[论文阅读] IF-Font@ Ideographic Description Sequence-Following Font Generation
Pre
title: IF-Font: Ideographic Description Sequence-Following Font Generation
source: NeurIPS 2024
paper: https://proceedings.neurips.cc/paper_files/paper/2024/hash/19ded4cfc36a7feb7fce975393d378fd-Abstract-Conference.html
code: https://github.com/Stareven233/IF-Font
关键词: Font Generation, Vector Quantization, Image Synthesis
阅读理由: 这个领域第一篇发在nips上的(大概)?这不得好好看看
Motivation
目前的字体生成方法大多依赖图像翻译(Image-to-Image Translation)领域的方案,即假设字形能够被解耦为内容风格特征,并通过组合源字形的内容特征与参考字形的风格特征来生成目标字形。虽然随着扩散模型的加入,大力出奇迹逐渐抹平了方案的缺点。但作者指出,解耦的假设并不完全适用于字形。与普通图片不同,字形更加细腻且笔画的微小变化可能直接影响语义,导致解耦难以实现彻底。例如连笔/衬线导致的笔画是算作内容还是风格?在这种情况下,源字体风格会泄露到生成结果中。常常导致生成的字形看起来只是在源字形的基础上调整了笔画粗细,甚至出现笔画残缺。
现有方法在引入笔画或组件信息以提高生成质量的同时,也带来了一系列局限性。例如FS-Font要求参考字形的笔画或组件集合必须能够完全覆盖目标字形的所有组成部分,例如,在生成目标汉字“橙”时,系统需要参考字形中包含“木”和“登”这两个关键组件,或者它们的具体笔画结构。这种严格的要求往往导致目标字形与参考字形必须一一配对,使得生成过程对输入的参考字形具有较高的依赖性,也限制了用户在推理阶段的灵活性。
Idea
本文提出了一种新的结构化字体生成范式,称为表意文字描述序列引导的字体生成(IF-Font)。通过采用表意文字描述序列(Ideographic Description Sequence (IDS))为输入,取代了传统方法中使用的源字形,直接抛弃了内容风格解耦。
Background
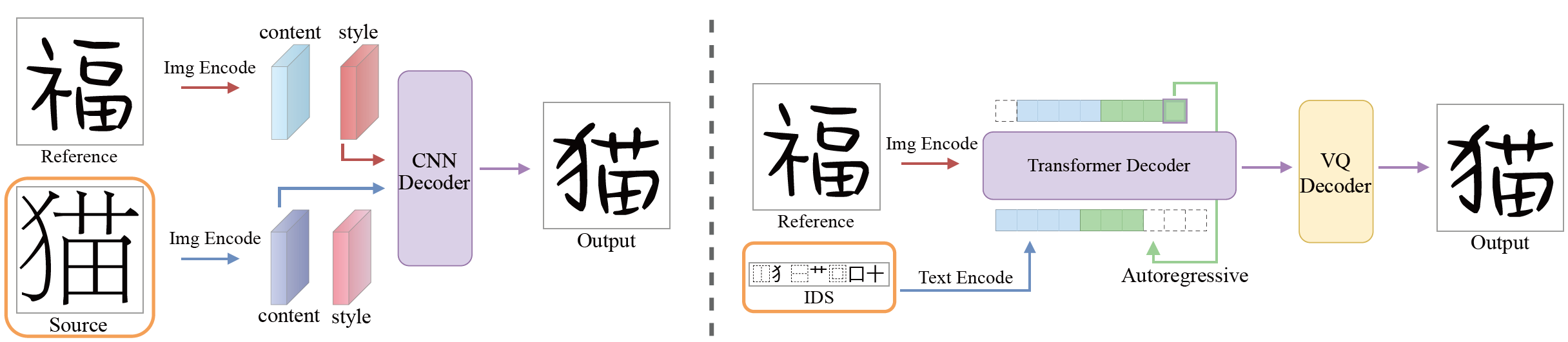
图1 两种字体生成范式对比。左侧:风格内容解耦范式,它假设字形总能分解成内容和风格两个独立的特征。右侧是本文提出的范式,差别在于本文将源字形替换为IDS来控制目标字形的语义(橙色框),先自回归地预测目标字形对应的token再用VQ解码器进行解码。
字体生成的核心在于根据某种字体的部分参考字形提取风格,进而生成相同风格的其余字形。一些语言例如汉语、日语、朝鲜语等,文字数量很多,字形结构复杂,字体生成可以显著减轻字体设计师的劳动强度,同时在笔迹模仿、古籍修复和影视作品国际化等任务中都能发挥作用。
EMD与SA-VAE认为可以组合源字形的内容特征与参考字形的风格特征来生成目标字形,如图1(左)所示。后续工作(CalliGAN、LF-Font、FS-Font、CG-GAN、CF-Font)大多延续了这一范式,但这使得字体生成成了图像翻译的子任务,通过对源字形进行变形,使之贴合参考字形的风格,而非“生成”。由于字形结构复杂,其风格与内容特征很难有明确的边界。这导致解耦策略生成的字形通常只有笔画粗细与参考字形一致,而在空间结构、大小、倾斜度等方面都更接近内容字体。
为此DG-Font引入可变形卷积来更好地捕捉局部风格特征;XMP-Font用字形和对应笔画进行预训练,提高解耦的程度和风格表达的质量,Diff-Font、FontDiffuser引入扩散模型提高网络的学习能力;还有一些方法(LF-Font、XMP-Font、FS-Font、CG-GAN)进一步结合笔画、部件等细粒度的先验信息来提升生成质量;CF-Font挑选多个基础字体,并根据基础字体和目标字体的相似度通过加权平均的方式得到内容特征,降低风格转换的难度。
