你调用它的action()方法的时候。才去计算。
rdd1:就是普通的每一行元素。
res15:org.apache.spark.rdd.RDD[String]=/user/centos/data/tags.txt MapPartitionsRDD[1]at textFile at <console>:24
rdd4:就是把空值过滤掉。
rdd4.map() //它每一个之都是元组。
假如它想取出商家ID,商家是510的记录
scala> val rddd=rdd4.map(t=>t._1.equals("86913510")) //它没有执行,它只是产生一个动作。equals是变换,变换成了真假
scala> val rddd=rdd4.map(t=>t._1.filter("86913510")) //filter 过滤
rdd.collec().foreach()和rdd.foreach()的区别?
rdd:是分布式数据集是在很多节点上的数据组合而成的。rdd是逻辑上的,是虚的。而实的东西就是分区。在hadopp在MR作业的时候,在M和R之前是InputFormat,中间的是RecordReader。
InputFormat是干什么的? getSplits是负责计算切片的,同时还要帮我们创建记录的阅读器。Map是要记录阅读器的下一个方法,判断有没有下一个。有的话就读取一行(next()方法)RecordReader就是要读取每一行的,文件输入格式默认是以行首的偏移量做Key,以整行文本做Value.这是文件输入格式。文本格式它继承了文件输入格式。用的是同样的手段。map的个数是由getSplits(切片个数)决定的,切了几片它就有几个map.这个map是由物理计算。逻辑运行,因为它有整行,所以有些map是空段的,但是个数不能少。Reduce是由自己设定的。RDD是一个非常宏观的虚的东西,逻辑上整个集群有几百台上千台,而我这个RDD是跨在所有的节点上算的集合,那每一个节点上跑的是数据它就是分区。所以一个RDD里面它一定会有分区列表。而这个分区列表就等价于Hadoop里面的getSplits(切片),getSplits在Spark里面就等价于分区。那么现在有多少个分区,它其实就是有多个map,RDD叫弹性分布式分布式数据集。它是一个Spark基本抽象,它代表一个 immutable 不可变集合,分区化的元素集合,它可以并行进行操作。这个类包含了基本的操作,在所有的RDD都有的。比如 :map,filter(过滤),persist(持久化)。 PairRDDFunctions:各种ByKey是针对来说的。RDD里面是没有各种ByKey的方法。但是我们在变换的过程中发现是有ByKey的方法的,有些是没有的。为什么会这样?就是因为一旦你变成了key-value对,它这个RDD就会自动转换成(隐式转换)PairRDDFunctions。该类提供了所有的ByKey操作。key-value是对偶 (二元组,特殊的元组),在Spark里面就变成了ByKey操作了。
对于PariRDDFunctions的RDD它还包含了key-value的操作。比如一些groupByKey和join.除此之外还包含了这些DoubleRDDFunctions,SequenceFileRDDFunctions.
