
Elastic Stack的应用(Elasticsearch/Logstash/Filebeat/kibana)
Elastic Stack文章说明
注意:本文章编写的时间截止在Elastic 8.9版本,虽然可能出现旧版语法,但是我会根据自己所知进行信息说明,是否在新版能够继续适配
Elastic有很多的产品,虽然每个应用方向不同,但是主要还是做的是日志集群方面。
文章中注重于Elastic的Elasticsearch/Logstash/beats/kibana四大组件的应用以及少部分理论
可以看作是个人的学习文档
体系说明
Elastic Stack的产品主要是用在集群环境。
它可以通过多种多样场景的分布式进行数据的收集,拆分,重写,存储。
基于分布式的特点,它将整个体系的组件进行了拆解,每个组件负责不一样的部分。
Elasticsearch:负责存储数据,保存数据,管理数据
Logstash/Filebeat:负责收集数据,切割数据,重写数据发送至存储对象。Logstash支持多种多样化的收集以及数据操作,而Filebeat注重收集数据并不过多的涉及到数据的操作。
Kibana:负责数据的可视化,提供人阅读
架构建设
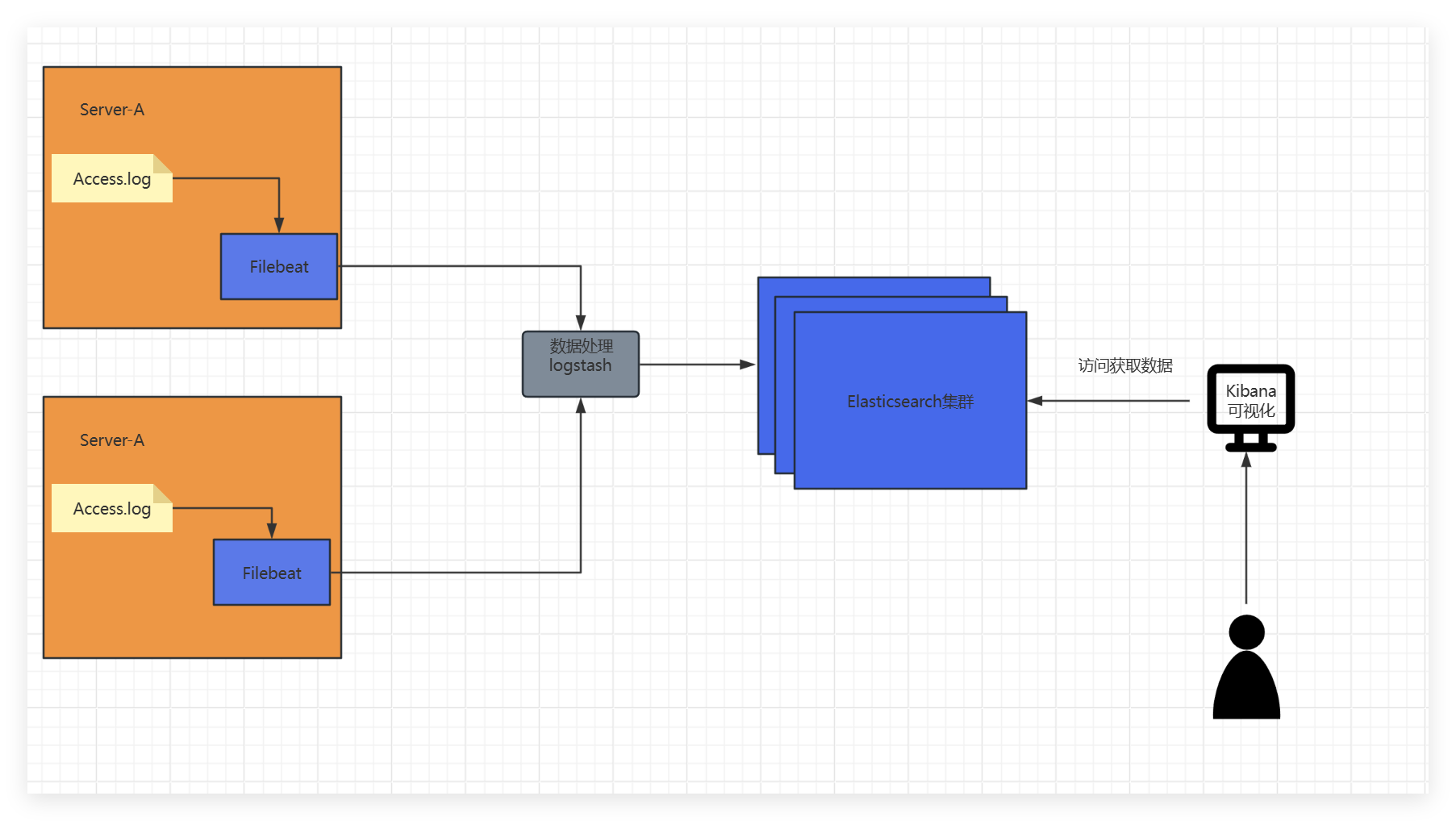
当然也并非说是一定要这样Elastic Stack支持多样化组件,比如说Kafka集群接收File beat数据转发到其他存储服务器上再通过Grafana可视化也可以,不一定是需要Elastic Stack集群体系
Elastic Stack的组件都很厉害而且非常的好用,它的支持性不仅仅只是包括Elastic Stack体系。
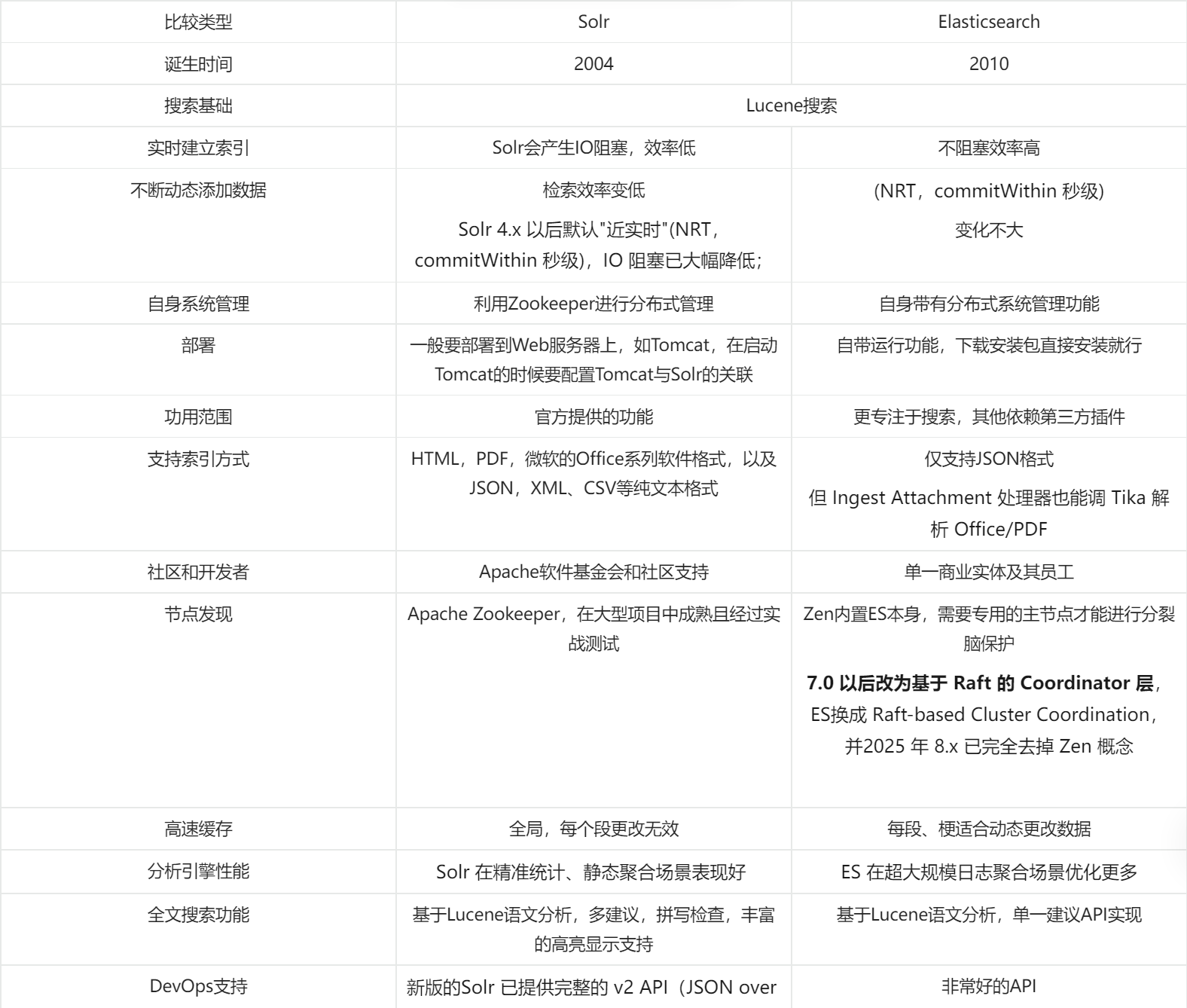
ElasticSearch优缺点
表格太麻烦了不是那么好用,我贴个图。感兴趣可以看看

理论知识
Elasticsearch
端口开放情况:
9200:对外接收数据,数据查询,读取等操作