这些方法虽然都带来了一些生成质量的提升,但它们本质上只是对原方法的改良,当内容字体与目标字体相差较大时,仍无法胜任生成任务。而本文不再使用源字形,而是改用IDS来提供内容信息。这基于一个简单的事实:不对特征进行解耦就不会有解耦不彻底的问题。从而字体生成就转变为序列预测问题,也就是根据给定的IDS与参考字形来生成目标字形的tokens。这样不仅避免了源字形对生成结果的干扰,还能借助量化的codebook包含的先验信息减少伪影。用户可以自行构造IDS来创造不存在的汉字,例如和制汉字,只要在训练时学习过构成该字形的结构和部件。这赋予了模型一定的跨语言能力。
Image-to-image translation
图像翻译(I2I)旨在学习源域到目标域的一种映射,要求在保留内容的前提下将源域的图片转换到参考风格所在的目标域。Pix2Pix使用配对的数据训练GAN,是第一个I2I方法。CycleGAN通过循环一致损失实现了无监督训练,但它一次训练只能处理两个域之间的转换。
UNIT约束来自两个域的图片编码后的隐变量一样,并且用不同的生成器负责不同域的图片,该过程其实就隐含着解耦的思想。MUNIT将UNIT的隐变量进一步细化为内容编码和风格编码,用不同风格编码搭配同一内容编码就能实多模态(Multimodal)的生成。DRIT的思想与MUNIT类似,但它并非使用AdaIN而是通过简单拼接或逐元素特征转换来结合解耦出来的特征。CDD, cd-GAN, CD-GAN同样应用了内容风格解耦的思想,FUNIT则更进一步,训练仅使用源类的数据,推理时以目标类的少数图片集作为参考。
虽然套用图像翻译框架进行字体生成是目前的主流做法,但作者认为这是不合适的。与常规图片不同,字形的内容和风格界限模糊。例如相同的字由不同书写者写下笔迹肯定不同,但语义不变。既然字形特征很难解耦,干脆使用不含风格的IDS来确定字符,避免解耦不到位导致内容字形对生成结果的风格产生影响。
Few-shot font generation
少样本学习是目前字体生成的主流研究方向,它希望只通过少数几个参考字形就模拟出目标字体的风格。根据是否使用字形中隐含的结构信息,可以将字体生成方法分类两类。将字形视为一般图片的方法能泛化到不同语言字形的生成上,而使用结构信息的方法通常生成质量更好,但只局限于特定语言。
在不使用字形结构信息的方法中,EMD是最早将字形解耦为内容与风格特征的方法。DG-Font使用可变形卷积捕捉字形形变。FontRL另辟蹊径,通过强化学习来绘制汉字的骨架。NTF将NeRF用于建模不同字体。CF-Font选取了最具代表性的几种基础字体进行内容融合。VQ-Font使用字形图片预训练VQ-VAE,并将其码本用于表示字形部件。FontDiffuser则是借助扩散模型的强大性能,强化了对复杂字形的生成质量。
对于使用字形结构信息的方法,SA-VAE使用了汉字的部首和空间结构。CalliGAN使用Zi2Zi的框架,它将汉字完全分解成了部件序列。SC-Font进一步将汉字分解到笔画粒度。为了能泛化到未知部件,DM-Font提出双存储不断更新字形部件特征。受低秩矩阵方法启发,LF-Font通过部件因子和风格因子的乘积来表示部件级风格。MX-Fon通过多个局部专家自动抽取特征。FS-Font要求参考字形覆盖目标字形的所有部件,当它的内容参考映射无法满足时生成质量很差。CG-GAN用GRU和注意力机制预测字形对应的部件序列,并结合大量损失函数向生成器提供细腻反馈。XMP-Font将汉字的笔画序列和字形图片一起进行多模态预训练,从而减少了生成字形结构缺失的情况。
本文观察到上述方法大多仍受制于内容风格解耦范式,虽然有方法引入了汉字的组件信息却都忽略了表意文字描述符(IDC)即汉字的空间结构,无法避免伪影和风格模仿不到位的问题。
Vector quantized generative models
向量量化(Vector Quantization, VQ) 通常遵循两阶段的训练方案。它依赖一个码本来记录并更新向量,将向量从连续的特征空间转换到离散隐空间;然后用解码器建模量化向量的分布,从而预测token,也是码本索引,并将token还原回图片。
VQ-VAE最早将量化引入变分自编码器框架,借助STE操作,它学习将编码特征中的每一个向量用码本中最接近的向量进行替换。VQ-VAE对特征进行多尺度量化,并引入拒绝采样(rejection sampling)来缓解自回归的积累误差。VQGAN借助GAN来学习码本,然后用Transformer替换了VQ-VAE使用的PixelCNN。RQ-VAE提出残差量化器,将单个向量表示为有序且共享的码本中的多个编码。BEiT将图片分别通过量化和划分块得到两种视图,然后在图像块上进行掩码图像建模(MIM),并使用视觉token进行监督。MaskGIT直接在视觉token上进行建模,并提出并行解码极大减少了token预测所需要的步骤数。MAGE类似MaskGIT,但引入了ViT和对比学习。DQ-VAE进一步用可变长度的token来编码图像,使量化更加精确和高效。
