[论文速览] SDXL@ Improving Latent Diffusion Models for High-Resolution Image Synthesis
Pre
title: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
accepted: arXiv 2023
paper: https://arxiv.org/abs/2307.01952
code: https://github.com/Stability-AI/generative-models
关键词: image synthesis, stable diffusion, SDXL, AICG
阅读理由: 看看它条件融合怎么做的,交叉注意力还是什么
Idea
在原本 Stable Diffusion 模型的基础上升级架构,并用上更多的训练数据和更好的训练策略,输出再用 refiner 进一步提升图片质量

Motivation&Solution
- 以往的SD训练都无法有效地利用小尺寸图片
- 训练时用的 random cropping 会影响生成结果
- 真实图片的尺寸和比例丰富多样,而模型的输出则大多都是512或1024的方图
Method(Model)
Architecture & Scale
SDXL 用的 UNet 是之前的三倍大,模型参数的增长主要是由于更多的注意力block和更大的交叉注意力
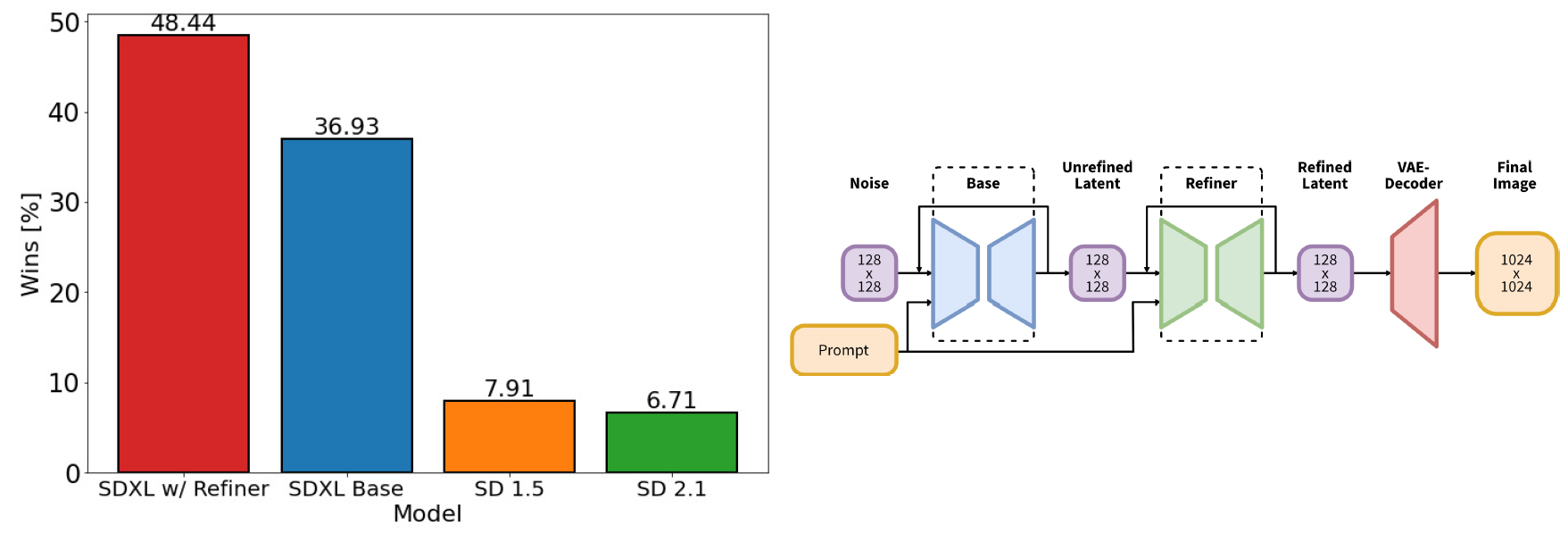
图1 左边是SDXL的用户满意度超过了 SD1.5, SD2.1(2.1还不如1.5啊,难怪c站一大堆模型都是1.5的) 右边是SDXL的两阶段pipeline,在基础模型之后多了一个refiner。先用SDXL生成128x128的隐变量,然后用相同的prompt过专门的高分辨率refinement模型,再用上SDEidt。SDXL和refinement模型用相同的自编码器。