9300:负责集群内部通讯,如集群数据内部传输,转发等
节点角色:
Master Node 主节点:拥有整个集群的决策权,本身既可以存储数据也可以不存数据,但是整个集群的决策,生命周期,策略规定均有Master节点发布,负责调配执行
Data Node 数据节点:负责存储日志数据,但无决策权。无情的打工机器
Coordinating Node 协调节点:该角色并不属于官方指定角色。它是一个接收到日志数据的节点,不一定是它存储数据,负责与主分片节点进行协商数据存储,以及收集器之间的通信。
数据划分:
分片:Elasticsearch把数据一条一条当“文档”存,这些文档真正落盘(写入当硬盘)的地方就叫分片;分片又分主分和副本。
主分片:Elasticsearch首次将数据写入(存储)的地方,叫做主分片。它具有最高的数据权威,一切的数据冲突操作或者是数据错误的时候,一切以主分片为准。
副本分片:Elasticsearch会抄写主分片的数据存储在其他的Elasticsearch节点上,它不仅会提供数据的备份还会在数据需要被调用读取的时候,提供读取操作,以此增加数据的可用性和可靠性。(默认为1,即每个主分片默认拥有一个副本)
机制:
索引:用于管理某块区域的数据,简单来讲就是给主分片和副本分片的一个集体,进行起名管理。所有的决策都Elasticsearch会通过索引进行绑定管理。
滚动策略:filebeat默认自带滚动策略,滚动策略会以一个固定格式+变量进行新索引创建,比如说到达50G的时候,会自动创建一个新的索引。如索引为Data-1滚动策略滚动后则会变成Data-2,新的数据将会放进Data-2。
Elasticsearch主分片机制
Elasticsearch主分片,必须在ES集群对索引数据进行收集的前规定,且一旦规定将不可更改。
主分片可以理解为是数据区块,它会随着数据越多,所需容量也会继续增大,它的这个区块,不一定是只存储在单独一台的Elasticsearch节点上,而是有可能存储在多个Elasticsearch节点上,每一片都拥有一个shard-id