因为量化相当于对图片进行tokenize,前面的方法都针对图片这单一模态,实际上也有不少方法尝试进行多模态生成。DALL-E提出的 dVAE 不像VQ-VAE那般迫使模型将向量量化为单一token,而是藉由gumbel-softmax将离散采样问题放松为连续近似,输出所有码本向量上的概率分布。SEED设计因果Q-Former提取图片嵌入再进行量化,与DALL-E一样将图片与文本token拼接后做自回归,并提出图片到文本和文本到图片两个任务来增强LLM的能力。为了避免DALL-E、SEED那样微调或从头训练语言模型,LQAE训练VQ-VAE把图片直接量化到冻结的LLM码本空间,但仅支持英文词汇表,而且重建质量不如采用可学习码本的方案。SPAE引入多层且粗到细的金字塔结构和CLIP的语义引导,各自与独立的冻结codebook关联。V2L进一步提出全局和局部量化器,支持多语言词汇表,超越了VQGAN的重建质量。
本文对向量量化的使用有两处。为了使字形兼容表意文字描述序列,使用了向量量化对图片进行tokenize。考虑到表意文字描述序列不存在现有的预训练模型,因此本文像DALL-E那样将视觉token的码本视为词汇表,并训练Transformer解码器对其进行自回归预测。此外还冻结了预训练的向量量化模型的编码器部分,与其他模块一起进行训练,利用了其码本中已学习到的鲁棒特征。
Method(Model)
Overview
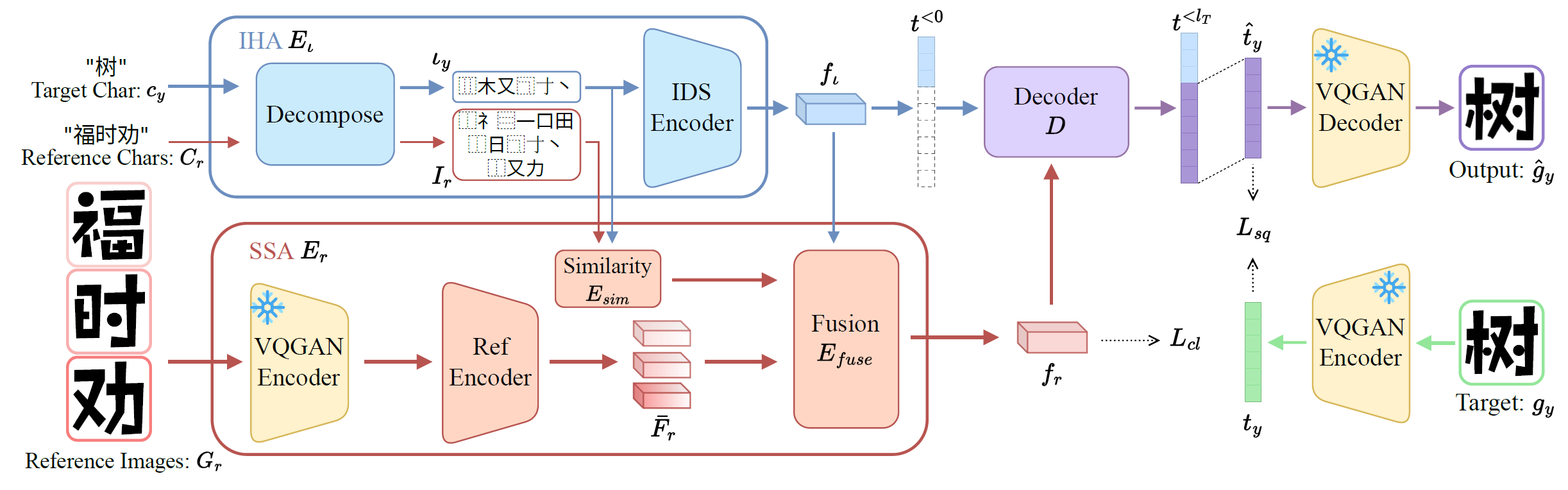
图2 所提方法的概述。框架主要由三个部分构成:IDS层次分析模块$E_\iota$、结构风格汇聚模块$E_r$和一个解码器$D$。
给定目标字符\(c_y\)、参考字符\(C_r = \{c^i_r\}^k_{i=1}\)和参考字形\(G_r = \{g^i_r\}^k_{i=1}\),模型的目标是生成符合\(c_y\)语义且风格与\(G_r\)保持一致的字形\(\hat{g}_y\)。为此用IHA分析\(c_y\)得到它对应的IDS\(\iota_y\),并进一步将其编码为语义特征\(f_\iota\)。类似地,可以得到\(C_r\)对应的IDS\(I_r = \{\iota^i_r\}^k_{i=1}\)。随后应用相似性模块\(E_{sim}\)分析\(\iota_y\),\(I_r\)之间的联系。综合\(f_\iota\)和\(E_{sim}\)的输出,在SSA模块中将\(G_r\)对应的一系列特征\(\bar{F}_r\)融合为最终的风格特征\(f_r\)。将\(\iota_y\)变形为初始标记\(t^{<0}\),然后跟\(f_r\)一起输入解码器进行自回归建模,最后将预测的字形标记用预训练的VQ模型进行解码即可得到生成字形\(\hat{g}_y\)。
IDS Hierarchical Analysis

图3 等价IDS的示意图
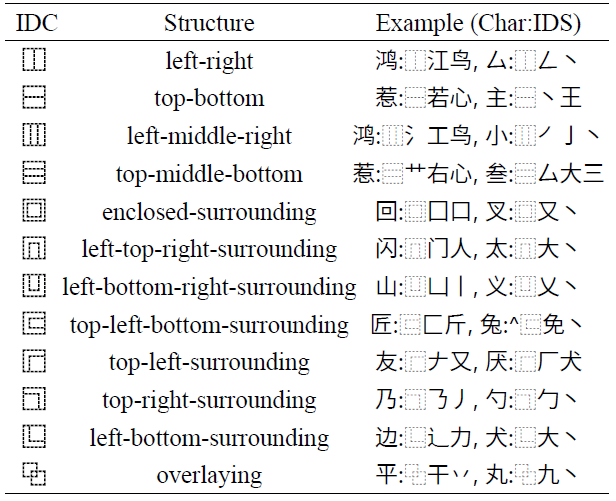
表1 本文使用的12种IDC示例
表意文字描述序列是一种通过前缀表示法将汉字分解为基础组件的技术,如图3所示。它不仅能够显著精简词汇表规模,还使得具有相同结构或组件的汉字可以共享特征。鉴于本章希望抛弃风格内容解耦范式,除了用源字形作为语义输入,有一个很直接的想法就是直接用字符本身来控制生成结果的语义。但中文里有成千上万个汉字,而且各个字符互相独立,这种方式的开销过大且忽视了汉字的结构信息,导致模型学习困难。表意文字描述序列是Unicode标准定义的汉字结构描述语法,它由表意文字描述符(Ideographic Description Character (IDC))与基础组件(主要为汉字)通过前缀表示法组合而成。通过将汉字分解为对应的IDS,不仅可以大大精简词汇表,而且具备相同结构或组件的汉字也能共享部分特征。但事实上汉字与IDS并非双射关系,一个汉字可能有多个等价的IDS。同时IDC的分布并不均衡,许多汉字都是上下或左右结构,使整体数据呈现出长尾分布的特点,给模型学习造成了困难。
