OMG-LLaVA学习记录---模型评估与尝试微调
OMG-LLaVA学习记录---模型评估与(尝试)微调
首先根据文档
# for chat
python omg_llava/tools/chat_omg_llava.py \
${PATH_TO_CONFIG} \
${PATH_TO_PTH} \
--image ${PATH_TO_IMAGE}
# the corresponding segmentation masks will be saved at ./output.png
# for evaluation referring expression segmentation
NPROC_PER_NODE=8 xtuner refcoco_omg_seg_llava \
${PATH_TO_CONFIG} \
${PATH_TO_PTH} \
--dataset ${refcoco or refcoco_plus or refcocog} \
--split ${val or testA or testB}
# for evaluation gcg
NPROC_PER_NODE=8 xtuner gcg_omg_seg_llava \
${PATH_TO_CONFIG} \
${PATH_TO_PTH} \
--output-name gcg_pred
python omg_llava/tools/evaluate_gcg.py \
--prediction_dir_path ./work_dirs/gcg_pred/
--gt_dir_path ./data/glamm_data/annotations/gcg_val_test/
--split ${val or test}
# for evaluation region caption
NPROC_PER_NODE=8 xtuner region_cap_mask_omg_seg_llava \
${PATH_TO_CONFIG} \
${PATH_TO_PTH} \
--output-path ./work_dirs/region_cap_pred.json
python omg_llava/tools/evaluate_region_cap.py \
--results_dir ./work_dirs/region_cap_pred.json
Evaluation
关于评估,这次只在 Refcoco Refcoco+ Refcocog三个数据集上跑了val, testA, testB, (其中Refcocog的测试集只有test)
剩下的数据集接近180GB, GPU我还是租的,全测下来实在有些抗不住QAQ
所以主要测指代性分割这个功能了
接下来先看一下结果
Refcoco
val
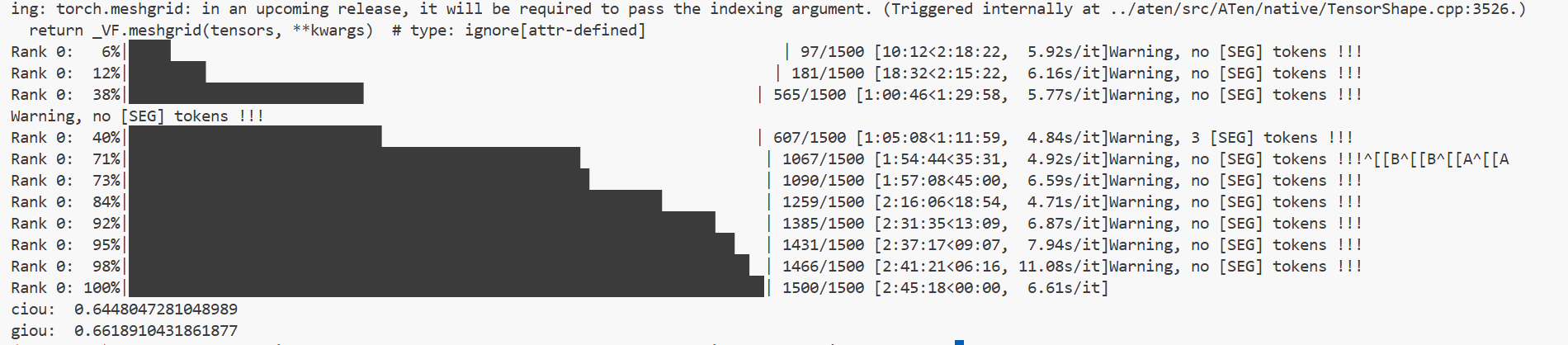
testA
testB

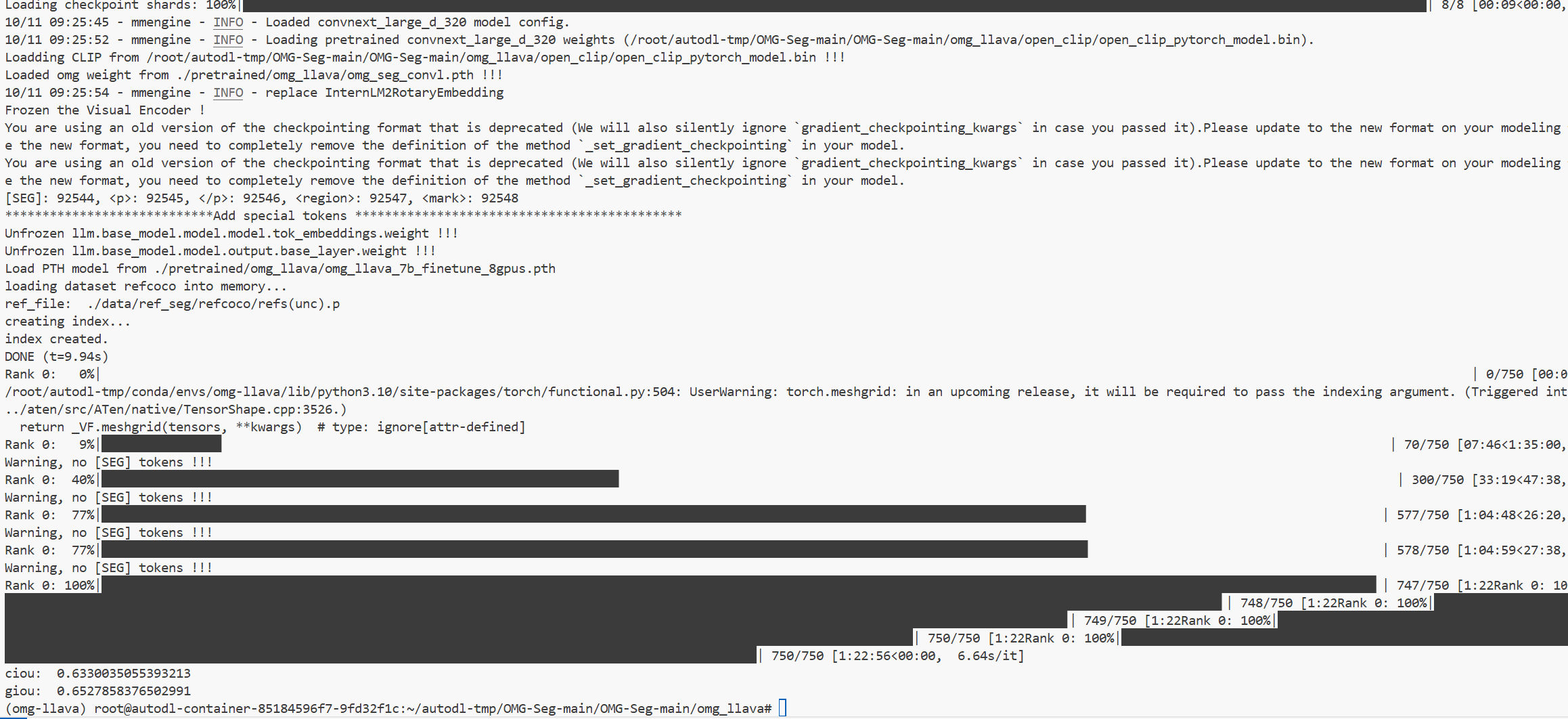
Recocog
val

test
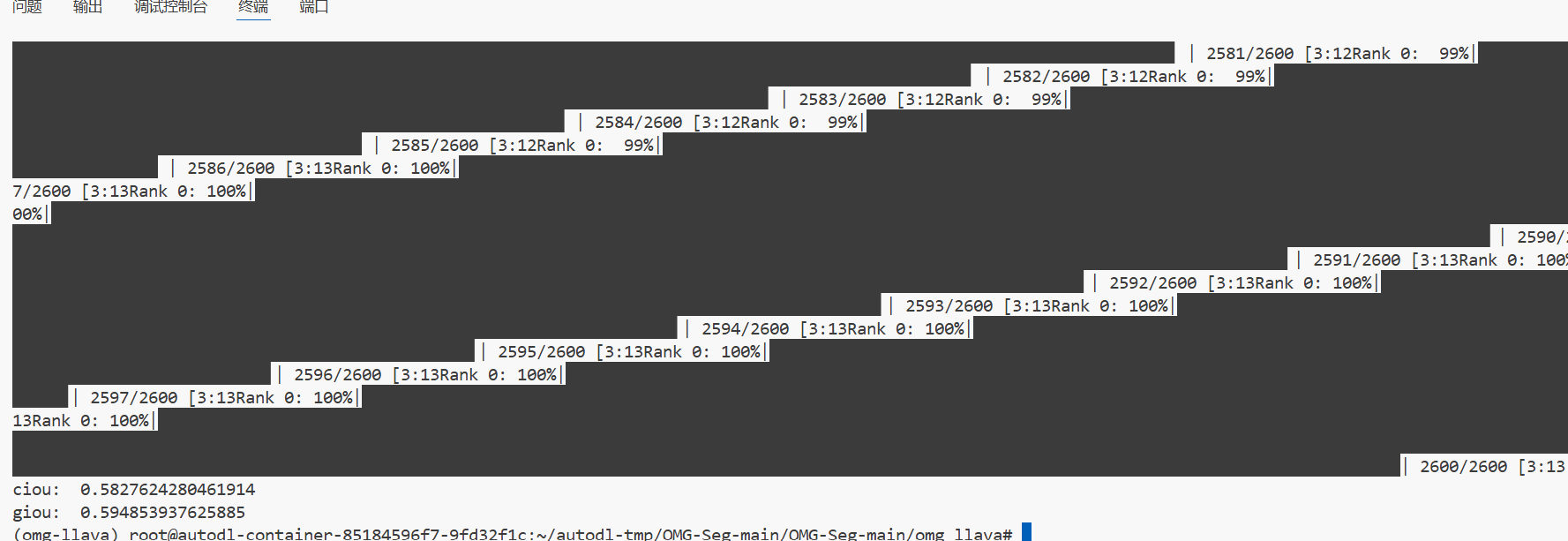
Recoco+
val
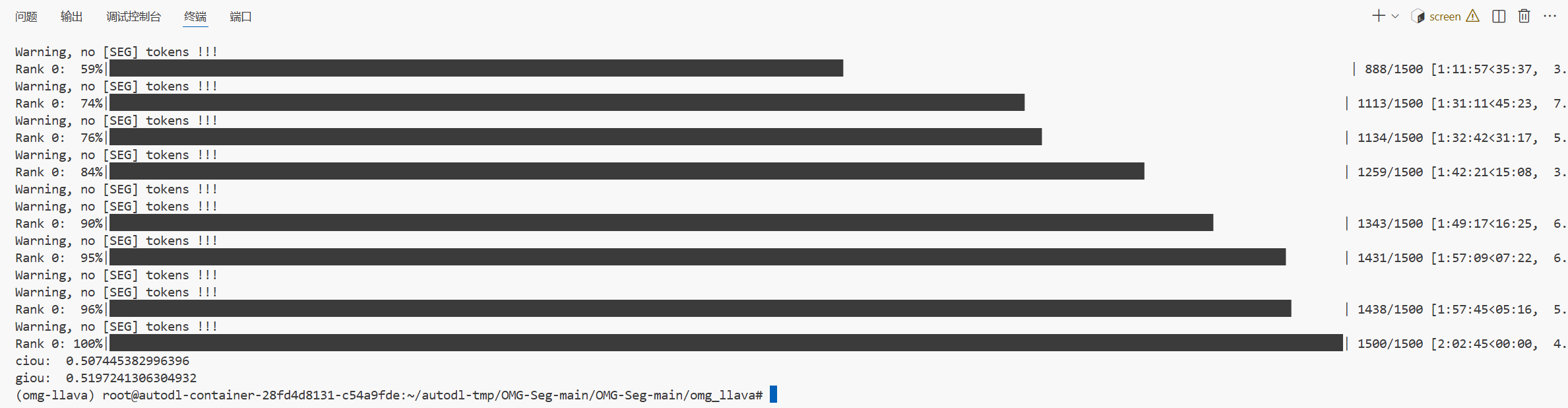
testA

testB

对比与分析
cIoU