Elasticsearch主分片数据存储方式(路由寻址)
Routing:
Filebeat将数据采集发送到任意Elasticsearch节点(首个接收到该信息的一般叫Coordinating Node 协调节点)上时,如果说Filebeat未对数据指定_id的情况下,则会由Coordinating Node将会对数据中的某些数值进行运算或者就地取材拿取部分数据直接当作Routing(也可能是随机产生一个)进行主分片寻址计算。
UUID(_id):
数据唯一标识符,可参与路由寻址计算(默认不指定)。
当为数据指定了该标识时,Coordinating Node将会直接使用该数值当作Routing参与路由寻址计算,寻找主分片地址,并将数据转发至主分片节点上
当未指定该标识时,Coordinating Node将会对数据中的某些数值进行运算或者就地取材拿取部分数据直接当作Routing(也可能是随机产生一个)进行寻址计算,并根据计算结果转发至该数据的主分片节点上,主分片节点将会采用Routing再次对该数据进行数据验算,若符合结果会将会为数据生成一个UUID(_id)值,并存储至本节点中。若结果校验不一致将直接拒绝写入并抛出异常。
Elasticsearch节点对JSON数据进行解析流程如下:
1、Filebeat将数据采集发送到任意Elasticsearch节点(首个接收到该信息的一般叫Coordinating Node 协调节点)上.
2、获取该索引得到主分片数(numPrimaries).
3、默认情况下Elasticsearch 节点将为发来的数据指定一个Routing(具体参照Routing机制).
4、通过hash(routing) % numPrimaries进行运算获取到shard-id.
5、接着查询该索引的Routingtable,得到shard-id当前所在的Elasticsearch节点地址.
6、转发HTTP/TCP请求,写入到目标节点本地主分片上.