为了解决这些问题,本节提出了一种创新性的表意文字描述序列层次分析方法(IDS Hierarchical Analysis, IHA)。该方法的核心思想是:当提取汉字的IDS时,并非简单地依赖预定义的分解表,而是深入分析汉字的结构特征。具体而言,对于具有左中右或上中下复合结构的汉字,系统会识别其潜在的可分解性,并通过随机选取的方式生成多个等价但不同的IDS表示。这种基于结构分析的动态生成机制不仅增加了数据的多样性,还有效缓解了模型面临的长尾分布问题。在具体实现层面,首先将输入汉字\(c_y\)和参考汉字\(C_r\)分别分解为\(\iota_y\)和\(I_r\)。随后,在IDS编码器中,将\(\iota_y\)统一填充至最大序列长度\(l_I\),并将其转换为对应的语义特征\(f_\iota \in \mathbb{R}^{l\times c}\)。这一过程确保了模型能够有效地从汉字结构中提取丰富的语义信息,同时保持计算效率。
Structure-Style Aggregation
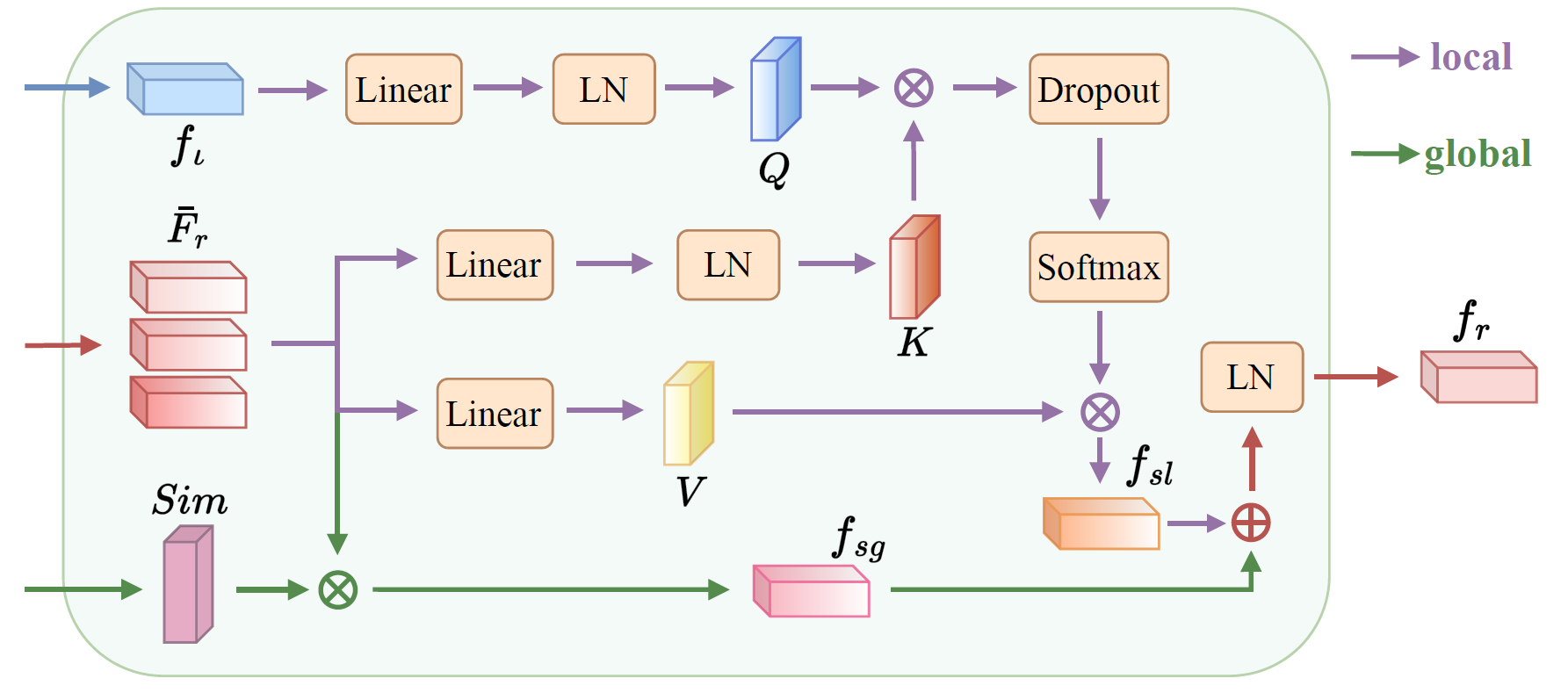
图4 结构风格汇聚块里融合模块的示意图
以往的方法(MF-Net, DG-Font, CG-GAN, XMP-Font, NTF, fontdiffuser)大多在提取参考字形的风格时缺少与目标字符的交互,这样抽取的风格特征将缺少针对性,未必适合目标字形的生成。通常来说参考字符与目标字符的越相似则生成过程越容易维持风格,理想的情况就是使用目标字形作为参考,也就是自重建,此时模型应有最好的生成效果。FS-Font试图让参考字符覆盖目标字符的所有部件,但它的实现依赖于预先定义的内容参考映射表,缺少灵活性。
为此提出了结构风格汇聚模块,如图2左下方所示,本模块主要涵盖三个核心组成部分:相似性分析模块\(E_{sim}\)、全局风格汇聚分支和局部风格汇聚分支。我们将输入的参考字形图片\(G_r\)转换到VQGAN的隐空间中,然后再将其逐个编码为对应的粗糙特征\(\bar{F}_r = \{\bar{f}^i_r \in \mathbb{R}^{h\cdot w \times c}\}^k_{i=1}\)。
相似性模块\(E_{sim}\)可以分析出各个参考IDS\(I_r\)与目标IDS\(\iota_y\)的相似之处,是否包含相同的部件或结构,并输出相似度权重\(Sim = \{sim^i \in \mathbb{R}^{1}\}^k_{i=1}\),用于指导后续的特征融合。特征融合模块分为全局和局部风格特征汇聚两个分支,如图4所示。全局特征主要关注字形的布局、笔画粗细以及倾斜度等,借助上一步获取的相似度权重\(Sim\)汇聚粗糙风格特征\(\bar{F}_r\)可得:
而局部特征更关注笔画,例如笔画长短、笔锋等细节,使用交叉注意力以根据目标字符的需要汇聚所需的风格特征:
其中\(\mathrm{flatten^2}(\cdot)\)表示将特征前两维展平,\(\mathrm{L_q}, \mathrm{L_k}, \mathrm{L_v}\)是线性投影,\(\mathrm{LayerNorm}(\cdot)\)表示对其中的特征进行层归一化。基于公式上述两个公式可以得到汇聚的风格特征,其中\(\circ\)表示拼接操作:
Style Contrast Enhancement
由于推理时的字体风格通常是训练中未遇到的,为了确保字体风格转换的准确性,许多工作会使用一些技巧,例如对参考字形提取的风格和生成字形提取的风格特征计算一致性损失[MF-Net,CG-GAN]、增加判别器判断生成字形所属的风格标签[CG-GAN,FS-Font,VQ-Font],甚至将提取风格特征当做变量,进一步用参考字形去优化它[CF-Font]。这些技巧确实能对生成质量改善带来一定帮助,但是它们较为生硬或额外增加了参数。
提出了一种简化方法叫风格对比增强模块,它鼓励相同风格表达更接近,不同风格的表达更远离。为了计算对比损失,在SSA模块后面接了一个输出头,负责将特征投影到合适的维度。经过该输出头可以得到对比特征\(e = MLP(f_r)\)。在一个batch中,将其中所有样本对应的对比特征下标集合记为\(E_* = \{i \in \mathbb{N} \mid 0 \le i < 2N\}\),其中\(N\)表示批大小。