PariRDDFunctions(org...spark.rdd) class PariRDDFunctions[K,V](sekf:RDD[(K,V)]) //PariRDDFunctions它本身就是一个类,它构造里面就有一个RDD,它扩展Logging东西 像这样的一个类它都是带ByKey的。而我们在转换RDD变换过程期间,如果它符合Key-Value的方式.那它就直接默认转换成PariRDDFunctions这个类了。所以它就有ByKey这些方法了。 (implicit kt:ClassTag[K],vt:ClassTag[V],ord:Ordering[K]=null) extends Logging with Serializable{...}RDD的概念:resilient distributed dataset,它是一个弹性分布式数据集,它是不可变分布集合。它可以进行并操作的分区化数据集合。因为Sspark集群它是分布式的,它 有很多节点。而我们这个数据是跑在Spark上的,所以这些节点上的 数据合在一起就是一个RDD。RDD在变换过程期间,它会产生一个新的RDD,它的行为就是transformation。不可变集合,可以进行并行操作的分区化数据集合。该类包含了RDD常见操作,
内部每个RDD它都有5个主要属性:
1.分区列表 :
2.计算每个切片的计算函数:
所以RDD在变换的过程期间它传的是函数,那些函数其实就是算法。就是在这个RDD对每个元素进行一个怎样的运算。
3.和其他RDD的依赖列表:
上一个RDD进行变换,上一个也是另外一个变换而来的。这样来就成了一个依赖。而每一个RDD的产生都是通过算法得到的。对上一个RDD产生一个算法,产生一个新的RDD。RDD本身是不可变的。
第一个RDD是sc.textFile()加载文件它产生了一个新的RDD1,RDD1经过压扁flatMap(_.split())产生了一个新的RDD2.表一成对后map()它就成了RDD3.再按Key聚合reduceByKey(变换后)就变成了RDD4.到RDD4后就根本没执行过。只是把变换的过程,这个链条形成了。如果真要执行这个链条就要从collect出发,collect之后就不再是RDD了,已经返List或Array了。它已经不带RDD了。这就是一个RDD的过程。有上下级关系。RDD1到RDD4速度非常快因为它不计算,它只再List中计算。4.针对kv类型RDD,还有一个分区类(可选):
分区,针对Key-value类型的RDD。比方说Hash-partitionned(hash分区),如果部署Key-value类型的RDD它就没有这个。分区类在数据倾斜中用的比较多。partitionnerd在干什么用到分区?数据倾斜用到分区的比较多。数据倾斜产生分区不是因为大量数据拥上一个节点或几个节点上...为可解决它可以从新定义key,从新定义key 有一个弊端。就是无故增加网络的负载。在Key后面加随机数,key会随网络间的Shuffer分发,所以它会增加网络的负载。那么可以采用随机分区,那么一随机分区key没有增加。但是分发的节点不一样。所以需要二次作业。在Spark中也遇到过这种问题。也是使用分区类,分区是跟RDD关联的。这种RDD它就是key-value类型的RDD。它叫RDD
5.计算每个切片的首选位置列表(可选):
优先在那个点上计算切片,Spark算的是Hadoop上的文件。数据在那个点,应该优先在数据所在的那个节点去启动它的作业。这就是它的首先位置列表。涉及到block(块位置),HDFS(文件)
RDD是轻量级的,RDD里面是不带数据的。它 只带了一个分区列表。真带数据的话它就是一个List,Array
abstract class RDD[T:ClassTag] //抽象类,它有多个实现 RDD是轻量级的,是不严谨的。因为我们在通过文本文件。方法加载的出来的RDD,它里面就有分区。除了这种方式之外,产生RDD之外,还有别的方式能产生RDD。在sc.方法中有一个parallelize方法, scala> sc.parallelize //parallelize是并行 //numSlices:切片 def parallelize[T](seq:Seq[T],numSlices:Int)(implicit evidence$1: //seq给的是序列:是集合,List是序列的一种。除了List之外还有其它的序列比方说栈。序列其实就是一连串的元素成线性排序的。Set和map它不是序列,因为它可能是Hash的闪列的。二叉树也不是序列。针对不同的实现它的存储方式可能不一样,可能先进先出的,可能先进后出的,有的是递链方式,有的是链表方式有的是数组方式。但总之它们都市线性排列的。 scala.reflect.ClassTag[T]):org,apache.spark.rdd.RDD[T] //举例:通过这种方式可以得到一个RDD scala>val rdd1=sc.parallelize(1 to 10)//返回的是Range对象。 rdd1:org.apache.spark.rdd.RDD[Int]=ParallelCollectionRDD[28]at parallelize at<console>:24 //ParallelCollectionRDD:它并行集合RDD,这个就不是轻量级的了。它里面带数据。 scala> rdd1.collect res22:Array[Int]=Array(1,2,3,4,5,6,7,8,9,10) scala> ParallelCollectionRDD这个是重量级的。 [ParallelCollectionRDD源码]ParallelCollectionRDD(org...spark.rdd)它是并行集合rdd private[spark]class ParalleCollectionRDD[T:ClassTag]{ sc:SparkContext; @transient private val data:Seq[T] //它里面确实是带数据的 numSlices:Int, locationPrefs:Map[Int,Seq[String]] extends RDD[T](sc,Nil) } textFile返回的是:从hdfs中读取文件,从本地文件系统上或者是任何支持hadoop系统的文件都可以读取。它返回的是一个字符串的RDD textFile源码 //这是参数 def textFile{ path:String, //minPartitons:Int=defaultMinPartitions:这个是默认值。参数的默认值。defaultMinPartitions,默认的最小分区数它是一个函数,这是一个参数的默认值 withSope:它是一个函数它是用{来调用参数的 minPartitons:Int=defaultMinPartitions:RDD[String]=withSope{ //这是定义函数 assertNotStopped() //加载文件它用的是hadoopFile,它传的就是path="file:///d:/temptags.txt" //TextInputFormat文本输入格式:用的还是hadoop读取文件的格式方法。没有变 //LongWritable:就是Key类型 //classOf:vuale就是文本 hadoopFile(pat,classOf[TextInputFormat],classOf[LongWritable],classOf[Text], minPartitions).map(pair=>pair_2.toString).setName(path) } } //defaultParellelism默认的并发度,它也是一个函数。 def defaultMinPartitions:Int=math.min(defaultParellelism,2) def defaultParellelism:Int={ assertNotStopped() taskScheduler.defaultParallelism } 在Scala里面成员变量和成员函数没有区别,表明上是成员字段其实它是函数。它们之间就是函数调函数的关系。 [withSope源码] //withSope它调的是它的Staic方法 body:=>U):这个参数是方法签名它传的函数是一个参数,这个函数没有参数 private[spark]def withSope[U](body:=>U):U=RDDOperationScope.withSope[U](this)(body) [hadoopFile的源码] def hadoopFile[K,V]( path:String, inputFormatClass:Class[_<:InputFormat[[K,V]], keyClass:Class[K], valueClass:Class[V], //hadoopFile的返回值也是rdd,它new的是 HadoopRDD minPartitions:Int=defaultMinPartitions):RDD[(K,V)]=withScope{ assertNotStopped() ....... new HadoopRDD( this, confBroadcast, Some(setInputPathsFunc),//输入格式类 inputFormatClass, keyClass, //key类型 valueClass, //vaLue类型 minPartitions).setName(path) //最小分区数 设了一个名称 ) } ) textFile最初产生的是hadoopRDD,该类提供了读取hdfs文件的核心功能。map是RDD的方法, [map源码] def map[U:ClassTag](f:T=>U):RDD[U]=whithScope{ val cleanF=sc.clean(f) //在它变换的时候又产生了MapPartionsRDD new MapPartionsRDD[U,T](this,(context,pid,iter)=>iter.map(cleanf)) } MapPartionsRDD:它会因为提供了函数给每个分区。你在做变换的时候提供了一个函数,它就会对每一个父RDD的分区来应一行。所以MapPartionsRDD分区RDD加载文件的方法。首先它创建了一个hadoopRDD,它里面是带分区的。这个东西经过了map变换,而map变换又产生了新的rdd叫做MapPartionsRDD(map分区RDD)。它带有一个函数func,它是用在每一个分区上的。它对每一个分区都应用这个函数。HadoopRDD是有分区列表的。MapPartionsRDD也是有分区列表的,HadoopRDD和MapPartionsRDD的分区列表一样多? 如果是map的话它们就一样多。但是变换transformation如果是有分为两种,要shuffer和不要shuffer的。MR之间是要混洗的,而我们变换的话是从一个rdd变换完以后。产生一个新的RDD它就叫变换。但是它有可能是Shuffer,也有可能不是Shuffer。这里就存在一个问题宽依赖和窄依赖的问题。 ```Dependency
textFile(文本加载)产生RDD的Rose图,它产生了两个RDD,Hadoop,和MapPartionsRDD
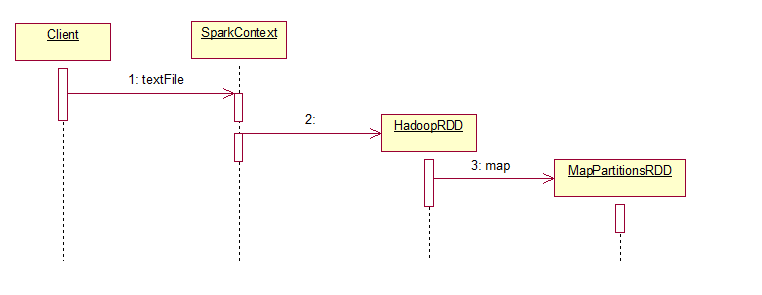
2.Dependency
什么是依赖?