7、主分片写入完成,返回201时,由协调的节点进行结果汇总(其中包含_id值)返回结果给filebeat。(即满足wait_for_active_shards ).
8、副本分片的拷贝工作将会同步运行,但数据存储的工作将以主分片的进度为主.
9、Filebeat接收到节点信息确定数据已经成功发送并存储。将偏移量进行增加记录,以便读取下次的数据和记录已经发送的数据.
至于为什么主分片数量,必须在数据收集前指定且中途不可更改,就是因为主分片的数量参与到了路由寻址上,如果随意更改可能会造成数据冲突,或者数据寻址错误,读取错误等区块。
在源代码位置的server/src/main/java/org/elasticsearch/cluster/routing/Murmur3HashFunction.java中
拥有相关代码说明以及运算方式。
在7.X版本路由计算方法在:
org.elasticsearch.common.hash.Murmur3HashFunction
分配决策在
org.elasticsearch.cluster.routing.allocation.AllocationService.reroute()
Elasticsearch副本分片数据存储方式
主分片都拥有一个shar-id,副本分片对应着,这些shar-id可以拥有多个副本(备份)。
场景说明如下:
Node-A:拥有主分片Shar-id-0
Node-B:拥有主分片Shar-id-1
Node-C:拥有主分片Shar-id-2
那么根据Elasticsearch存储规定,主分片与副本分片一定不会存储在自身的节点上
那么假设设定为主分片数量为1,副本分片数量为2的情况下,就会出现以下存储
Node-A:拥有主分片Shar-id-0,副本分片Shar-id-1,Shar-id-2
Node-B:拥有主分片Shar-id-1,副本分片Shar-id-0,Shar-id-2
Node-C:拥有主分片Shar-id-2,副本分片Shar-id-0,Shar-id-1
在源代码中:
server/src/main/java/org/elasticsearch/cluster/routing/AllocationService.java
decideShardAllocation()
对每个 shard-id 分别跑分配决策器(DiskThresholdDecider、SameShardAllocationDecider 等
在5.X版本以后重构为
路由哈希:org.elasticsearch.common.hash.Murmur3HashFunction
分配决策:org.elasticsearch.cluster.routing.allocation.AllocationService.reroute() → AllocationDeciders.makeAllocationDecision(...)
Elasticsearch索引滚动机制
所谓的索引滚动,即按照一定的规律创建一个新的索引,用于存储新的数据与旧索引和旧数据进行切割
场景如下:
创建数据收集索引:Nginx-2025-1-1
当系统日期发生改变时,创建新索引(当然也可以按照大小切割)
当日期来到2025-1-2的时候,Elasticsearch将会创建新的索引,并将数据传输到新索引上(Filebeat不会同步修改,而是依照发送,滚动修改将由Elasticsearch内部进行)
也就是创建新索引:Nginx-2025-1-2
这就是所谓的索引滚动机制
Tips:若需要自定义索引名字,无需关闭ILM,只要手动创建索引模板和ILM策略并绑定即可;若你不建ILM,滚动仍可由 template+rollover alias 完成。
Tips2:传输器(Filebeat,Logstash)自带默认模板与 rollover alias 策略,未配置时即按此默认组合进行滚动,不强制依赖ILM。
Kibana
Kibana是Elastic Stack的一个可视化工具,因为Elasticsearch本身就类似于个数据库一样,并不提供可视化服务。
端口情况:
5601:用于提供Web服务
9200:它并不开放9200端口,只是说它会去用Elasticsearch的9200端口去操作。
数据展示:通过9200端口去读取Elasticsearch的数据,然后为用户展示Elasticsearch中的数据而已。
管理操作:通过可视化界面可直接对索引生命周期、用户角色、安全策略、告警规则等操作
登录操作:Kibana本身并不提供什么认证服务,它提供一个代理以及管理服务,它负责接收你输入的信息,然后帮你转交给到对应的身份验证服务器(如Elasticsearch,LDAP等)上,认证服务器通过了那就创建你的SESSION在Kibana操作。
提供的功能:TLS 双向加密、Space 多租户、告警 Connector、机器学习画布等功能
登录过程:
用户访问Kibana服务器5601端口服务->输入账号密码登录->Kibana将账号密码发送至认证服务器->认证服务器返回结果到Kibana,确定是否存在该角色->存在登录并生成SESSION凭证->不存在则登录失败
FileBeat
Filebeat是Elastic Stack的一个负责收集信息的产品,它主要是为了解决logstash组件比较臃肿的一个问题,它主打一个只负责收集和发送以及简单的设置。
Filebat程序说明
Filebeat依赖于registery目录下的log.json文件里面记录有File beat到服务端的信息。
一般会存在以下两个文件
meta.json:版本信息 log.json:日志文本
log.json重要字段内容:
offset偏移量:代表着FIlebeat读取到数据采集对象的哪一个地方,File beat每次启用将会读取该值,并从最后一条的偏移量的值,开始读取数据来源对象的信息.
source对象:数据的采集对象,如/var/log/http.log.