由于采用了动量编码器[MoCo],因此\(E_*\)的元素数量是批大小的两倍。对于batch中任意一个样本\(x_a\),它会分别通过编码器和动量编码器,得到两个输出特征。这两个特征互为正样本,以保证batch中不存在相同字体字形时仍能计算对比损失。batch中与\(x_a\)风格不同的样本则作为负样本,令\(s(\cdot)\)表示获取字形对应风格的操作符。负样本集合为\(E_- = \{i \in E_* \mid s(x_i) \neq s(x_a)\}\),而正样本集合为\(E_+ = \{i \in E_* \mid i \neq a, s(x_i) = s(x_a)\}\),可以计算对比损失如下:
Generation
解码器\(D\)接收语义特征\(f_\iota\)和风格特征\(f_r\),将\(f_\iota\)作为初始token,即\(t^{<0} = f_\iota\),同时每次迭代自回归地预测下一个token的分布 \(p(t^{i} \mid t^{<i},f_r )\)。每次预测的token会被附加到前一个token后面,形成下一次迭代的输入$t^{<i+1} = t^{<i} \circ t^{i} $,重复该过程直到所有token预测完毕。可以计算得到整个序列的概率为 \(\prod^{l_T - 1}_{i=0} p(t^{i} \mid t^{<i},f_r )\)。
其中\(f_r\)有两种输入方式,最直接的是与\(f_\iota\)一样作为初始tokens \(t^{<0} = f_\iota \circ f_r\),参与每一次的前向过程,依赖自注意力层提取并整合特征。但该方法只适合小分辨率的情形,由于自注意力具有二次计算复杂度,将\(f_r\)也视为token会导致序列过长。而且它要求\(f_r\)的长度固定,因此必须在计算效率和生成质量之间进行权衡。面对这一挑战,将\(f_r\)通过交叉注意力注入解码器\(D\)的每一块,让tokens作为查询去匹配相应风格特征。
\(t^{<l_T}\)表示生成的所有token,从中去掉\(t^{<0}\),可以得到生成字形的token\(\hat{t}_y\)。目标函数就是最大化token序列的对数似然:
最终模型按照下列公式进行训练:
其中\(\lambda_{cl}\)是控制对比损失权重的超参数,本文实验中我们设置\(\lambda_{cl} = 0.5\)。
Experiment
Settings
采用了以下指标来评估所有模型的性能,也就是FID, L1, LPIPS, RMSE, SSIM。其中L1, RMSE, SSIM是像素级指标,它们代表了生成结果和真实值的像素距离,而FID和LPIPS这些感知级指标则更接近人类对图片的主观认知。由于字体审美是相对主观的感受,因此也对所有方法进行了用户调查,以用户满意度来评价模型表现。
作者发现之前的字体生成方法由于数据处理和指标选取的不同,各自论文中的性能无法互相比较。具体来说,字形的分辨率、字形四周是否有padding、图片数据范围以及评估方法的实现等因素都会影响指标的数值。例如NTF和CF-Font会设置字形比画布小,然后将字形放在画布正中间,四周留白,这会导致计算指标时虚高。为了公平比较,对于IF-Font以及所有参与比较的方法,全都使用一样的测试数据和指标实现。即字形四周不填充padding,画布长宽都是128像素,计算指标时将数据范围缩放到\([0, 1]\),LPIPS的网络类型选择squeezenet,FID计算使用inceptionv3中维度2048的特征层。
IF-Font使用了预训练的的VQGAN,其码本大小为\(256\)。字形图片分辨率\(128\times 128\),编码器将图片八倍下采样。字形对应的标记序列长度\(l_T=256\),而IDS序列长度\(l_I=35\)。解码器一共有\(10\)个Transformer块,每块包含一个自注意力层、一个交叉注意力层和一个简单的MLP。其中注意力层的头数都设置为\(8\),特征维度\(384\),同时应用概率\(0.1\)的dropout。模型训练使用AdamW优化器,解码器权重使用系数\(\beta_1=0.9, \beta_2=0.95\),其余权重则使用默认的\(\beta_1=0.9, \beta_2=0.999\)。学习率设置为\(5.76e-4\),使用warmup和余弦退火调度,批大小设置为\(80\),实验在单张Tesla V100上进行,一共训练\(15\)个epoch。
Dataset