| Method | refCOCO Val | refCOCO TestA | refCOCO TestB | refCOCO+ Val | refCOCO+ TestA | refCOCO+ TestB | refCOCOg Val | refCOCOg Test |
|---|---|---|---|---|---|---|---|---|
| (Paper) OMG-LLaVA | 75.6 | 77.7 | 71.2 | 65.6 | 69.7 | 58.9 | 70.7 | 70.2 |
| (Paper) OMG-LLaVA(ft) | 78.0 | 80.3 | 74.1 | 69.1 | 73.1 | 63.0 | 72.9 | 72.9 |
| (My) OMG-LLaVA | 64.5 | 63.3 | 63.4 | 50.7 | 49.3 | 47.9 | 57.8 | 58.2 |
结果较差的可能原因的分析
-
环境与库版本不匹配,在这个过程中,为了解决PyTorch兼容的问题,我把\(NumPy\)的版本降低,同时降低了Opencv-Python的版本; 为了解决gradio的TypeError的bug, 有对gradio和gradio-client进行了升级; 为了解决ValueError:
.tois not supported for4-bitor8-bitbitsandbytes models. Please use the model as it is...这个问题,把accelerate库的版本降低,这个环境可能已经与作者的环境相差比较大了 -
模型权重文件可能不完全匹配,同的训练策略会导致不同的结果。我们使用的通用微调模型,其权重和论文中的可能存在差异。