Filebeat配置说明
Filebeat主要依赖于yaml语言配置文件来进行数据收集以及发送
整体分为两大块inputs,outputs分别对应输入,输出。
inputs输入:用于指定需要收集那些数据,也可以理解为数据来源。
outputs输出:用于指定将数据输出到哪里,也可以理解为数据输出。
Tips:当然也可以采用官方配置好的文件(属于开箱即用)Modules
Filebeat的输入与输出,均可存在多个实例,也就是说它在同一个文件中指定多个数据来源,同时还能指定多个输出的对象,并且可单独管理。
Filebeat的实例同样拆散的很模块化如
模块化配置文件:Filebeat支持包含多个配置文件,配置文件里面可配置多个输入输出实例
在默认配置文件filebeat.yml下存在modules模板,里面详细指定了filebeat的多个配置文件可存放在哪被读取。
filebeat.config.modules:
path: ${path.config}/modules.d/*yml
可在路径下创建:config.yml config-1.yml 用来配置多个实例
配置项实例:
filebeat.inputs:
- type: filestream #实例类型
enabled: false #是否启动该实例
paths: #数据路径
- /var/log/*log
- /var/www/*log
#多个路径实例
filebeat.inputs:
- type: filestream
enabled: false #是否启动该实例
paths:
- /tmp/test.log
#多个inputs实例
output.elasticsearch:
enabled: false #是否启用
hosts: hosts: ["host-A","host-B"....] #多个主机实例
output.console:
enabled: false
pretty: true
#多个outpus实例
实践
一般来说分布式系统一般建议有三台及以上的主机,但是实际过程中只有一台也不是不行,只是说没有冗余了。
为了容易区分我使用以下三台主机作为演示
192.168.1.1 ---ES服务器,Master节点
192.168.1.2 ---ES服务器+Kibana
192.168.1.3 ---Apache模拟服务器
统一步骤说明
https://www.elastic.co/downloads/past-releases#elasticsearch
到官方网上下载对应的rpm文件,以及压缩文件.tar.gz
ES+filebeat+Kibana的版本最好都一一对应
可在同一台主机上全部下载完,再通告rsync同步到其他主机上,减少下载量
下载完成后将rpm和对应压缩文件,放在同一个目录下使用以下命令进行安装,安装完成后将会添加对应的systemd模块。
yum localinstall xxx.rpm
Elastic Stack集群支持主机名解析,可根据实际需求,修改主机名后在/etc/hosts添加对应的主机关系
ES服务器和ES集群安装
该服务器安装的话有此次选择了两台,但是我只会发一台的配置出来,并标注需要注意哪些事项。
Tips:ES集群和Elastic Stack集群是两个东西,前者由ElasticSearch组成,后者由Elastic Stack所有产品组成
ElasticSearch默认只监听了127.0.0.1和两个端口分别是9200和9300
9200端口:采用HTTP协议,向ES集群外提供服务,与外部进行数据交互。
9300端口:集群内部的组件通信
在8.X版本默认启用了安全验证,第一次启动ElasticSearch时会打印随机密码以及账户用于验证登录
下列开始介绍配置文件,我只会介绍一些常用配置和功能,ElasticSearch支持的功能非常多,可以阅读官方英文手册进行查看
ElasticSearch的两个文件比较重要
elasticsearch.yml : ES集群配置文件
jvm.options:Java 虚拟机的调优
#elasticsearch.yml
#集群名称
#cluster.name: my-cluster
#节点名称
#node.name: node-1
#节点属性
#node.attr.rack:r1
#数据路径
path.data: /var/lib/elasticsearch
#日志路径
/var/log/elasticsearch
#内存锁
#bootstrap.memory_lock:true
#监听网络主机(默认只能访问本机) 0.0.0.0代表全部
#network.host: 192.168.0.1
