
TraceFS-文件追踪系统
小说明
TraceFs文件追踪系统,是一个Linux提供的内核追踪功能交互的统一接口,系统性能分析和问题诊断工具
这个文件系统比较特殊,它不是传统意义上存在于物理硬盘上的文件系统。它是Linux内核运行起来后基于内存创建的系统。因此如果系统未开启该功能的情况下,需要重新编译内核。
基于我查找到的资料它是最早于Linux(3.10+)版本2014年引入到内核之中,在Linux(4.1)之前它是挂载在debugfs下。
查看是否支持Tracefs以及查看它的挂载位置
查看是否支持Tracefs
grep -i tracefs /proc/filesystems
如果支持的话会提示
nodev tracefs
查看挂载位置
Linux 4.1后的路径一般是:
mount | grep tracefs
tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
Linux 3.10 ~ 4.1的路径一般是:
mount | grep tracefs
/sys/kernel/debug/traceing
TIPS:可能路径上会有所差别请以具体为准
功能说明(功能太多了,就先写一点后续再慢慢写)
在/sys/kernel/tracing下有许多的目录,每个目录里面有对应不同的功能,详细可以看README(英文的做好心理准备)
以下的说明均以"名字(类型):说明" 格式进行说明
events(目录):跟踪事件目录,其中包含已编译到内核中的事件追踪点(静态的)它显示了Tracefs提供了哪些事件追踪点,并如何按系统分组。里面提供了enable文件,当enable文件的内容为1的时候会启用。
hwlat_detector(目录):硬件延迟检测器的目录
使用与界面说明
tracefs 提供了一些命令可以直接管理节点的启用并生成可阅读形式的报告
trace-cmd
-h,--help 子命令级帮助,比如trace-cmd record -h
-v,--verbose 将所有信息全部打出来包括trace-cmd自己
-q,--quiet 静默模式,脚本用的
-N,--no-splash kernelshark打开trace时去掉启动画面
###子命令选项
record ---记录阶段(最常用的)
-e,event 指定记录的事件(可以指定多个事件 -e syscalls -e sched_switch
-p,plugi 选择trace:function_graph,wakeup_rt等
-l GLOB / -n GLOB 只跟踪/排除匹配统配的函数名(-l 'tcp_*')
-f FILTER 事件及过滤(-e syscalls -f 'common_pid == 6020'
-F 只跟踪当前shell子进程
-P PID 只跟踪给定进程
-c clock 换时间戳始终,比如(-c mono)用单调时钟
-o FILE 文件输出将dat文件输出到别处
-s 同时记录符号表,report报告的时候行号更精确
--date 把wall-time也写进去,用于和系统日志对齐
-m SIZE[M|G] 唤醒缓冲区大小限制,防止把硬盘撑爆
-M CPUMASK 只在指定CPU上记录 (-M 0xf) 只看前四核
###report 报告查看
-i trace.dat 指定查看某个dat文件的报告
-F 只打印事件字段,不显示默认标题
-w 款输出,避免字段换行
-n 不解析符号,直接打印地址(调内核模块kallsyms不对时有用)
-s 打印事件对应的函数栈(-s depth指定深度)
-f FORMAT 自定义列输出,跟printf一样用
