OMG-LLaVA学习记录---模型跑通
OMG-LLaVA学习记录---模型跑通
环境配置
我们先按照项目文档要求创建一个Python环境并且激活
conda create -n omg-llava python==3.10
source activate omg-llava
接着我们来安装torch
# install pytorch with cuda 11.8
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
然后安装omg-seg这个模型所需的依赖
python -m pip install https://github.com/open-mmlab/mmengine/archive/refs/tags/v0.8.5.zip
TORCH_CUDA_ARCH_LIST="8.0" TORCH_NVCC_FLAGS="-Xfatbin -compress-all" CUDA_HOME=$(dirname $(dirname $(which nvcc))) LD_LIBRARY_PATH=$(dirname $(dirname $(which nvcc)))/lib MMCV_WITH_OPS=1 FORCE_CUDA=1 python -m pip install git+https://github.com/open-mmlab/mmcv.git@4f65f91db6502d990ce2ee5de0337441fb69dd10
这里注意 先检查现在GPU物理架构是什么,然后去查找TORCH_CUDA_ARCH_LIST, 这里论文中的GPU是A100架构,所以是8.0
python -m pip install \
https://github.com/open-mmlab/mmdetection/archive/refs/tags/v3.1.0.zip \
https://github.com/open-mmlab/mmsegmentation/archive/refs/tags/v1.1.1.zip \