#HTTP监听端口(默认9200)
#http.port: 9200
#自动发现(当ES自动启动的时候,会去读取这些主机列表,去发现其他的集群主机,可以是主机名也可以是IP)默认是127.0.0.1
#discovery.seed_hosts:["host1","host2"]
#初始化的Master服务节点(少配置这个节点,那其他的ES就不会进行初始化,就不会生成集群UUID)
#cluster.initial_master_nodes:["node-1","node-2"]
#集群部署的时候需要改动以下选项
#生产环境下建议将path.data path.log更换一个路径,确保数据检查的时候不会将一些奇怪的数据转发
#配置集群名,确保集群名相同,否则ES将不能识别到其他的主机
cluster.name: ESS
#节点名(确保节点的节点名不一样,不然会冲突)
node.name: elkA
#网络监控(监控全部网卡)
network.host: 0.0.0.0
#节点配置,将所有ES节点都放置进这里,包括自身。可以是IP也可以是主机名(需要配合hosts),建议使用IP
discovery.seed_hosts: ["host-A","host-B","host-C"]
#初始化的Master服务节点
cluster.initial_master_nodes: ["host-A","host-B","host-C"]
#安全认证机制,若是有一个节点关闭了此选项,就要将所有节点关闭,否则会造成通信和数据交流问题。此选项同样会应用到集群内部通信中,不仅仅是外部通信。
xpack.security.enabled: enable
#可以在shell里使用以下命令检查配置文件
#egrep -v "^#|^$" elasticsearch.yml
#给出本次示例代码,若未改动的按照配置文件默认即可
cluster.name: ESS
#节点名(确保ABC节点的节点名不一样,不然会冲突)
node.name: elkA
#网络监控(监控全部网卡)
network.host: 0.0.0.0
#节点配置,将所有ES节点都放置进这里,包括自身。可以是IP也可以是主机名
discovery.seed_hosts: ["192.168.1.1","192.168.1.2"]
#初始化的Master服务节点
cluster.initial_master_nodes: ["192.168.1.1","192.168.1.2"]
#使用以下命令检查配置文件
#egrep -v "^#|^$" elasticsearch.yml
将192.168.1.2,192.168.1.1两台主机进行配置后,我们可以通告以下命令进行查询节点是否已经连接
curl -k -u elastic:<password> https://localhost:9200/_cat/nodes?v
Kibana
Kibana属于是开箱即用的一个组件,它原本的定位是在为elasticsearch提供可视化的界面,但随着它的插件越来越多以及ELK官方对于ELK日志审计系统的一个发展偏向,它提供的功能也越来越多。如安全插件,云计算插件,本次只关注于ELK本身的日志系统,并不在此方面拓展更多。
它本身就只提供了可视化界面,并不涉及到数据的相关管理,可以理解为类似于一个phpmyadmin的东西。
因此哪怕是它也是需要访问ES集群读取数据的,那么安全认证方面也是需要配置的
#kibana.yml
#服务的端口号
#server.port: 5601
#kibana绑定的地址(用于访问服务,IP地址或主机名都可以)0.0.0.0绑定全部
#server.host: localhost
#kibana服务名称
#server.name: "your-hostname"
#配置elasticsearch的地址,用于访问数据(可配置多节点)
#elasticsearch.hosts: ["http://localhost.com:9200"]
#elasticsearch.hosts: ["http://hostA.com:9200","http://hostB.com:9200","http://hostC.com:9200"]
#kibana索引,用于存储在ES中的索引
#kibana.index: ".kibana"
#ES的安全验证配置
#elasticsearch.username: "kibana_system"
#elasticsearch.pass: "pass"
#SSL加密用于配置HTTPS访问
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.keu
