[论文阅读] Painterly Image Harmonization using Diffusion Model
Pre
title: Painterly Image Harmonization using Diffusion Model
accepted: AAAI2023
paper: https://arxiv.org/abs/2212.08846
code: https://github.com/bcmi/PHDiffusion-Painterly-Image-Harmonization
ref: https://mp.weixin.qq.com/s/0AzaD8qVOFJrFeeIaJ4sTg
ref: https://zhuanlan.zhihu.com/p/603227426 (PHDNet)
关键词: painterly image harmonization, diffusion model, style transfer
阅读理由: 很有趣,而且想学习一下里面的风格对比损失
Idea
在ddpm.LatentDiffusion的基础上屏蔽文本条件输入c,将拼接图片comp作为z扔进去,然后comp和前景mask拼接过编码器作为条件来引导扩散模型,得到和谐化的图片pred_x0。也就是把扩散模型套到了painterly image harmonization任务上。
Motivation&Solution
- 第一个将扩散模型引入风格图像和谐化任务
- 现有的基于优化的方法通过最小化所设计的损失函数来优化合成图像,非常耗时。而前馈方法主要依赖GAN,训练好的模型可以直接生成和谐的图像,然而它在复杂前景的控制上存在局限性,导致前景协调效果不理想,例如内容和风格细节的丢失。
Background
"painterly image harmonization" (风格图像和谐化) 指的是将照片中的物体(photographic objects)插入绘画中,并使二者风格艺术和谐统一。之前的方法大致可以分为:基于优化(inference optimization)和前馈方法(如GAN)两类,但它们都十分耗时,或难以精确把握前景物体(纹理或内容细节)。为此作者提出了Painterly Harmonization stable Diffusion model (PHDiffusion)

图1 风格图像和谐化希望让插入的前景物体与背景和谐一致。PHDNet为作者所在实验室的上一个工作。
standard image harmonization 专注于适应低阶统计数据(颜色、亮度),而 painterly image harmonization 更具有挑战性,需要转换高阶的风格
一些现存的工作已经用上了扩散模型到相似的任务中,如跨域图片合成和图片编辑任务。例如CDC提出了推理时方法(inference-time conditioning method),用背景的高频细节和前景物体的低频风格来做图片合成,但高频特征=风格,低频特征=内容这一结论未必总是成立。SDEidt则通过加噪去噪来迭代合成图片,但是降噪时缺少恰当和充足的引导,导致最终的图片缺少充足的风格和内容。
Method(Model)
Overview