它指的是RDD的每个分区它跟父RDD的分区数量上的对应的关系。依赖决定分区它的
//对于抽象的依赖Dependency来件它有NarrowDependency(org.apach.spark)...窄依赖
abstract class Dependency[T]extends Serializable{
def rdd: RDD[T]
}

2.1.窄依赖
窄依赖(NarrowDep):子RDD的每个分区它依赖于少量的父RDD分区这就叫做窄依赖。少量是多少?只要不全依赖于每个分区它就是窄依赖。rdd4(子RDD)与rdd3(父RDD)的每个分区都一一对应的,叫做窄依赖(一对一依赖)。
NarrowDep 分为:One2OneDep,RangeDep 范围依赖,pruneDep在窄依赖中上一个分区和下一个分区是否相同?窄依赖是不经过Shuffer的,分区数只能越取越少,窄依赖依赖于少量的.
2.2.宽依赖
宽依赖(ShuffleDep):就是你这个分区的数据可能来自上一个RDD的所有分区。
ReduceByKey:按Key聚合。ReduceByKey一定是宽依赖,一定是ShuffleDep依赖。因为它需要混洗,
RDD3里面有很多分区,假如有3个分区对应的是3个分区或3个切片,有可能是3个文件。这个RDD它经过了ReduceByKey它产生了一个新的rdd,reduceByKey它是要经过混洗的Shuffer,是按key来聚合。rdd3的数据都有可能进入到rdd4的这个分区内。子RDD它的每个分区都依赖于父RDD的所有分区。这就是Shuffle依赖。rdd4的数据来自于上面的数据。
RDD3分区的数据都有可能进入到RDD4中,RDD4(子RDD)它的每一个分区依赖于RDD3(父RDD)的所有分区。这就是ShufflerDep依赖。
.任务有多少个?有多少个分区它就有多少个任务。而每一任务它运行在一个节点上。所以RDD是虚的,分区是实的。分区是切片,切片所对应的分区在那个点上运行,它就在那个运行。
它运行的时候是以任务来跑的,阶段也是虚的。阶段与RDD之间的关系?一个阶段包含多个RDD。任务和RDD之间包含的关系是什么?一个RDD包含多个任务。 一个RDD包含多个分区,每个分区它对应着一个切片,每一切片它允许在一个点上。运行到一个点上它是以任务来运行的。RDD它和阶段的关系是 Stage1和Stage2它们之间跨多个RDD,它们直接按的界限规定就是看它需不需要Shuffer.而任务又不一样了。任务是一个阶段包含多个任务,而每个任务它都包含一整条的RDD变换的过程。Stage1为什么分为一个阶段?就是因为它不需要Shuffer,在计算过程期间。在这一个点上就可以跑。而你的RDD经过左变换右过滤再压扁等它最终还是一个处理的流程。而这些流程在一起就是任务需要干的事情。所以任务就是整要干的事情包在一起。由于一个阶段包含了很多任务,计算每一阶段都包含一堆的任务。这些任务可以并行计算,每一个任务它都对应到一个分区上。任务是横向的计算流程,rdd的一系列计算它都是对应着任务的运算过程。123三个RDD这三个分区数相同吗?不一定,分区数不同该如何去界定任务?从第三阶段的最后的一个RDD的每个分区出发,这个RDD有多少个分区它就有多少任务。而每个RDD它都有上级的依赖列表,所以它会顺着这个依赖列表去往上找。一直找到它的根,凡是这个分区所依赖的整个链条,全在这个任务的执行范围中。