#PID文件存储
#pid/file: /run/kibana/kibana.pid
#国际化语言("en=english,zh-CN=Chinese")
#i18n.locale: "en"
菜单界面说明以及注意事项
堆栈监测:输入集群或者让kibana自动监测ES上的集群信息,可以查看相关配置和信息(节点,使用率等等)
stack manager->索引管理
隐藏索引不要去删除会造成不必要的麻烦(以.开头的索引=隐藏索引)
stack manager->索引模式
该模式用来查看索引中的数据,选择创建索引,选择你想看哪个索引里面的数据即可
名称:就是选择对应索引的意思,也可以用通配符
时间戳字段:@timestamp 这个字段是filebeat默认自带的,一般选这个
Discover:
在索引模式创建完成后,可以通过这个地方查看刚刚创建的索引数据
可以查看到索引里面的字段,也可以通过这些字段给你裂开
Filebeat
Filebeat需要关注两个点output,input,具体采集流程由图以下
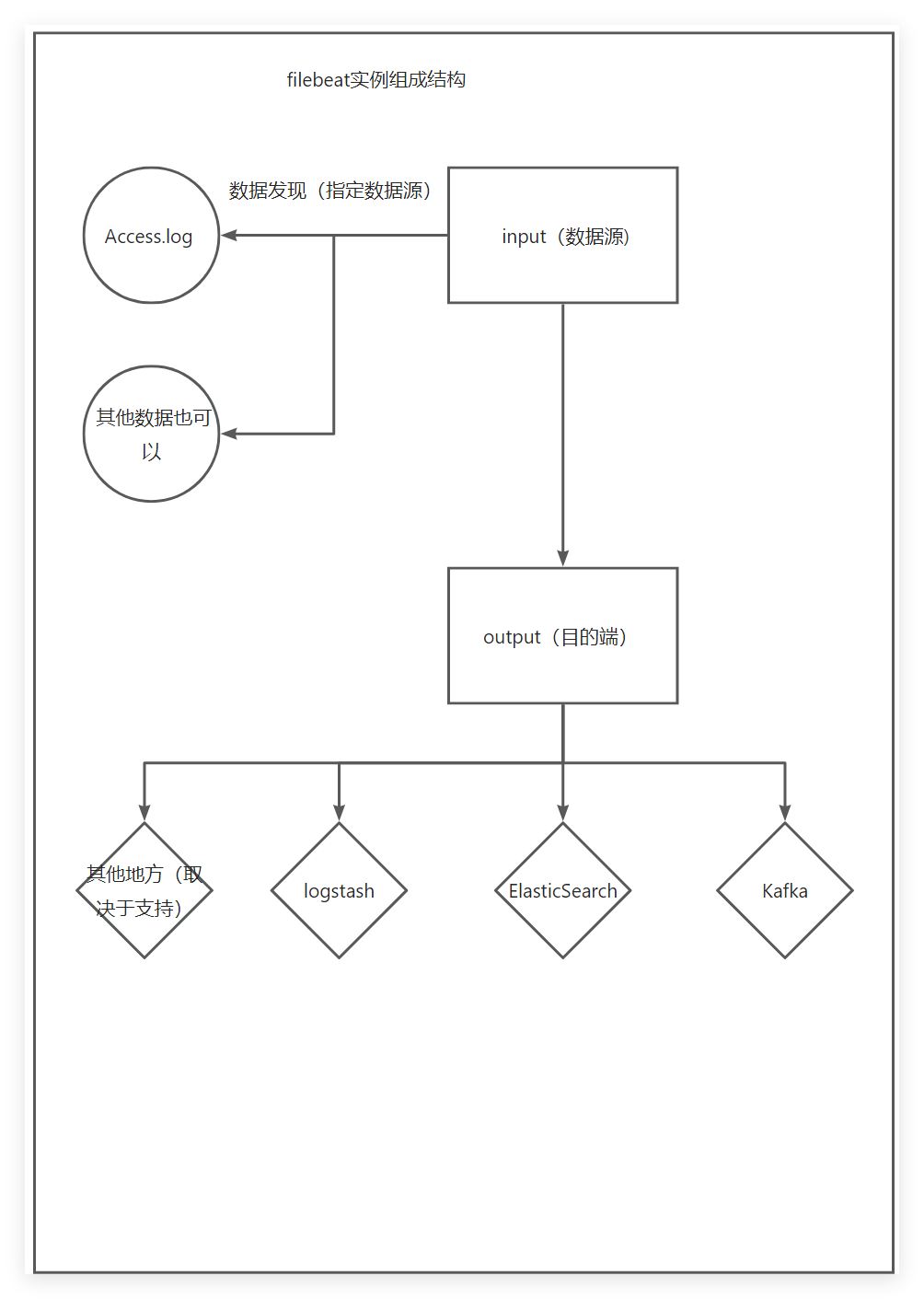
input:数据的来源。
output:输出到哪个地方,也就是将采集到的数据输出到哪里。
##Filebea的Systemd单元
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch
Documentation=https://wwww.elastic.co/beats/filebeat
Wants=network-online.target
After=network-online.target
[Service]
Environment="GODEBUG='madvdontneed=1'"
Environment="BEAT_LOG_OPTS="
Environment="BEAT_CONFIG_OPTS=-c /etc/filebeat/filebeat.yml"
Environment="BEAT_PATH_OPTS=--path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs"
ExecStart=/usr/share/filebeat/bin/filebeat --environment systemd $BEAT_LOG_OPTS $BEAT_LOG_OPTS $BEAT_PATH_OPTS
#说明:
#可以见当filebeat启动的时候携带了三个参数分别是BEAT_LOG_OPTS BEAT_CONFIG_OPTSBEAT_PATH_OPTS
#其中BEAT_LOG_OPTS默认为空
#BEAT_CONFIG_OPTS是filebeat配置文件
#BEAT_PATH_OPTS是启动选项
#BEAT_PATH_OPTS中的path.log,path.home,path.data,path.config都可以通过filebeat命令进行指定,指定完成后会同步到service文件
[Install]
WantedBy=multi-user.target
#切割符号---------------------------------
#在生产环境中最好使用systemd去管理filebeat,它启动的时候会去读取BEAT_CONFIG_OPTS
#也就是/etc/filebeat/filebeat.yml文件
#filebat.yml默认配置文件
filebeat.inputs:
- type: filestream
enabled: false
paths:
- /var/log/*log
filebeat.config.modules:
path: ${path.config}/modules.d/*yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.elasticsearch:
hosts: ["localhost:9200"]
processors:
- add_host_metdata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
Filebeat并不需要什么默认模板,它是根据实际业务需求进行的制定的一个文件,它取决于你想要采集什么,读取什么,以及发送到哪里,以下我给出通用字段以及一些说明
#多个实例,以及是否启用写法
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
- /tmp/*.txt
- type: log