由于字体生成领域没有公认的公开数据集,因此本章从网上搜集了464种字体,涵盖了打印体、手写体、书法和艺术字体等多样的类别。然后选取3500个常用汉字,再用搜集的字体将其渲染成128x128分辨率的图片。训练集由随机划分的3300个汉字和其中424种字体组成,称之为见过的字体和见过的字符(SFSC);测试集有两个,一个是由相同的3300个汉字和剩余的40种字体组成,称为见过的字体和没见过的字符(UFSC),另一个是其余200个汉字和剩余的40种字体组成,称之为没见过的字体和没见过的字符(UFUC)。
IDS来自于网上的一份公开IDS分解表,但一方面它包含了许多多余甚至循环引用的拆分规则,另一方面仍有部分汉字未被包含其中。因此对其进行了一些简化和补充,将IDC数量限制为图\ref{fig:12-IDC-example}中展示的12个,覆盖大多数常用汉字。方便起见,本文默认基础组件的IDS为它自身。
Comparison with state-of-the-art Methods
将提出的IF-Font与七个汉字字体生成SOTA方法在UFSC和UFUC数据集上进行比较,包括CG-GAN, LF-Font, FS-Font, CF-Font, VQ-Font, NTF, and FontDiffuser。为了公平起见,所有方法都按照各自的默认配置和官方代码在SFSC数据集上从头训练。同时比较都基于相同数量的参考字形输入,并且用相同的指标实现。其中作者修改了CG-GAN, LF-Font, FS-Font, VQ-Font 和 FontDiffuser的代码,使其支持其他数量的参考字形输入。
Quantitative Comparison
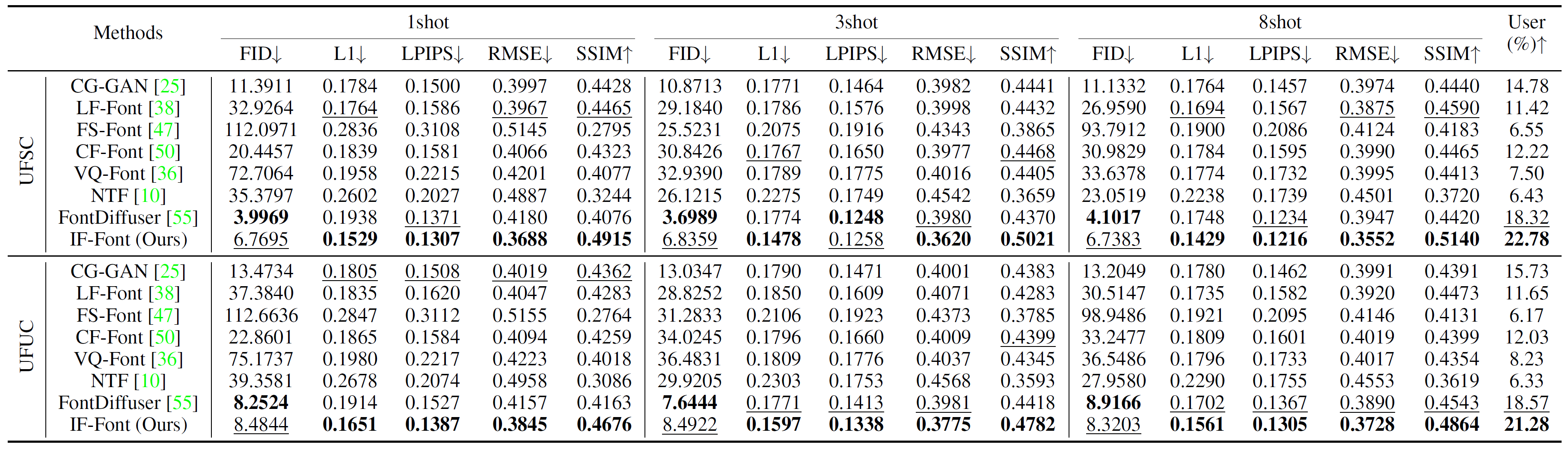
表2 UFSC和UFUC上定量比较的实验结果。"User"表示用户调查,展示的样本都基于三样本设置。粗体表示最好的结果,下划线标的是第二好的。
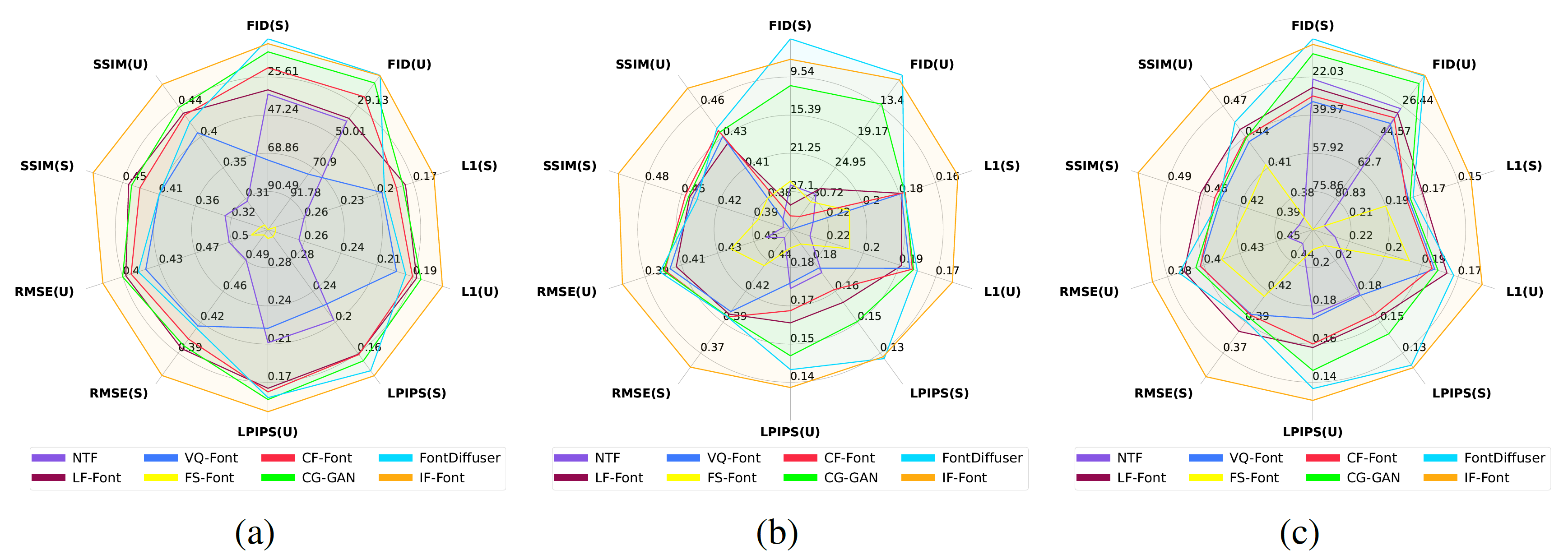
图10 雷达图。比起其他基于内容风格解耦范式的方法,IF-Font在三种少样本设置下的所有指标上都取得了SOTA性能。图中指标名字后面的括号表示评估用的数据集,(S)代表UFSC,(U)代表UFUC。(a) 单样本设置。 (b) 三样本设置。 (c) 八样本设置。
表1展示了IF-Font和其他SOTA方法的比较,IF-Font在两个数据集的所有参考字形数量设置上均大幅超越了竞争者,尤其是FID指标仅有个位数,这是由于IF-Font生成的样本十分清晰干净。由于UFUC数据集的字符和字体都是模型在训练时没见过的,因此生成更不容易,相比在UFSC数据集上,所有模型的指标均有所下降。其中IF-Font以字符的IDS作为输入,相比图片模态它更难以泛化。所以IF-Font在UFUC数据集的性能下降较多。
FS-Font非常依赖预先准备的内容-参考映射,而本文所有实验中的参考字形都是随机选择的。尤其是只给定一张参考字形时,很难完全覆盖目标字符的部件,因此它在图8a中的表现尤其糟糕。而NTF同样表现不佳,它生成的样本布局总是更接近源字体的,当目标风格变化较大时它容易出现笔画缺失的情况。意外的是CF-Font并非稳居第三的位置,这是因为它融合训练集中的10个基本字体来进行生成,但恰好本文数据集足够多样,验证集字体分布与训练集差距较大。
通过伏羲有灵众包平台开展了一项user study以量化主观质量。从两个测试数据集中分别随机挑选5个字符,然后让模型根据40种未知字体风格进行生成。一共30位参与者,每人需要从展示的各个模型生成结果中选出最接近groundtruth的一项。用户研究的结果如表2最后一列所示。
Qualitative Comparison
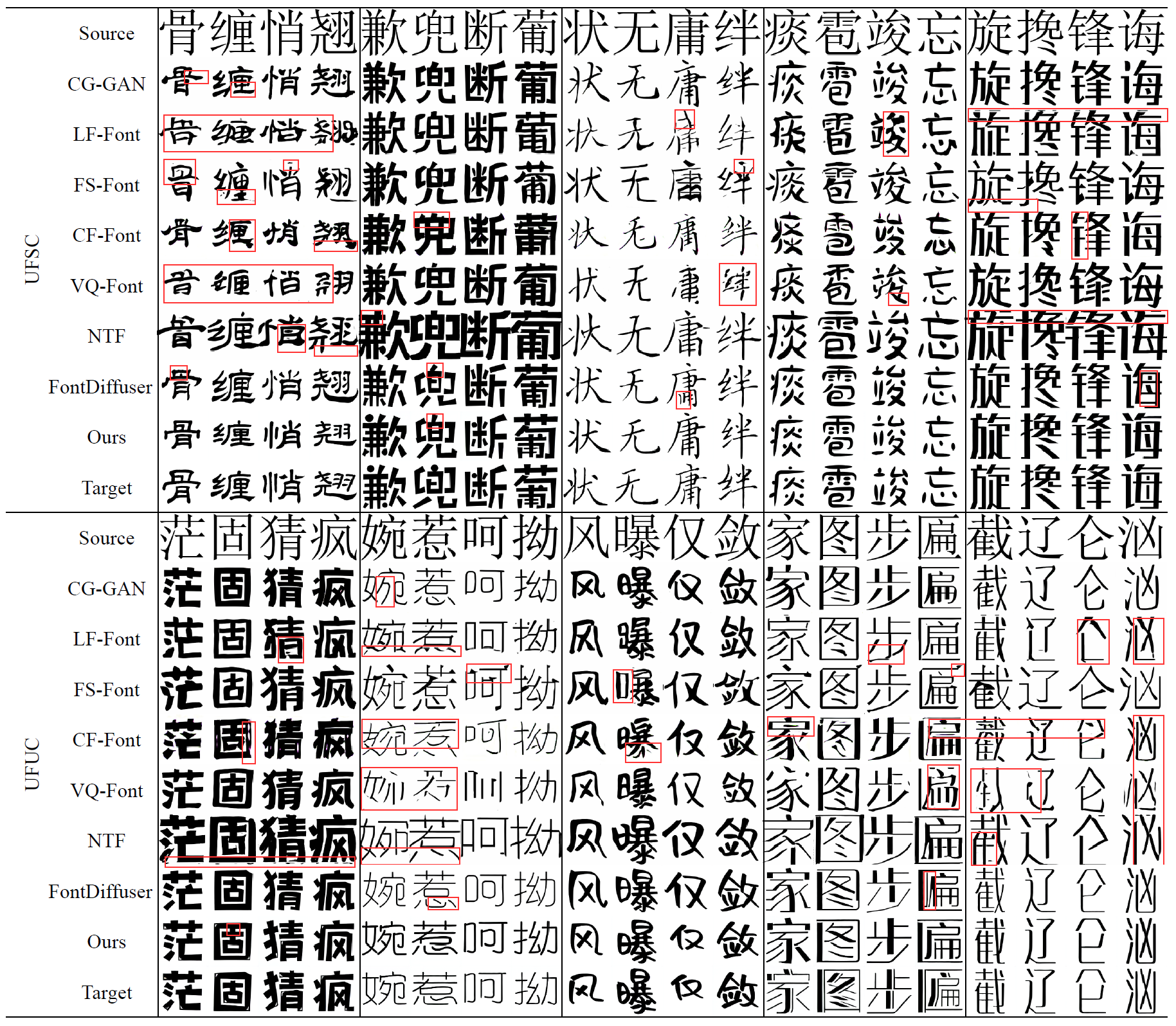
图5 UFSC和UFUC上定性比较的实验结果,其中红框框出的是有问题的部分。"Source"表示其他方法的内容输入,IF-Font仅使用对应的IDS。
在图5展示了表2的相应样本。IF-Font能生成最清晰且最风格一致的样本,而FS-Font, LF-Font, CF-Font等模型出现了笔画错误、模糊不清的问题。VQ-Font和NTF被源字体过度束缚,不擅长比较扁或比较窄的字形,容易出现结构错误。VQ-Font甚至会粗暴地裁减掉字形的上下或左右部分以适应目标风格。而CF-Font基本能够保持正确的字形布局,但生成结果中有不少伪影的存在,与目标风格间仍有一定差距。FontDiffuser的效果也十分出众,但对字体风格的模仿仍稍有欠缺。IF-Font能够保持汉字的结构正确,同时在字形长宽比例、空间位置和笔画细节等方面也更加出色。