[Stage源码]Stage(org.apache.spark.scheduler)

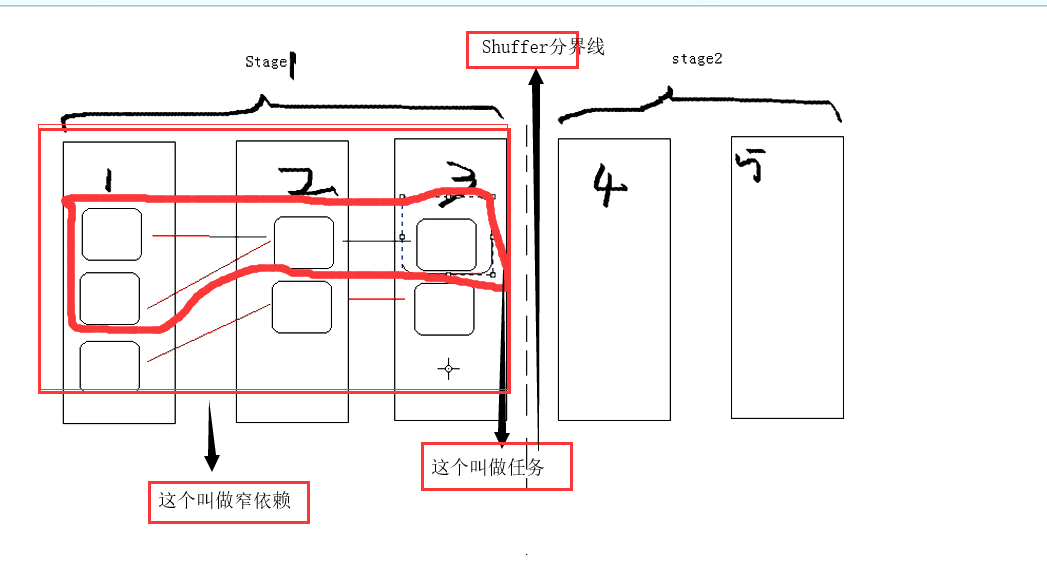
它是并行任务集,一个阶段包含多个任务。所有的任务它有同一个阶段,有同样的一个Shuffer依赖。阶段划分以后才有了任务,rdd决定了阶段。阶段出来了以后决定了任务。同一阶段(Stage)的所有任务它有着相同的依赖。任务的每一个DAG都是由调度器来运行,它被切割成阶段。以发生Shuffer的地方为边界。DAG会运行这个阶段,按序排。阶段的话是以上一个阶段的输出以下一个阶段的输入。在最后的一个结果阶段中,结果之前的都叫做Shuffermap阶段。所以对与阶段来讲,阶段类型有两种,ShuffleMapStage和ResultStage(结果)
ShuffleMapStage:它任务的计算结果要做为其它阶段的输入。阶段是任务的集合。
ResultStage:结果阶段它的任务就是直接计算一个Spark action(count(),Save())运行一个函数。也可以这样说直接执行rddd action操作。
ShuffleMapStage需要跟踪这个节点(每一个分区它所在的节点),为什么?因为它要经过Shuffer从那个点抓数据。每一节点它都有一个firstJobId(第一个作业),区分第一个提交的作业。它使用的是先进先出的策略(FIFO)。它允许先提交先运算。多次失败后它会进行重试的机制。
//阶段和RDD是什么关系?阶段是跟RDD关联的 下面这个是主构造
private [scheduler]abstract class Stage( //抽象类,
val id:Int,
val rdd: RDD[_],//这是泛型
val numTasks:Int,
val parents:List[Stage],
val firstJobId:Int
val callSize:CallSite)
extends Logging{
}
)
有那么对阶段(Stage),有那么多RDD它关联到的是那一个。在创建阶段的时候,是要给它传一个主构造的参数rdd的,它关联的rdd是最后一个rdd.所以从阶段上是可以访问到rdd的。
ShuffleMapStage extends Stage
ShuffleMapStage它是任务执行过程间的一个中间过程,在DAG执行过程的中间过程。当它执行的时候它会保存map输出文件,供下一个reduce任务的抓取(fetch)。ShuffleMapStage也可以单独提交用这个DAGScheduler.submitMapStage这个函数。
ResultStage(结果阶段)
它是一个结果阶段它是应用到一个函数,给某些分区。并不是所有的action是要针对所有的分区来操作(应用),比如说count()取前几个那就没有必要取所有的分区来进行计算。
Task(任务)
[Task]ShuffleMapTask(org.apache.spark.scheduler)