enabled: true #是否启用该字段进行日志收集,默认为True
paths:
- /tmp/test/*/*.log
output.console:
pretty: true
#以上代表着定义了两个log,enabled代表着该log实例是否启用,filebeat支持通配符
#output.console代表着不发送数据,只是打印出来
#-------------------------------------------------------------------------
#以下为标签实例,在向ES发送数据的时候,会附赠你定义的标签,用于区分
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["mysql-test","标签2"]
output.console:
pretty: true
#--------------------------------------------------------------------------------
#自定义字段,因为ES可以根据字段去查找数据,tags只是加上标签并不是加上字段
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["mysql-test","标签2"]
#为数据添加location、datatype类型,到时候在ES上即可通过location或者是datatype进行筛选
#具体定义location还是其他,看具体个人场景需求,可以自定义自己需要的字段
fileds:
location: "beijing"
datatype: "Test"
fields_under_root : true
output.console:
pretty: true
#fields_under_root 设置顶级字段默认为false
在上面的实例中最终传送的数据可能是
filds : {
"location":"beijing"
"datatype":"Test"
}
如果设置了fields_under_root
则会变成以下这样,也就是删去了filds组,让这些字段变成一个独立字段
"location":"beijing",
"datatype":"Test"
#console打印调试
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
output.console:
pretty: true
#输出到ES
#console打印调试
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
#以下选项如果没打#号在前代表必填项,#号代表可选项,需要根据实际情况进行填写
output.elasticsearch:
# enabled:false #是否启用该字段,默认为true
hosts: ["host-A","host-B"....]
# hosts: ["https://host-a.com:9200/elasticsearch]
#选择使用的协议默认是http
# protocol : https
#若开启了安全认证则需要添加以下两种1、账号和密码;2、Api_key,根据实际需求启动
# username: "filebear_write"
# password: "Your_Password"
# api_key: "Your_Apikey"
#若需要进行证书加密则可以添加
# ssl.certificate: "/etc/pki/client/cert.pem"
# ssl.key: "/etc/pki/client/cert.key"
#索引管理
#索引管理指这个这些收集到的信息,将存储到哪个索引上,默认是filebeat+版本信息+年月日
#如果启用了索引生命周期(默认情况下是启用的),那么index字段将不会生效
# index: "%{[fields.log_type]}-{[agent.version]}-%{+yyyy.MM.dd}"
#生命周期管理
#enabled:true/false/auto 选择是否开启生命周期
# setup.ilm.enabled: auto
#rollover_alias: 规定模板使用哪一个 如果设置为true那就代表着使用自动预制模板
# setup.ilm.rollover_alias: "filebeat"
setup.ilm.pattern: "{now/d}-000001"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号