图2 PHDiffusion架构 给定合成图片I_c和它的前景mask M,I_c送入预训练的SD模型(上方灰色),首先编码到潜空间z^'_0,再加噪声得到z^'_t,推理时再逐步降噪,最终经由解码器得到和谐化的图片\tilde{I}_0。同时I_c跟M拼接送入自适应编码器,再用双编码器融合(DEF)来为降噪过程提供引导。L_{LDM}损失约束降噪过程,还有俩风格损失负责前景风格化,用内容损失做内容维持。
PHDiffusion包含一个是轻量自适应编码器和一个是双编码器融合模块(DEF),它们首先将前景特征风格化,然后风格化特征用于引导和谐化过程。训练时除了扩散模型的噪声损失(noise loss),还引入了两个额外的风格损失:AdaIN风格损失和对比风格损失,以平衡风格迁移和内容维持两部分。
Adaptive Encoder
轻量自适应编码器是受条件扩散模型(T2I-Adapter)的启发,旨在从合成图像中提取所需的条件信息,即背景风格、图像内容。它以合成图像和前景掩码的串联作为输入,产生添加给去噪编码器特征图的残差。
之前多用文本来约束降噪过程,本文扔掉了文本CLIP编码器,改用图片和mask的拼接来提供信息。介绍模型架构,说\(F^i_c\)共有4个,模型中不同层的输出结果,分辨率不同
Dual Encoder Fusion Module
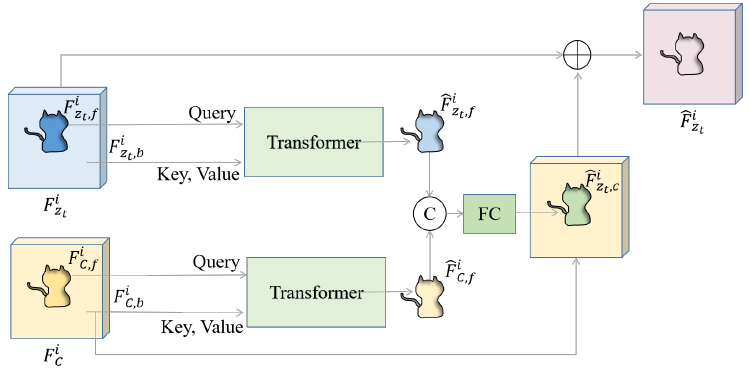
图3 Dual Encoder Fusion (DEF) 架构,左边蓝黄两个块又细分为前景、背景特征,前景的作query背景作key,value进行交叉注意力,然后拼接过全连接再跟黄色的背景特征以及蓝色一整块结合得到粉色。
基于自适应编码器和扩散模型中的去噪编码器,作者引入了一个双编码器融合(DEF)模块来融合两个编码器的信息。具体而言,给定两个编码器提取的图像特征,双编码器融合模块将背景风格融入前景内容中并生成风格化的前景特征。图中是将自适应编码器的\(F^i_c\)和相应的降噪特征图\(F^i_{z_t}\)编码为新的降噪特征图\(\hat{F}^i_{z_t}\)。然后,来自两个编码器的风格化前景特征被组合在一起,在去噪步骤中提供多步引导。
说是直接相加或拼接 \(F^i_c,\; F^i_{z_t}\) 的效果很差,考虑到CNN无法建模长距离依赖...策略是浅层的(i=1,2)特征直接相加来保留局部结构,深层的(3,4)使用DEF模块来捕捉全局风格。
Stylized Feature Extraction 以 \(F^i_c\) 为例,要提取前景背景特征就通过mask+flatten,如背景特征 \(F^i_{c,b} = Flatten(F^i_c \circ (1-M))\),然后就能送入Transformer...
Stylized Feature Fusion Transformer输出靠全连接结合,再直接加上蓝黄的一部分
Objective Function
为了利用预训练的稳定扩散模型(SD)中丰富的先验知识并减轻训练负担,作者冻结了SD的模型参数,并仅在训练过程中更新自适应编码器和双编码器融合模块。扩散模型中使用的标准噪声损失只能从潜空间重建图片特征,无法将背景风格迁移到前景上。因此进一步引入了两个额外的风格损失,即AdaIN损失和对比风格损失,以平衡前景对象的风格和内容。
Noise Loss. DDPM的降噪是要去掉\(z'_T\)的噪声,最终重建原始合成图片\(z'_0\),因此该目标函数是要预测第t步的噪声,其中y是条件信息(合成图片和前景mask)
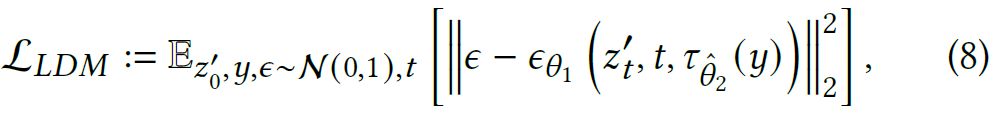
公式8
AdaIN Loss 公式8的noise loss只涉及潜空间,而风格损失无法直接在潜空间计算。给定解码器输出的图片\(\hat{I}_0 = \mathcal{D}(\hat{z}^t_0)\),这里标错了?图2中是\(\tilde{I}_0\)
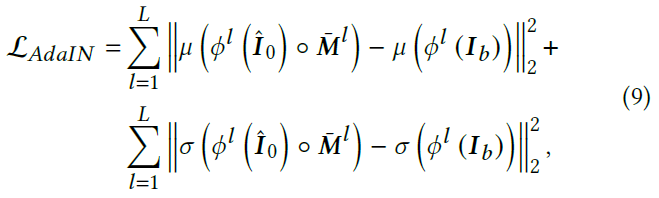
公式9
其中\(\phi^l\)表示预训练VGG-19里第l层ReLU,\(I_b\)是完整的背景图片,\(\bar{M}^l\)是下采样到相应尺寸的前景mask。AdaIN损失将前景对象的多尺度统计数据(例如均值、方差)与背景绘画进行对齐,看起来是约束生成图片中前景部分的均值方差与背景图片一致,确实有AdaIN的感觉,但这是不是等于加了个AdaIN层呢。
Contrastive Style Loss 对比风格损失旨在将前景风格推向背景风格。同样把\(\hat{I}_0\)输入VGG,从特征图中裁出前景的部分,再将其投影为anchor向量\(f_q\),同样地从\(I_b\)的输出特征里抽取正样本\(f^+_b\),从其他风格图片里抽取负样本\(f^-_b\)。