private[spark]class ShuffleMapTask() //它的超类就是Task
private[spark]abstract class Task[T]()//它的超类就是 Serializable(串行化)
任务它是执行单元,最小的执行单位。它有两种类型,
ShuffleMapTask:在ShuffleMapStage由多个ShuffleMapTask组成。
ResultTask:它是由多个结果任务构成的。
Sparkjob是由一个或多个Stage(阶段)构成的,在作业中的最后一个阶段,它由多个结果任务构成。ResultTask(结果任务)它执行任务,并且发生这个任务的结果回传driver。
job
job是什么?一个动作就是一个job.一个action就是一个job.
Application(应用)
一个应用可以包含多个job.可以执行多次action.
Driver
在写Spark应用的时候,要由main()函数。它得有入口点,main()所在的类。它所运行的节点,就是Dirver节点。比如第一步需要创建上下文,创建了sc,再通过sctextFile()加载文件。sc再做各种变换,rdd的各种变换都是延迟计算的。只有再调rdd的ation()方法collec()的时候,它才真正执行。这一大过程一定是在一个节点上跑,如果按现在的模式它一定跑在s101上,运行着一些用的是spark-submit --class xxx.jar 带参数xxx.那么此刻s101就是Driver.
那个点上提交应用它就是Driver吗?不一定,因为它跟deploy-mode:有关。deploy-mode它有两种模式一种是client,一种是cluster(集群)。
Dirver举列:集群有4个节点,S101为master节点。S102为worker节点,S103为worker节点,S104为worker节点.再有一个集群S105,它不是Spark集群内的节点。S105它即不是Master也不是worker,但是在S105上安装了Spark的包,只要安装了Spark的包就可以执行Spark的命令。spark-submit --master S101:7077 需要指定master.,那么程序就要部到S105上,启动的时候就直接启动S101:7077,那么S105就是Driver。因为客户端是跑在S105上的。它跟集群每一关系。它是一个驱动程序一个入口点。但是如果S105想要运行可以加 --deploy-mode cluster当你在提交这个应用的时候。这个S105就不是Dirver了。因为master会在其中的一个worker节点上来分配这个程序去执行。当你看到输出的一大堆,都是想Dirver回传的信息。包括client,一client那些点都把它收到的数据回传给Dirver端。然后将它打印出来了。用S105去提交作业,它真正的Dirver跑到Worker的某个点上了。这样就根本看不到它的执行过程了。
job
job是什么?一个动作就是一个job.一个action就是一个job.
Application(应用)
一个应用可以包含多个job.可以执行多次action.