https://github.com/open-mmlab/mmpretrain/archive/refs/tags/v1.0.1.zip
安装其他依赖,注意进入到项目根目录中,也就是....../omg_llava/
# install other requirements
pip install -e '.[all]'
注意
这里可能会报一个warning,说NumPy和PyTorch不兼容,我们把NumPy降级到1.26.4,接着又warning说和opencv-python不兼容,我们直接把opencv-python版本降下去就好了,这里最重要的是PyTorch的版本
然后去Hugging Face上把预训练权重和LLM模型下载下来,有意思的是,虽然是OMG-LLaVA, 但是LLM没有直接用LLaVA, 而是用了Internlm-chat-7b这个模型
然后按这个方式放置文件
|--- pretrained
|--- omg_llava
internlm2-chat-7b
convnext_large_d_320_CocoPanopticOVDataset.pth
omg_seg_convl.pth
omg_llava_7b_pretrain_8gpus.pth
omg_llava_7b_finetune_8gpus.pth
finetuned_refseg.pth
finetuned_gcg.pth
根据文档,我们现在可以运行Demo了
python omg_llava/tools/app.py \
${PATH_TO_CONFIG} \
${PATH_TO_DeepSpeed_PTH}
# for example
python omg_llava/tools/app.py omg_llava/configs/finetune/omg_llava_7b_finetune_8gpus.py \
./pretrained/omg_llava/omg_llava_7b_finetune_8gpus.pth