###start/stop/extract(启动,停止,导出) 在线监测
主要用于后台监测,类似于服务那种
trace-cmd start -e block -p function_graph -l 'ext4_*'
trace-cmd stop
trace-cmd extract -o ext4.dat
###杂项帮助
listen 远程,我没用过
trace-cmd listen -p 8080
-p 端口 -D daemon化 -k杀掉守护进程
split 大文件切割
trace-cmd split -c 100M trace.dat
stat 统计信息
trace-cmd stat -i trace.dat 统计CPU事件分布,事件丢失情况,缓冲区溢出次数
snapshot 快照
trace-cmd snapshot -s 触发快照
配合trace-cmd record --snapshot 使用
reset 清空
将配置清空为0
check-events 查看可用事件
trace-cmd list -e |grep block
简单的使用与界面说明
trace-cmd record -e syscalls #监测系统调用,这时候会在前台挂住,CTRL+C结束
在监测是会产生大量的文件,请勿直接查看,在结束之后会在当前目录下汇总为.dat文件
trace-cmd report #读取当前目录下的.dat文件里面的信息
界面说明
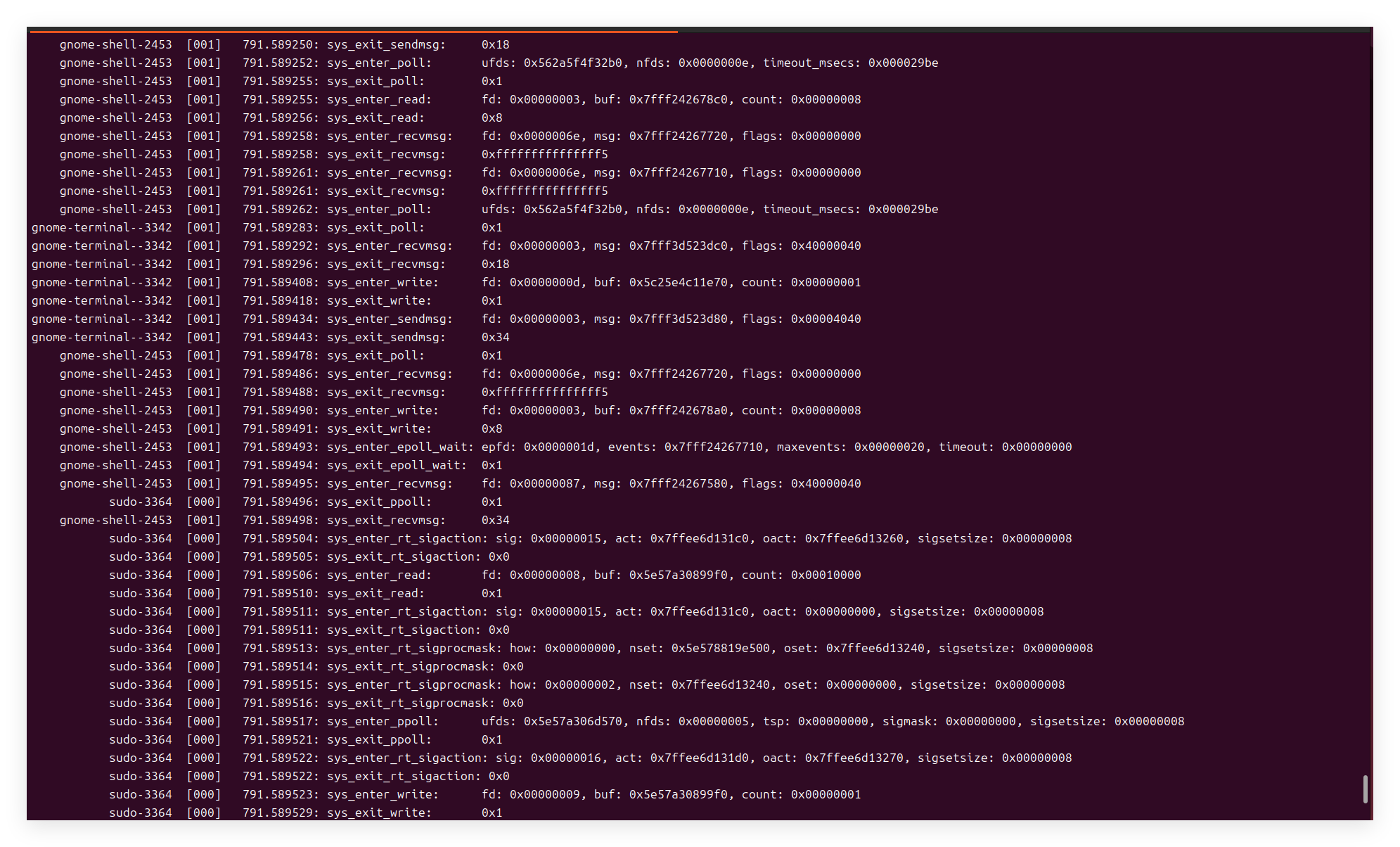
我截取一段说明,后续放一张图
gnome-terminal--3342 [001] 791.589292: sys_enter_recvmsg: fd: 0x00000003, msg: 0x7fff3d523dc0, flags: 0x40000040
gnome-terminal--3342 [001] 791.589296: sys_exit_recvmsg: 0x18
gnome-terminal--3342 代表着程序名:gnome-terminal PID:3342
[001]:CPU核心1
791.589286:接到该指令的时间
sys_enter_recvmsg: 即将进行recvmsg调用
fd:0x00000003:socket标识为0x00000003
msg:0x7fff3d523dc0:栈区地址0x7fff3d523dc0
flags: 0x40000040:特殊标识符
第一行代码的意思是:
时间:791.589292发生事情
公共区域(用户态)的gnome-terminal,证件号是3342,通过服务机器人(CPU01),请求内核服务员recvmsg在(FD)0x00000003有我的物品,请recvmsg将物品拿到公共区域(用户态)的暂存柜(msg)0x7fff3d523dc0放置好给它,要求进行额外的处理(flags)
第二行代码:
在791.589296
内核服务员recvmsg已经通过服务机器人(CPU01)将gnome-terminal的物品(大小在18字节)放置到它所要求的位置
总计耗时为791.589296-791.589292=0.000004秒
一个简单的大图
个人对这套系统的设计理解与总结
总的来说我个人觉得这个系统的设计一个是动用到了汇编指令,而且是动态修改或者监测具体我也不清楚,就当检查到enable=1的时候,会进行JMP跳跃到记录点, 然后记录点通过JMP再跳跃回到正常的执行程序之中。这样子就能进行数据劫持来进行记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号