Driver
在写Spark应用的时候,要由main()函数。它得有入口点,main()所在的类。它所运行的节点,就是Dirver节点。比如第一步需要创建上下文,创建了sc,再通过sctextFile()加载文件。sc再做各种变换,rdd的各种变换都是延迟计算的。只有再调rdd的ation()方法collec()的时候,它才真正执行。这一大过程一定是在一个节点上跑,如果按现在的模式它一定跑在s101上,运行着一些用的是spark-submit --class xxx.jar 带参数xxx.那么此刻s101就是Driver.
那个点上提交应用它就是Driver吗?不一定,因为它跟deploy-mode:有关。deploy-mode它有两种模式一种是client,一种是cluster(集群)。
Dirver举列:集群有4个节点,S101为master节点。S102为worker节点,S103为worker节点,S104为worker节点.再有一个集群S105,它不是Spark集群内的节点。S105它即不是Master也不是worker,但是在S105上安装了Spark的包,只要安装了Spark的包就可以执行Spark的命令。spark-submit --master S101:7077 需要指定master.,那么程序就要部到S105上,启动的时候就直接启动S101:7077,那么S105就是Driver。因为客户端是跑在S105上的。它跟集群每一关系。它是一个驱动程序一个入口点。但是如果S105想要运行可以加 --deploy-mode cluster当你在提交这个应用的时候。这个S105就不是Dirver了。因为master会在其中的一个worker节点上来分配这个程序去执行。当你看到输出的一大堆,都是想Dirver回传的信息。包括client,一client那些点都把它收到的数据回传给Dirver端。然后将它打印出来了。用S105去提交作业,它真正的Dirver跑到Worker的某个点上了。这样就根本看不到它的执行过程了。
[Dirver演示]

Spark job部署模式
spark job的部署模式有两种模式,client和cluster
Spark-submit ..--deploy-mode client |cluster
1.client 默认值,drivaer 运行在client端主机上。
2.cluster driver 运行在某个worker节点上。客户端只负责提交job。
这两个的区别:参数问题
Driver:执行客户端代码程序,当是它在那个点运行是不一定的。得看部署模式,