Ablation Studies
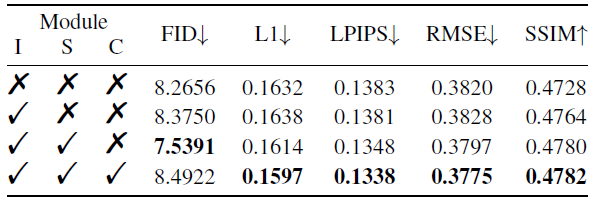
表3 不同模块的消融研究,第一行是baseline结果,I S C分别代表IHA, SSA, SCE模块。
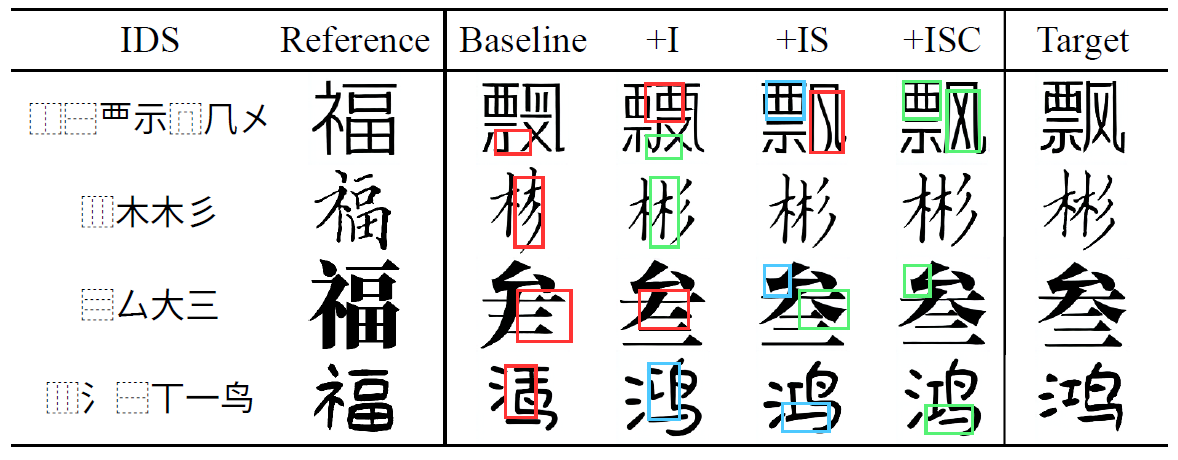
图6 主要模块消融实验的可视化,ISC和表2中的记号相同。红框表示缺失的部件,蓝框表示风格的不一致,绿色代表相应的改进。
Main Modules
去掉IF-Font的IHA, SSA, SCE模块,可以得到一个基线模型,对于输入的汉字它直接查表得出对应IDS,然后通过简单的嵌入层得到语义特征\(f_\iota\)。参考字形经过编码器后直接取平均作为风格特征\(f_r\),不与相似性和语义特征进行交互。同时也不对风格特征进行对比学习,整个模型仅使用交叉熵损失来监督。
在基线的基础上,逐步将三个模块添加回去,以直观地展示各模块对生成的贡献,表2和图6分别展示了该实验的定量和可视化结果。关于SSA的额外消融结果请参考附录。随着模块的加入大部分指标均有稳定上升,可以看到在图6中,基线缺失组件的问题能被IHA缓解,SSA改善了风格的一致性,SCE进一步提高了模型的风格模仿能力。
IDS Granularity
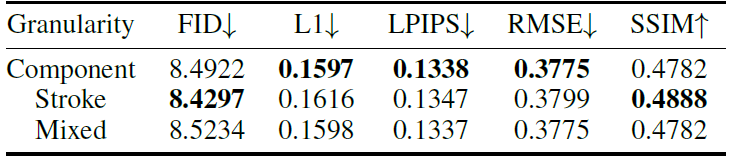
表4 IDS粒度对性能的影响
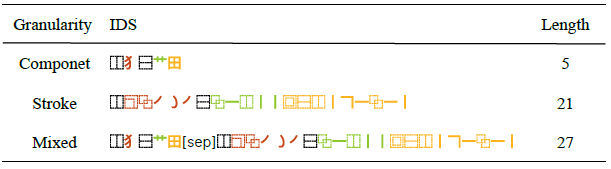
表5 不同的IDS粒度,Mixed表示部件和笔画粒度一起使用
在之前的实验中,IDS最小粒度都是组件,这意味着IDS词汇表较大且平均长度较短。实际上组件仍能进一步拆分为笔画序列,如表5所示。作者进一步分析了组件、笔画和混合这三种不同IDS粒度对模型性能的影响。表4展示了实验的定量结果。
笔画粒度在3个指标上性能下降,认为是细粒度导致一些汉字对应的IDS存在冲突,导致模型无法明确要生成的目标汉字。将两种粒度的IDS前后拼接在一起取得了与组件粒度类似的性能,但输入序列要长得多,导致更大的开销,因此在其余实验中使用组件粒度的IDS。
Visualization of SSA

图7 IDS和参考字形间的注意力图可视化,上方的符号是目标字符和对应的IDS。
为了展示结构风格汇聚模块的有效性,在图7中可视化了IDS中每个IDC和部件对应参考字形的注意力图。取SSA中计算局部特征时的矩阵\(A \in \mathbb{R}^{l \times k\cdot h\cdot w}\)。对于目标字符IDS\(\iota_y\)的每个位置\(i\),都有一个相应的注意力图\(A^i \in \mathbb{R}^{k\cdot h\cdot w}\),表示\(\iota^i_y\)对\(k\)个参考字形特征的关注程度。直接绘制\(A^i\)来展示注意力权重的分布,其设置透明度并叠加在原始的参考字形上。
可以看到,当目标IDC或组件存在于参考字符中时,相应的部分会得到更多的关注。例如,在第一行的第一、二和四列以及第二行的第三和五列都有明显的突出显示。相反,如果参考字符缺少目标组件,则局部分支倾向于不投入注意力,这体现在几乎空白的第三行上。这种方法源于避免强制分配注意力可能带来的干扰的偏好。相反,利用全局分支捕捉到的平均风格有助于保持输出的基本质量。
New Glyph Creation
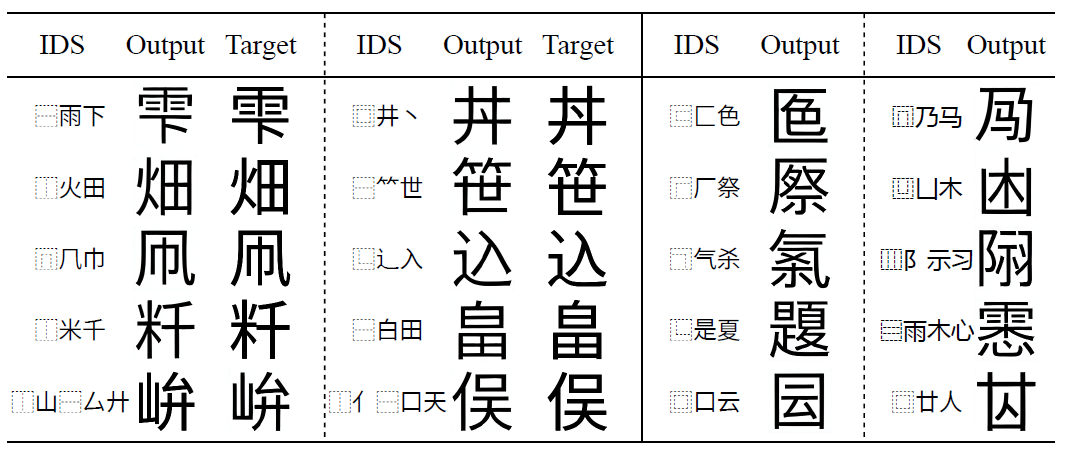
图8 模型创造字形的能力。前两列是中文语境中不通用的汉字(包括[和制汉字](https://www.sljfaq.org/afaq/kokuji-list.html)),最后两列是完全不存在的汉字。
为了验证IF-Font的灵活性,使用非通用汉字的IDS进行生成。图8是实验结果。实验中固定字体为“更纱黑体”,它是中日韩越统一字体,而最后两列由于是完全不存在的字形,没有相应真值。能看到IF-Font遵循给定的IDS,可以生成结构正确风格统一的新字形,展现出强大的泛化能力。
Discussion
Failure cases