图4 对比风格损失中 anchor, 正样本, 负样本 三元组的构建
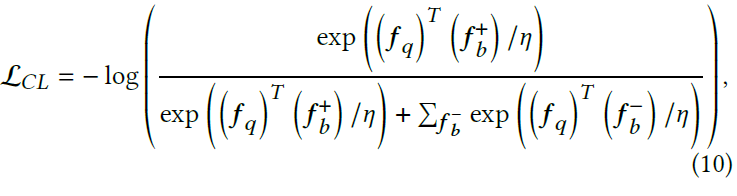
公式10
其中温度\(\eta\)调节推拉力度,将其设置为0.2
Content Loss. 在平衡noise loss和风格损失时,内容细节可能被过度保留,导致风格迁移不充足,因此减少了noise loss的权重并引入内容损失。这玩意也是风格迁移常用的,维持高层级内容信息且不会牺牲风格:
其中\(\phi^4\)的定义和公式9一样
Total Loss. 通过噪声损失、风格损失和内容损失,PHDiffusion能够理解背景风格并保持前景内容。在测试中PHDiffusion可以直接用于生成协调的图像,避免了额外的耗时推理优化,总损失如下:
\(\lambda_1,\; \lambda_2\)分别设置为60, 5
Experiment
Settings
训练自适应编码器和融合模块,batchsize=2,epoch=10,Adam,lr=2e-4,训练时将图片和mask都缩放到512x512,使用sd-v1-4的预训练SD模型。
基准数据集COCO、WikiArt
风格图像和谐化任务没有靠谱的量化指标,主要依靠user study
Results

图5 与其他模型的对比,CDC、SDEdit属于crossdomain composition,DIB、DPH、PHDNet是其他的和谐化方法

图6 对比一些artistic style transfer方法
Visualization Analysis. 本文方法赋予了前景物体跟背景一致的风格,如图5第一行,它不仅学到了局部点状纹理,也学到了全局的条带排列,并且在内容风格上平衡得很好。图6能看到InST会丢失内容,而且风格跟背景不兼容,其他风格迁移方法无法生成足够的风格,本文既能生成高度匹配背景的纹理还能让总体颜色分布与背景强相关。作者将表现归因为:DEF和各损失项的使用。

表1 user study 结果,分越高越好
User Study. 从COCO选100张内容图片,WikiArt选100张风格来生成100个合成图片,用包含本文模型在内的11个模型去和谐化,邀请50个用户...看表1
Ablation Studies
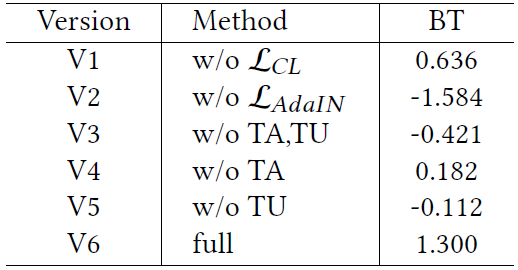
表2 消融结果 "TA""TU"表别代表 adaptive编码器 和 U-Net编码器 各自的Transformer层。 "BT"仍代表B-T分数

表7 消融样本
V1V2验证风格损失有效性,V3~5验证 adaptive encoder, U-Net encoder 中Transformer层的有效性,V6是完整模型。比较表2,AdaIN对风格迁移更加重要,而对比风格损失有助于捕捉更加合理的风格,而Transformer层对两个编码器都很重要。观察图7,AdaIN能学到近似混合的风格(styles that appear to be blended),对比风格损失倾向于学习精细的纹理(杯子的朦胧感和熊皮毛的纹理)同时维持原本的颜色。而Transformer有助于更一致更加合理的风格,而自适应编码器更倾向柔和的色彩(V5),U-Net编码器则喜欢夸张的颜色(V4)。
Conclusion
提出了一个新的风格图像和谐化模型:PHDiffusion,实验表明超越了SOTA。
附录提到一些类型的前景物体如人脸,仍难以与背景和谐化,因为人脸细节精致,而人类对人脸的微小变动很敏感,不容易在保持细节的情况下做到充分的风格化。
Critique
消融实验的V3~5是否有些多余,Transformer的有效性应该是公认的,而且去掉它们要用啥替代?还是说这相当于是去掉对应的整个编码器?而且DEF、内容损失不消融一下吗
看了眼代码那个对比损失怎么只支持batchsize=1??这个style应该是背景图片,但由于要拼接为合成图片comp,二者必然一一对应。就算说后面会改进,但bs=1就能训对比损失?但论文说bs=2,那意思是不用对比学习??
而且对比学习用的图片数量compare_num(number of compare style for contrastive learning)由argparse参数指定:默认为3,根据根目录的README,似乎也没有指定新的,那就是3??
ddpm.LatentDiffusion原本接受的文本条件c,好像直接用空字符串替代...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号