我是把pretrained放在了项目根目录omg_llava/(第一个omg_llava)下,那么运行的指令和这里面的example应该是一样的
我们尝试执行一下看看,大概率会报这样一个错误
.to is not supported for 4-bit 或 8-bit bitsandbytes models. Please use the model as it is, since the model has already been set to the correct devices and casted to the correct dtype。
出错的原因是(询问自Gemini 2.5 pro)
- 当我们使用bitsandbytes进行4位或8位量化时,模型已经被自动:
- 分配到正确的设备(GPU)
- 转换为正确的数据类型
- 不能在手动调用
.to()方法
AI给出的解决方法主要有两种
- 移除所有
-.to()调用 - 在创建时用
device_map = "auto"自动分配到可用设备
但是经过一番对配置文件的“魔改”依然出错,后来经过不断尝试和github上网友们的智慧找到了两种方法
- 将
transformers库升级到4.47.0版本,经过实测,Demo能正常运行,但是这样之后会出问题,当我们去微调和评估模型的时候会用到Xtuner库,而这个库已经被提前装进整个项目中的代码仓库中, 版本已经被锚死在了0.1.21了,经过多次尝试和查找资料,这个版本的Xtuner匹配的transformers的版本只有4.36.0,也就是我们原来的版本,走到死胡同里面了,一旦改到原来的transformers就会报错 - 最终解决方案 ----- 把
accelerate的版本降到0.26.0,这两个问题都解决了(感觉很玄,完全就是试出来的)
然后在运行,大概率会发现显存爆掉了
runtimeError: CUDA out of memory xxxxxxxx
原因:代码中支持4-bit量化,但是没有默认启动,我们要手动启动
python omg_llava/tools/app.py \
