福大软工1816 · 第二次作业 - 个人项目
1.在文章开头给出Github项目地址。
git项目地址:https://github.com/Stellaaa18/personal-project
2.给出PSP表格。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 360 | 800 |
| · Analysis | · 需求分析 (包括学习新技术) | 90 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 120 | 240 |
| · Code Review | · 代码复审 | 30 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 240 |
| Reporting | 报告 | 70 | 260 |
| · Test Repor | · 测试报告 | 30 | 220 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| | 合计 |440 |1075
3.解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程。
程序要求读入一个文本文件,统计该文件的字符数,单词数,有效行数以及输出词频最高的10个单词。我是用正则表达式做的,按行从文件读取内容,每当匹配到一个符合条件的单词时,就将其存进map里面。然后遍历map,将单词及其出现次数放到vector里面,排序输出词频最高的10个单词。
4.设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
关于代码结构
第一次写的时候,我是分成了以下几个函数,写在同一个源文件里面。
- CountChar() : 用于统计文件的字符个数
- CountLines() : 统计文件的有效行数
- CountWords() : 统计有效单词个数
- WordsFrequency() : 统计各个单词出现的次数,并将词频最高的10个单词输出到result.txt文件中
后面看到接口封装的要求,参考了赵畅同学的代码组织结构。
工程框架图如下:
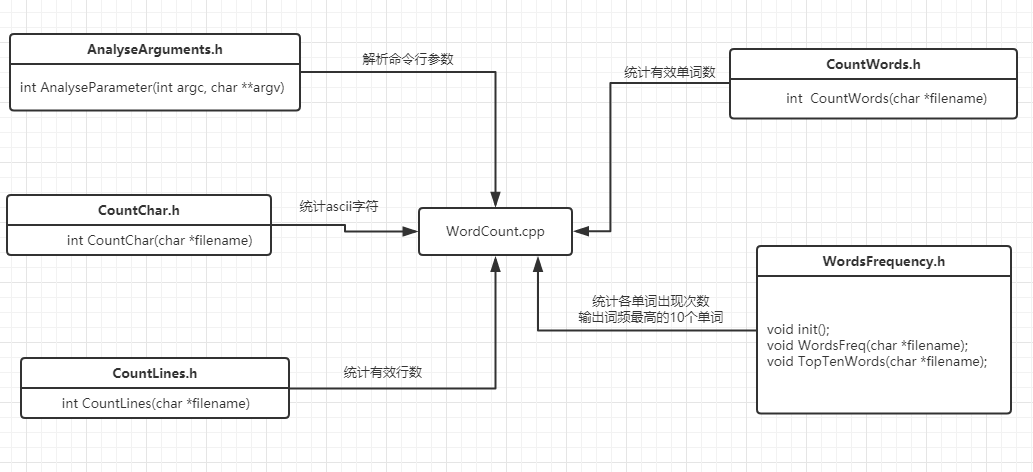
设计的单元测试如下:
| 单元测试名称 | 测试内容 | 测试函数 | 测试结果 |
|---|---|---|---|
| AllEmptyChar | 统计空白字符(空格,换行符,制表符) | CountChar() | 通过 |
| OtherASCII | 统计非数字字母的ascii码符号 | CountChar() | 通过 |
| IncludeEmptyLines | 统计含有空行的文件的行数 | CountLines() | 通过 |
| NotValidWords | 文本都是无效单词(例如abc,123file) | CountWords() | 通过 |
| WordSperator | 分隔符是其他ascii字符(例如"?","!","$") | CountWords() | 修改后通过 |
| EmptyFile | 测试空文件 | CountChar(),CountLines(),CountWords() | 通过 |
| CaseInsentitive | 测试是否不区分大小写(file和FILE为同一个单词) | WordsFreq() | 通过 |
| CheckOrder | 词频相同时是否按字典序 | WordsFreq(),TopTenWords() | 通过 |
以下部分单元测试代码:
namespace EmptyFile//测试空文件
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char filename[105] = "EmptyFile.txt";
int characters = CountChar(filename);
int lines = CountLines(filename);
int words = CountWords(filename);
Assert::IsTrue(characters == 0 && lines == 0 && words == 0);
}
};
}
extern map<string, int> M;
namespace CaseInsentitive //测试是否不区分大小写
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char filename[105] = "CaseInsentitive.txt";
init();
WordsFreq(filename);
map<string, int>::iterator it = M.begin();
Assert::AreEqual(it->second, 3);
}
};
}
5.记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。
将main()函数循环执行10000次,得到的结果如下:

程序一共运行了44.21秒,消耗最大的是CountWor()函数。从这张图可以看到,正则表达式有关的函数regex_serch和迭代器matcher消耗的时间也很大,紧跟在main()函数之后。
从下图可以看出,CountWord()函数里面有很多和正则表达式相关的操作,故而消耗的时间大。

代码覆盖率截图

从图中可以看出,除了分析命令行参数的函数AnalyseParameter(int argc, char **argv)代码覆盖率较低外,其他的覆盖率都很高。因为AnalyseParameter(int argc, char **argv)主要用来处理异常情况,而测试时用的样例大部分传参是正确的,故该函数覆盖率较低。
6.代码说明。展示出项目关键代码,并解释思路与注释说明。
在计算单词频率时,用到了正则表达式,参考了这篇文章C++语言,统计一篇英文文章中的单词数(用正则表达式实现)
具体代码如下:
string str;
regex rx("\\b[a-zA-Z]{4}[a-zA-Z0-9]*");//至少以四个英文字母开头
while (getline(file, str)) {
smatch m;
while (regex_search(str, m, rx)) {
string s = m[0];
for (int i = 0; s[i] != '\0'; i++) {
if (s[i] >= 'A'&&s[i] <= 'Z') s[i] += 32;//大写转小写
}
M[s]++;//将转换成小写的有效单词存进map里
str = m.suffix().str();
}
}
然后将map里的内容复制到vector里面,直接排序输出前10个词。
for (auto x : M) {
ans.push_back(x);
}
sort(ans.begin(), ans.end(), cmp);//排序
int count = 10;
//输出词频最高的10个单词
ofstream fout("result.txt");
for (auto x : ans) {
if (!count) break;
fout << "<" << x.first << ">: " << " " << x.second << endl;//输出到文件
count--;
}
fout.close();
异常处理
int AnalyseParameter(int argc, char **argv)
{
if (argc != 2) { //传入参数有误时,会给出提示
cout << "argument error.\n";
return -1;
}
ifstream fin(argv[1]);
if (!fin) { //若该文件不存在,也会报错
cout << "can't open the file.\n";
return -1;
}
return 1;
}
7.结合在构建之法中学习到的相关内容与个人项目的实践经历,撰写解决项目的心路历程与收获。
一开始拿到题目时,其实是有点慌的,不知道要从哪里开始做。后面冷静下来,一步步分析,先把主要核心功能细分成统计字符数,行数,单词数及计算词频四个部分,一个个写出来。后面再写个函数解析命令行参数,至此基本功能都已经完成了,然后就剩下单元测试和性能改进了。
这次项目最大的收获就是,遇到难题不应该害怕,分成一个个更小的任务,逐个去解决,好像也没想象中那么困难。
8.Refrence
用正则表达式统计单词数: https://www.bbsmax.com/A/A2dmM8qgde/
赵畅同学博客: http://www.cnblogs.com/ZCplayground/p/9607027.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号