举列:在实际运用上基本上都是集群上的,因为它需要收集数据。在自己的主机上,提交数据。如果突然之间断开。那就废了。。此刻Driver没有了,Driver没有了作业就执行不了。作业一跑可能几个小时,能等吗?在这里它还有一个数据量的限制,它不允许向客户端发送大量的数据,它会有一个网关限制。所以很多情况下是不适合使用 client.数据量少就没有问题。至于Dirver端的跟踪,回传都不在这,而是在一个Worker节点上。
注意:spark-shell是不能以class模式提交的。spark-shell是命令行。你一提交以集群跑几个点它就不知道了。那还如何交互。spark-shell只能以客户端模式访问。但别的程序是可以的。
[S101]
[centos@s101 /home/centos]$ spark-submit --class com.oldboy.spark.mr.TaggenJava2 --master spark://s101:7077 myspark.jar /user/centos/data/tags.txt
[centos@s101 /home/centos]$spark-submit --help
deploy mode DEPLOY_MODE:部署模式,是否在本地启动Dirver模式也就是客户端或者说是在worker的一台主机上。(默认是客户端)
[centos@s101 /home/centos]$spark-submit --class com.oldboy.spark.mr.TaggenJava2 --master spark://s101:7077 --deploy-mode cluster myspark.jar /user/centos/data/tags.txt
在跑的过程期间,在屏幕上根本就收不到信息。它在Worker的一个节点上跑的。而Dirver是在某个节点上跑了。
结果要输出的话就不能看控制台打印了,可以保存用save().现在是用collct收集,收集是打印在控制台上。但是根本是看不到的。如果要看的话也能看,该如何看?可以用nc(瑞士军刀回传)这个数据跑在那个点上,把它抓出来。看日志的话不方便,尤其是在运行期间是看不到的。可以写一个调试程序,它在过程运行期间的每一层代码可以把它的数据抓过来。它在那个主机上。端口是多少,还有线程是什么?id是什么?hash码是什么?都可以发送到服务器里面去。
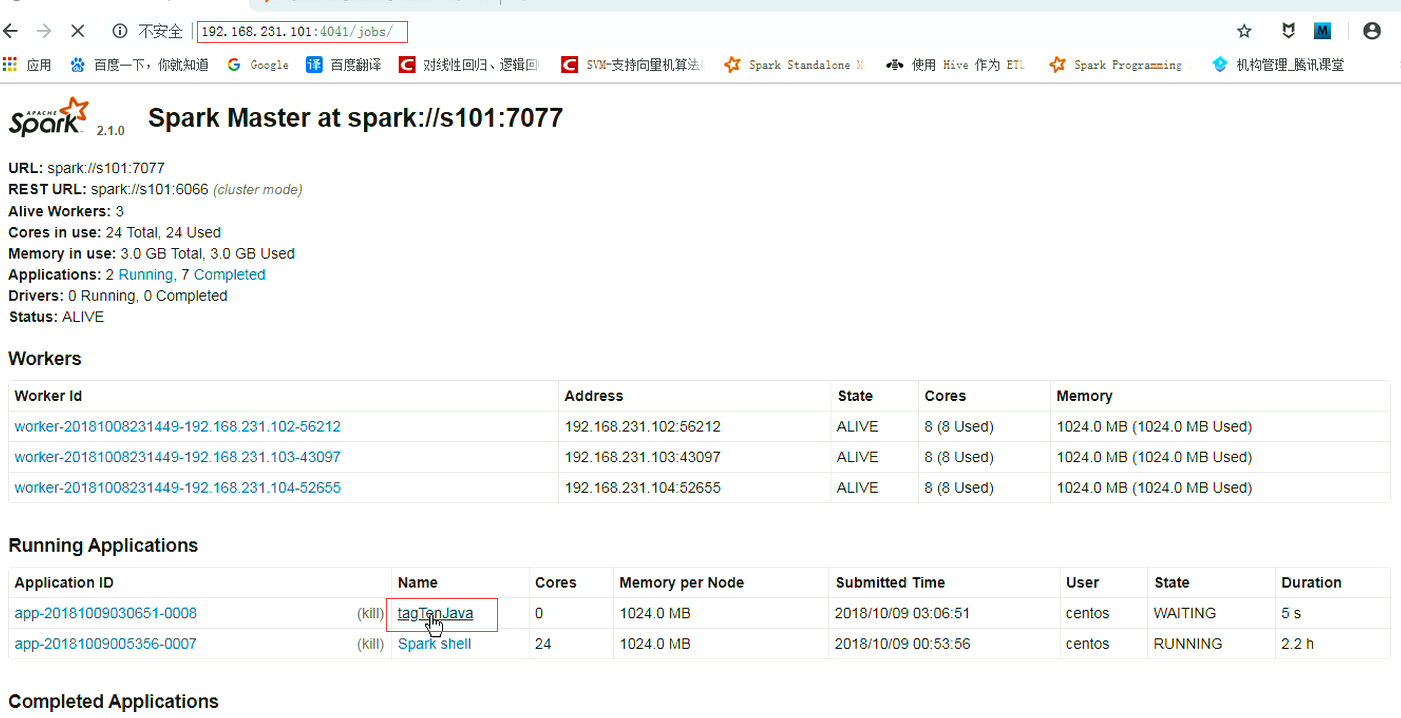
在windows环境下跑
D:\downloads\bigdata\spark-2.1.0-bin-hadoop2.7\bin>spark-submit --class TaggenScala1 --master spark://s101:7077 myspark.jar /user/centos/data/tags.txt


 浙公网安备 33010602011771号
浙公网安备 33010602011771号