omg_llava/configs/finetune/omg_llava_7b_finetune_8gpus.py \
./pretrained/omg_llava/omg_llava_7b_finetune_8gpus.pth \
--bits 4 --torch-dtype auto
至于--torch-dtype auto
-
功能:指定模型加载和运行时使用的数据类型(auto 表示让框架自动选择最合适的类型,如 GPU 支持则优先用 bf16,否则用 fp16)
-
作用:
平衡计算精度和速度:fp16/bf16比fp32计算更快,显存占用更低,适合大模型推理。
兼容性:auto会根据硬件自动适配(如老GPU可能不支持bf16,自动降级为fp16)。
如果还是爆显存
我们来修改一下app.py中的配置
# build llm
llm = model.llm
tokenizer = model.tokenizer
#==================================================================#
# model.cuda()
#==================================================================#
#修改#
#===================================================================#
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if device.type == 'cuda':
if args.bits is None:
model.to(device)
else:
model.visual_encoder.to(device)
model.projector.to(device)
if getattr(model, 'projector_text2vision', None) is not None:
model.projector_text2vision.to(device)
else:
warnings.warn('CUDA 不可用,模型将在 CPU 上运行,这会极大影响推理速度。', RuntimeWarning)
#=======================================================================#
原因: 我们只有在全参数训练的时候才把整个模型加载到GPU上,运行时只让视觉分支在GPU上
然后就能运行Demo了
如果遇到TypeError升级一下gradio试一下
运行结果
- Grounded Caption Generation接地对话生成(混合任务:图像级 + 像素级)
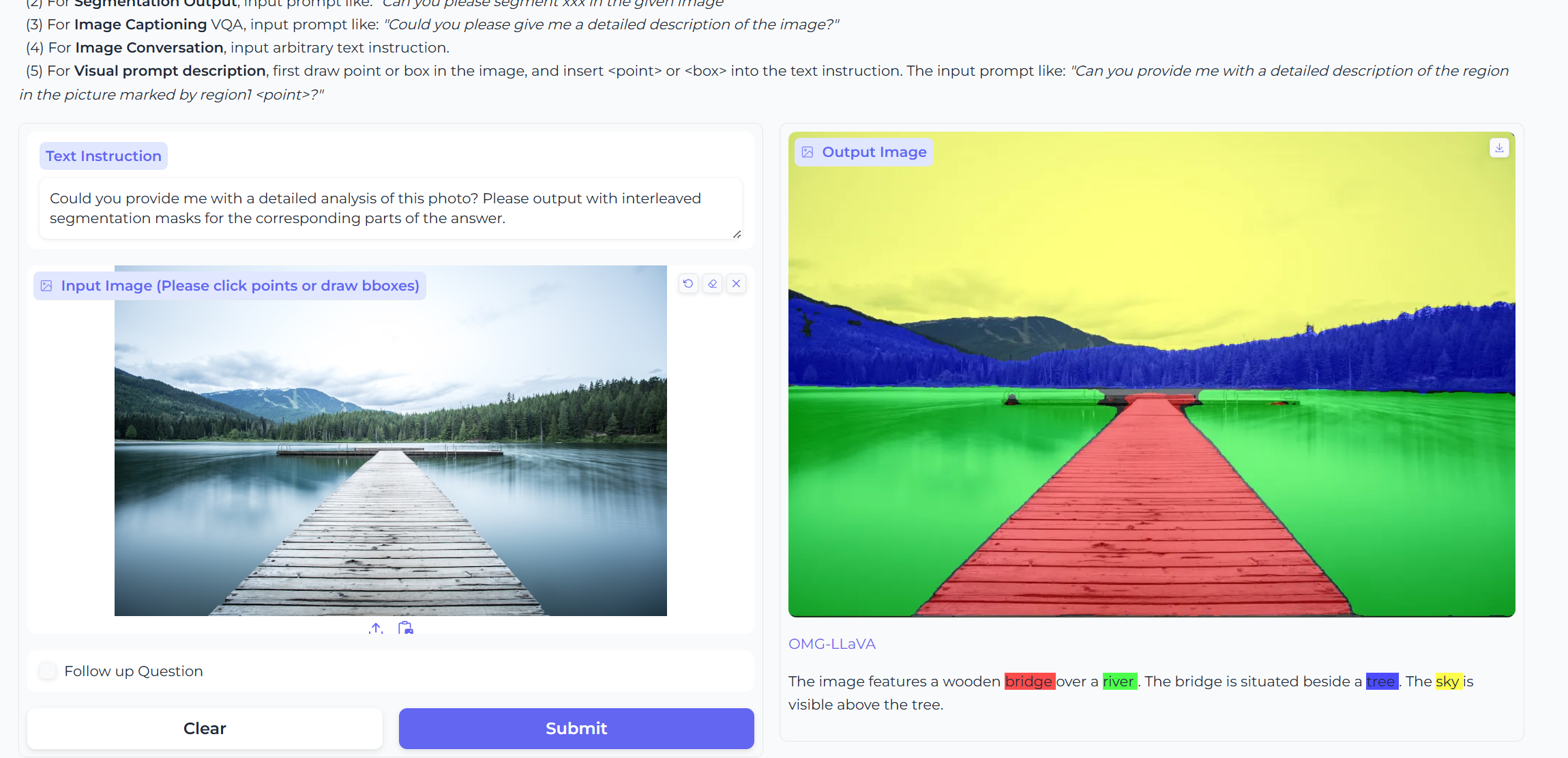
- Segmentation Output图像分割(像素级)
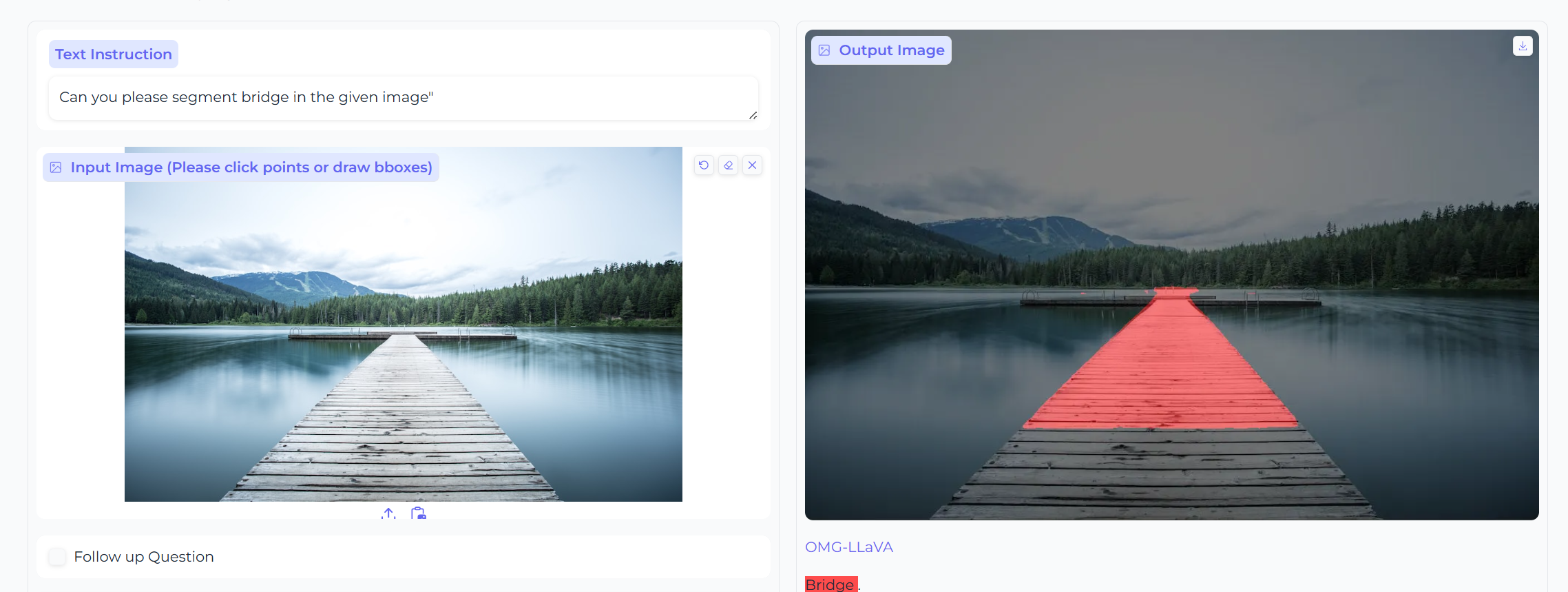
- RES指代性分割
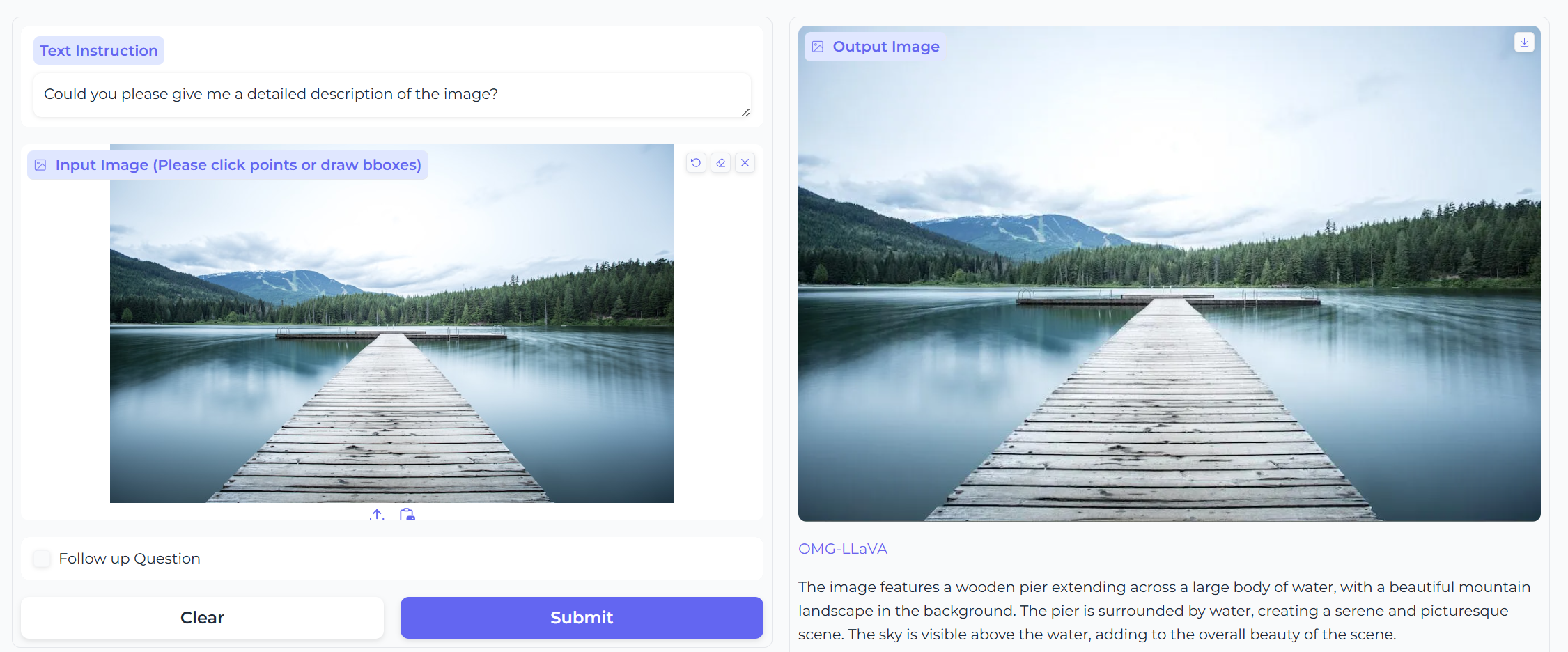
- Image Captioning图像描述(图像级别)
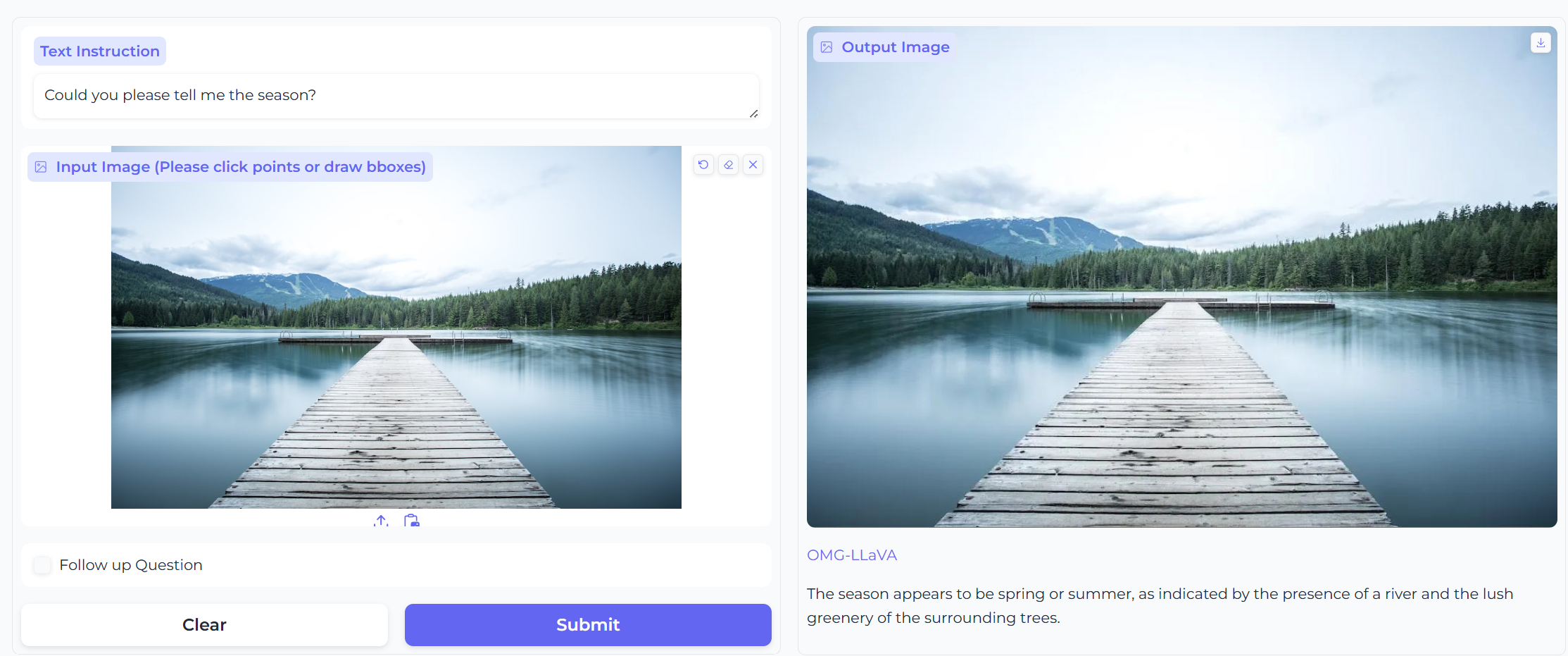
- Visual prompt description视觉提示描述(对象级)

- 聊天、推理(对象级)
再用其他图片测试一下
- GCG接地对话生成(混合任务 图像级 + 像素级)
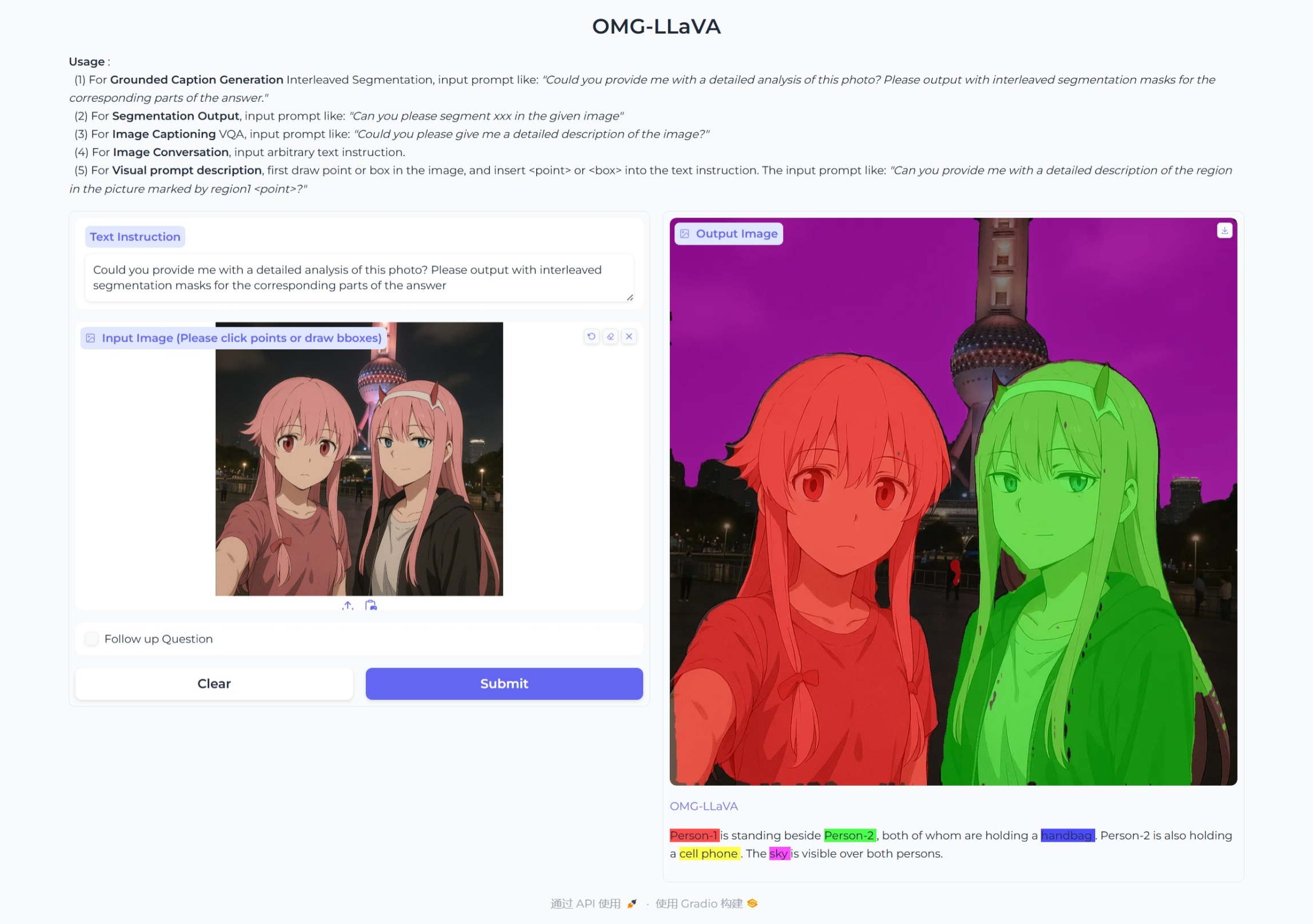

这里看出这个图分割得不是特别好,推测原因是图像的信息可能比较多
-
视觉提示描述(对象级)
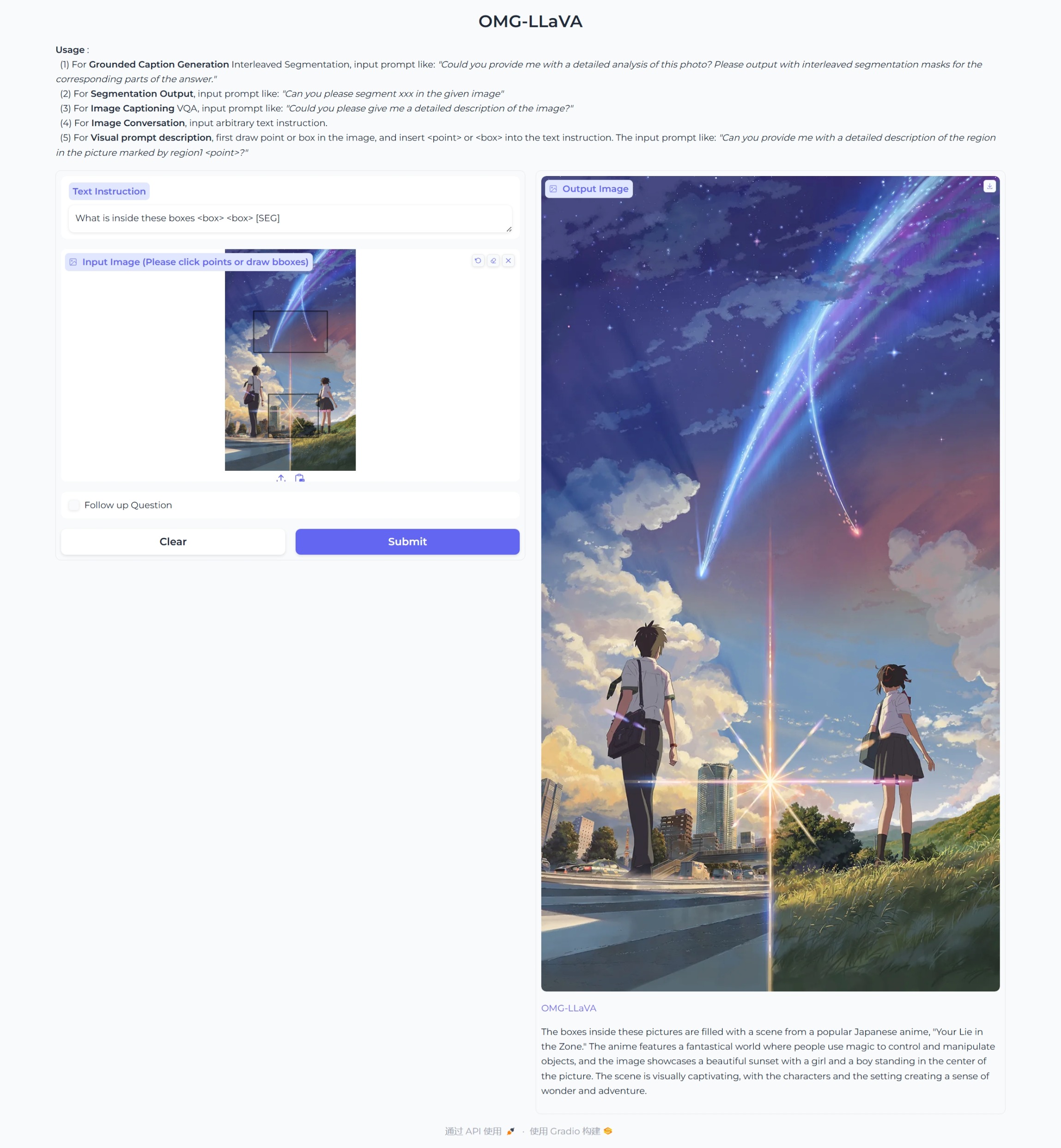
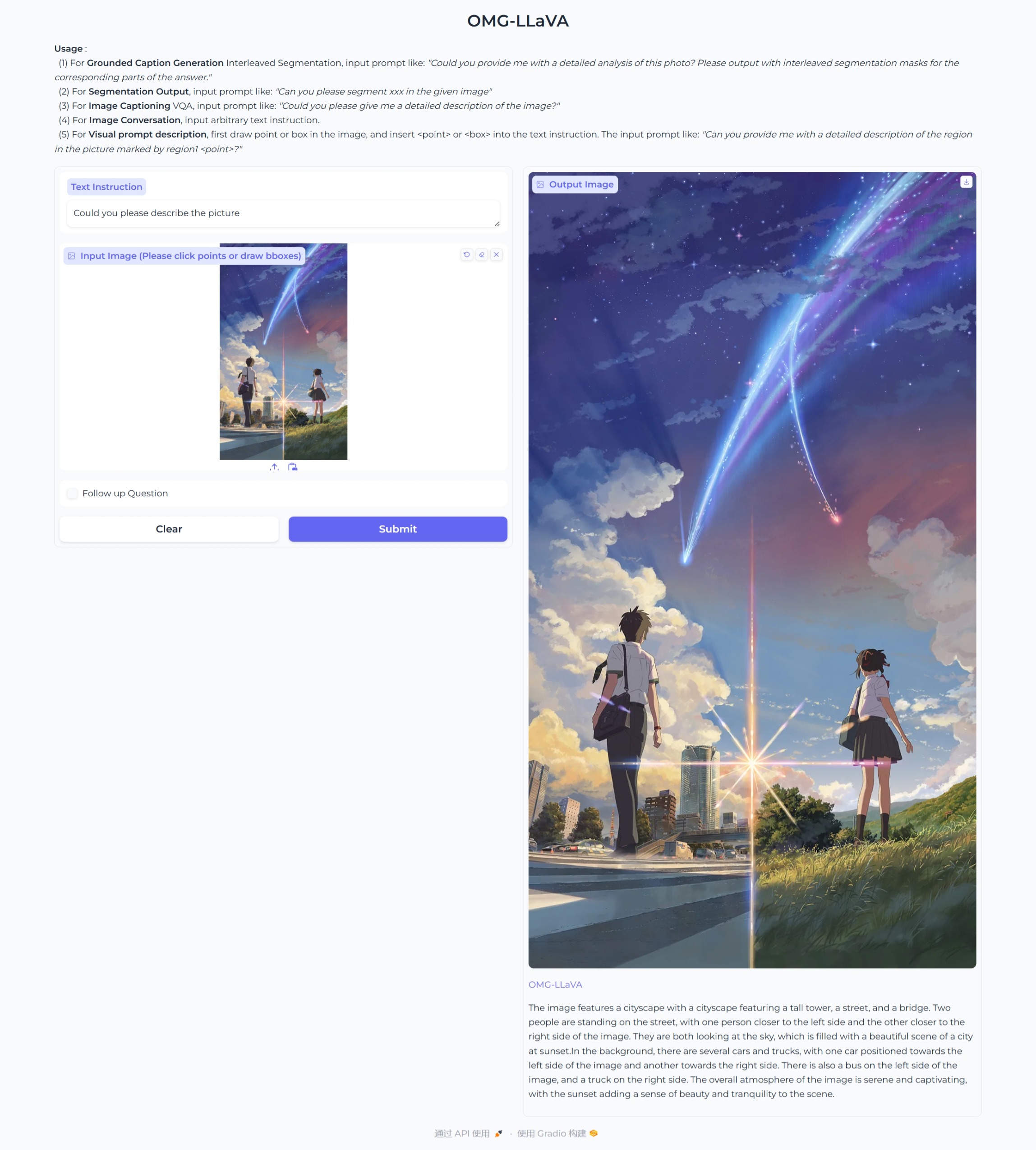
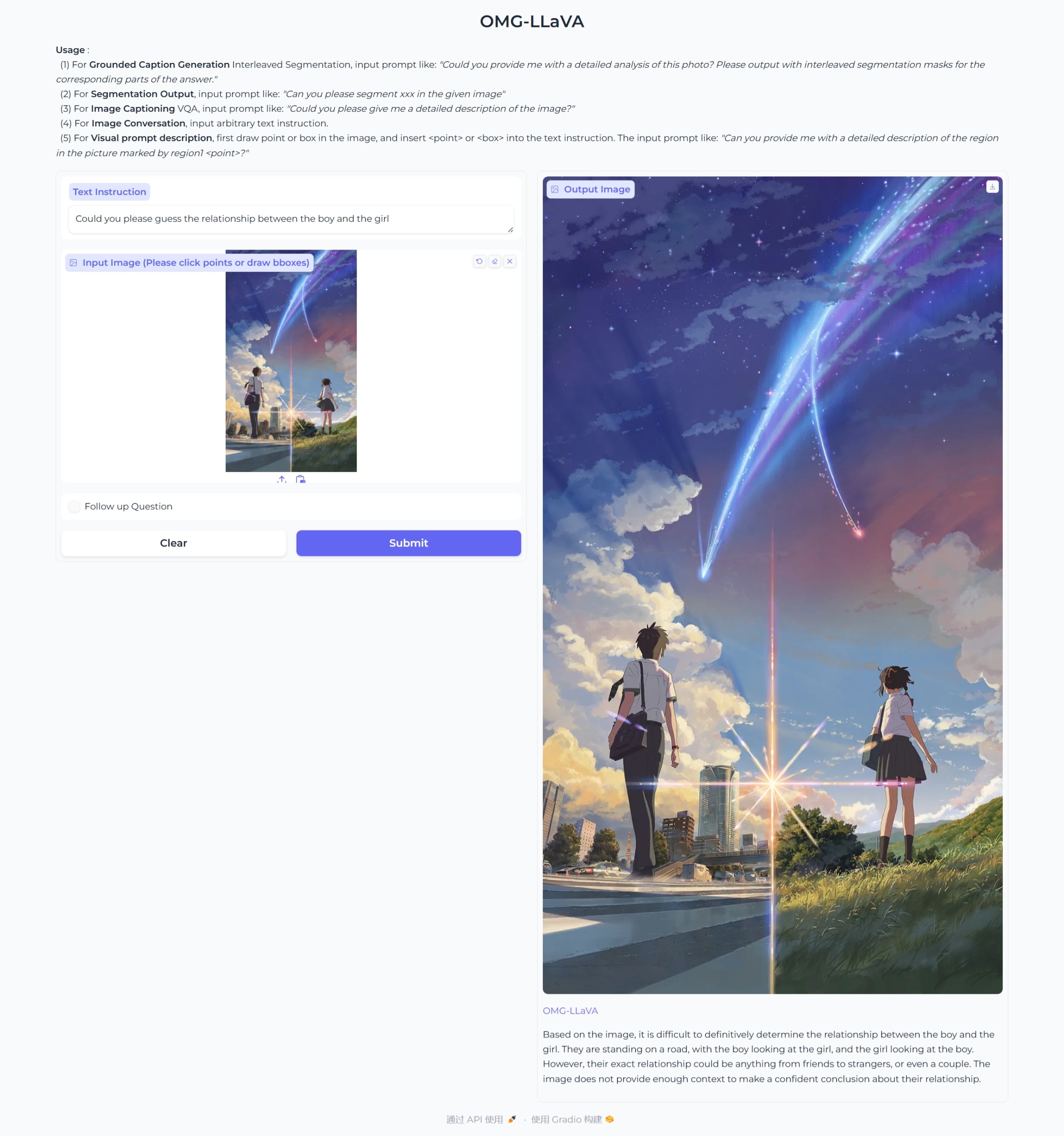
-
对话和推理(图像级)