尝试微调(失败)
微调时显存爆掉了
尝试ZeRO Offloading, 尝试将优化器状态从 GPU 显存中卸载CPU 内存中
deepspeed_zero2 = dict(
optimizer=dict(
type='AdamW',
lr=2e-5,
betas=(0.9, 0.999),
weight_decay=0.05,
),
scheduler=dict(type='WarmupDecayLR',
warmup_min_lr=0,
warmup_max_lr=2e-5,
warmup_num_steps=100,
total_num_steps=10000),
zero_optimization=dict(
stage=2,
allgather_partitions=True,
allgather_bucket_size=2e8,
reduce_bucket_size=2e8,
overlap_comm=True,
contiguous_gradients=True,
offload_optimizer=dict(device='cpu', pin_memory=True),
),
fp16=dict(
enabled=True,
initial_scale_power=16
),
train_micro_batch_size_per_gpu=1,
)
依旧爆掉了
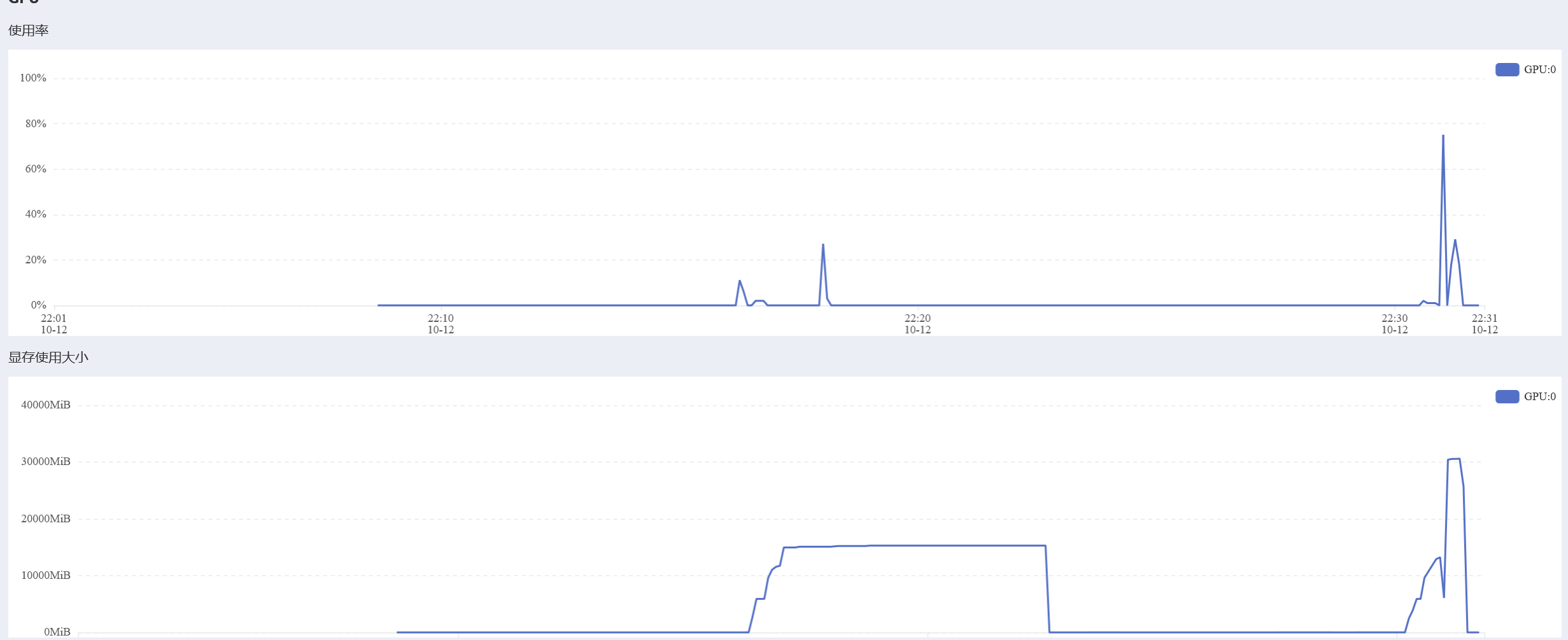

分析原因可能是显存比较小放不下梯度和优化器状态了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号