图9 UFUC复杂字体上的失败样本。GT表示字体直接渲染的字形,Target是经过VQGAN重建的字形,为模型提供监督信号,Output是模型生成的样本。图中橙框框出了VQGAN的重建错误,红框表示结构错误。

图11 图9完整版,与其他模型的对比
虽然方法能够在大部分情况下生成高质量的字形,但它在一些困难样本上仍然比较吃力,如图10所示。IF-Font无法处理过于花哨和无规则的字体,例如图中带有装饰的、过分窄的、笔画过分弯曲的、书法字体,但仍然能维持正确的汉字结构。
由于target本身就来自VQ-GAN的量化序列重建,它的还原度决定了IF-Font能力上限。图9中可以看到target与gt有细微差别。不过由于字形是灰度图片且相对简单,微调VQ-GAN或换用更有效的模型有望最小化精度损失。为了突出主要贡献,因此直接采用原始的 VQ-GAN 预训练权重。
事实上,IDS作为汉字的描述序列仍有一定局限性。表现为部分IDS冲突、IDC的空间描述不够清晰。这导致IF-Font不擅长处理没有在训练中见过的部件,如图9所示。一方面,一些汉字在分解为笔画粒度的IDS(内部描述符)时,由于字形过于相似而完全相同。另一方面,IDC的描述不够清晰。例如左右结构表示两个部件分别位于左边和右边,但它们之间的具体距离并未明确指定,这需要模型通过充分的学习来区分。
Usability
本文将重心放在CJK字符上,是因为它们具有空间结构,更能体现方法的特点。通过扩大词汇表、纳入数据进行训练,IF-Font也适合于其他语言文字。
Advantages
- 符合书写习惯。以IDS为输入进行自回归建模的过程中隐含了书写的顺序。
- 扩展性。可以借助LLM的成熟经验,具有良好的可扩展性。
- 鲁棒性。由于采用了向量量化技术,字形由有限种类的token(仅256种)表示,降低了解码器的学习难度,并减少了生成结果中出现伪影等问题的可能性。
Conclusion
展示了IF-Font,一个新的字体生成范式。IF-Font将字形量化为token序列,并引入表意文字描述序列(IDS)来控制生成字形的内容,将字体生成重新定义为序列预测任务。这一做法使它善于在处理复杂风格的同时维持正确的汉字结构。提出了IDS层次分析模块和结构风格汇聚模块,进一步设计了一个基于Transformer的解码器,以自回归的形式实现了高质量的字体生成。由于向量量化,字形仅由种类有限的token(仅256种)表示,降低了解码器的建模难度,使得生成结果不容易出现伪影等问题。实验表明IF-Font超越了已有的SOTA方法,其中每个模块都有贡献。得益于IDS的形式,方法具有高度灵活性。只需制定合法的IDS就能创造字形,而其他方法则要求该字形被至少一种字体收录,以便用作内容输入。
后续研究可以改进并完善IDS的分解规则。此外,将IDS用于手写汉字生成,以及将序列生成推广到其他语言文字的生成可能会产生有趣的见解。微调VQGAN使之更贴合字形数据也能进一步提升方法的精度,根据字形结构调整token的预测顺序或许也不错。
Critique
"Ideographic Description Sequence-Following" 很有大模型那边 "Instruction-Following" 的味道
几个模块的命名整合有点太刻意,不如将新的范式作为一个创新点。作者明显不擅长写作,不会包装。文字先不提,图片倒是挺好看。模型效果非常惊艳,实验非常齐全,甚至做了1,3,8shot三种设置,图表都放不下了。不像其他方法不敢比新模型,而且总喜欢拿一些老东西来凑数。本文起步就是LF-Font,每一个顶会顶刊有开源的都没放过,这点非常好评。
优点很明显不过缺点也很明显,讨论部分已经说得很清楚。其中最大的问题是只聚焦于CJK这种结构式、能被拆分为一个个组件的文字。实际上根据代码,其他文字也不是不支持,只是利用不到IDS的这种描述特性。就像某些独体字,直接整个字符作为自身的IDS,加进词汇表中然后该嵌入嵌入该生成生成即可。不与其他字符有共享组件意味着更大的训练成本,要用足够多的数据才能让模型记住。真要说的话比LF-Font、FS-Font那种灵活多了。尤其是代码非常清晰易懂易用,非常好评。
出于好奇扒了一下作者,发现一作只有这篇,二作三作发表的文章又杂又乱。这还不是连宙辉那种专门做这个领域的985实验室,已经脑补出了可怜学生独自写作投稿的胃疼剧情了。至少没抢一作不是吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号