- RES指代性分割 --这里比较有迷惑性的信息效果就不是很好了
.jpeg)
这里把男生当成了女生
.jpeg)
这里就正常了
Chat
我们试Chat---和模型对话
python omg_llava/tools/chat_omg_llava.py \
omg_llava/configs/finetune/omg_llava_7b_finetune_8gpus.py \
./pretrained/omg_llava/omg_llava_7b_finetune_8gpus.pth \
--image ./test.jpg
对话结果
- 聊天
-
描述图像

-
图像分割
double enter to end input (EXIT: exit chat, RESET: reset history) >>> hello
prompt_text: <|im_start|>user
<image>
hello<|im_end|>
<|im_start|>assistant
torch.Size([1, 121, 4096])
Hello! How can I help you today? Is there something specific you would like to know or discuss? I'm here to provide information and answer any questions you may have.<|im_end|>
tensor([ 1, 9843, 346, 2745, 777, 489, 1638, 629, 3514, 345, 2313, 1194,
2650, 3317, 629, 1178, 1217, 442, 1560, 607, 4420, 345, 489, 2940,
1734, 442, 3572, 2145, 454, 4384, 1030, 4917, 629, 1377, 746, 281],
device='cuda:0')
double enter to end input (EXIT: exit chat, RESET: reset history) >>> please describe the picture
prompt_text: <|im_start|>user
please describe the picture<|im_end|>
<|im_start|>assistant
torch.Size([1, 171, 4096])
The image features a wooden bridge with a beautiful view of a lake. The bridge is located near the water, providing a serene and picturesque setting. The bridge is the main focus of the image, with the lake and surrounding landscape serving as the background.<|im_end|>
tensor([ 1, 918, 2321, 4581, 395, 22643, 14304, 579, 395, 6389,
1800, 446, 395, 22055, 281, 707, 14304, 505, 7553, 3308,
410, 3181, 328, 8373, 395, 1566, 2104, 454, 9315, 722,
6399, 281, 707, 14304, 505, 410, 2036, 5404, 446, 410,
2321, 328, 579, 410, 22055, 454, 14723, 18566, 13622, 569,
410, 4160, 281], device='cuda:0')
double enter to end input (EXIT: exit chat, RESET: reset history) >>> Could you please segment the bridge in the picture?
prompt_text: <|im_start|>user
Could you please segment the bridge in the picture?<|im_end|>
<|im_start|>assistant
torch.Size([1, 245, 4096])
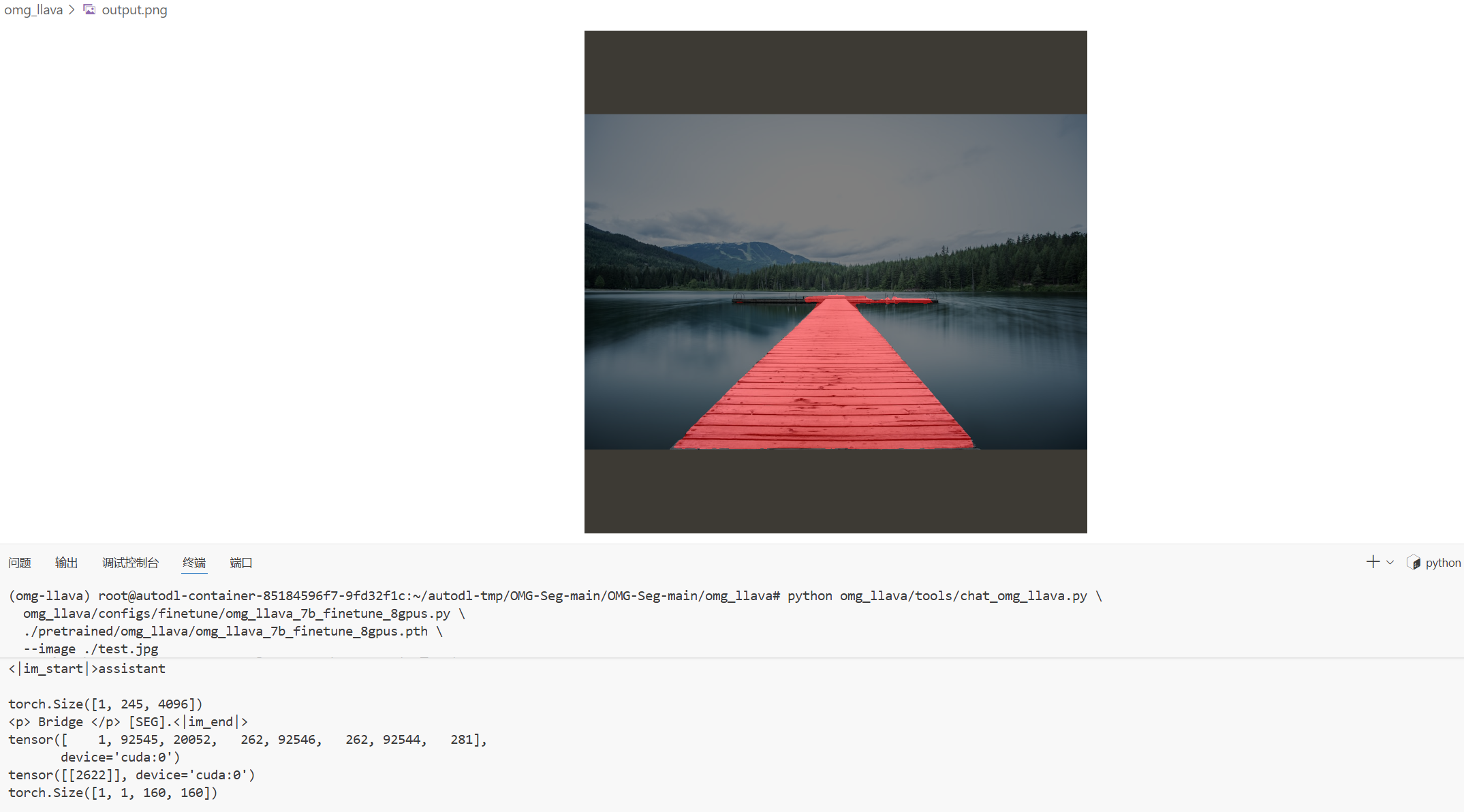
<p> Bridge </p> [SEG].<|im_end|>
tensor([ 1, 92545, 20052, 262, 92546, 262, 92544, 281],
device='cuda:0')
tensor([[2622]], device='cuda:0')
torch.Size([1, 1, 160, 160])
让我们结合论文分析一下这个对话
第一轮对话
-
输入:
hello -
模型处理
prompt_text: <|im_start|>user\n<image>\nhello<|im_end|>\n<|im_start|>assistant
这是发给LLM的完整提示,它遵循了internlm2-chat的格式
其中<image>这个token。在这一步,我们上传的图片已经被视觉编码器处理成了 visual tokens , 并在代码层面替换了<image>token, 与文字"hello"一起被送进了LLMtorch.Size([1, 121, 4096])这个是输入给LLM的embeddings(嵌入向量)的维度,1是批处理的大小, 4096是LLM的隐藏层维度,121是输入序列的总长度(包含了文字的token和图像的视觉token)
第二轮对话
-
输入 :
please describe the picture -
模型处理 :
torch.Size([1, 171, 4096]), 序列长度从 121 增加到了 171。这是因为这次的输入不仅包含了新的问题"please describe the picture",还包含了上一轮的对话历史,以维持上下文。
第三轮对话
模型输出
<p>Bridge</p>表示模型识别出了要分割的核心物体“桥”
[SEG] : 重要的token, 当检测到LLM输出这个token,它就知道这不是一次普通的对话,而是需要执行一次分割操作
token([.....]) : 模型输出的token ID序列
tensor([[2622]], device='cuda:0'): 与[SEG]对应的特征向量,准备送给视觉解码器
torch.Size([1, 1, 160, 160]) : 最终的产物, 一个160 x 160的分割掩码,视觉解码器接收到上一步的指令向量后,成功地分割出了桥

 浙公网安备 33010602011771号
浙公网安备 33010602011771号