表1 SDXL和较早的stable diffusion模型比较
有提到除了用交叉注意力层去建模文本输入的条件,还额外考虑 OpenCLIP 模型的池化文本嵌入(pooled text embedding)作为条件。
Micro-Conditioning
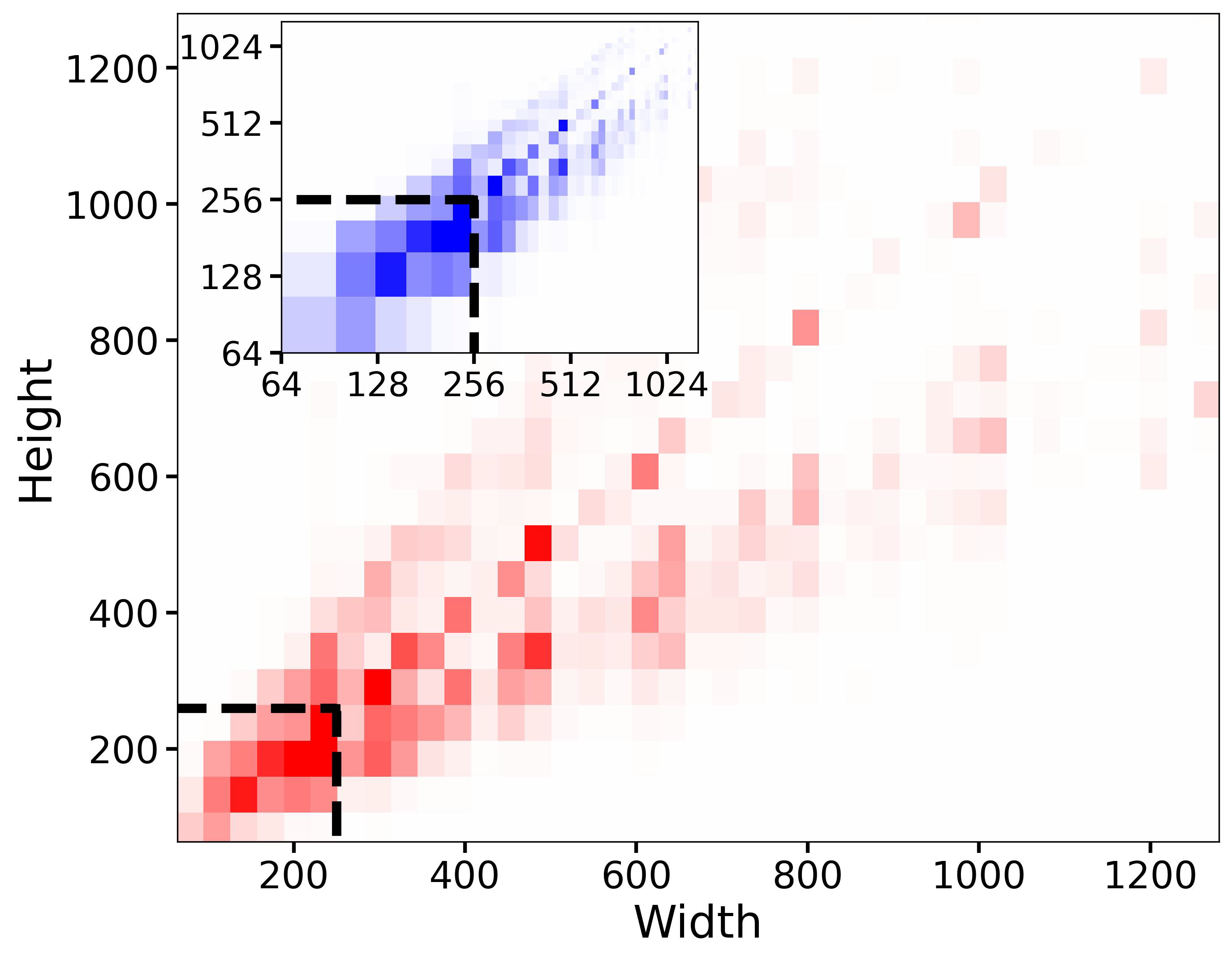
图2 预训练数据集的高宽分布,不使用提出的 size-conditioning,39%的数据都会因为边长小于256像素而被丢弃,就是黑色虚线画的那些。颜色密度正比于样本数量。
LDM 范式的一个问题是模型的训练要求图片尺寸不能太小,这是它两阶段架构决定的。有两种办法,一是扔掉过小的图片,二是对小图片进行放大。前者会导致很多训练数据被抛弃,影响性能跟生成效果,见图2的可视化。而后者则会带来放大伪影(upscaling artifacts),并泄漏到模型输出中,导致模糊的样本。
作者说要用图片原始的宽高作为模型的条件, \(c_{size} = (h_{original}, w_{original})\) 每个部分都用傅里叶特征编码(Fourier feature encoding)单独嵌入,然后拼接为一个向量,加入 timestep 编码后再喂入模型。
推理时用户通过 size-conditioning 来设置所需的直观分辨率(apparent resolution),如图3所示,给不同分辨率条件它就生成给定分辨率的图片。

图3 更改 size-conditioning 的影响:用相同随机种子画4个样本,随分辨率增大图片质量明显提高。样本都来自 $512^2$ 模型,说是在 1024x1024 微调之前 size-conditioning 的影响更明显。
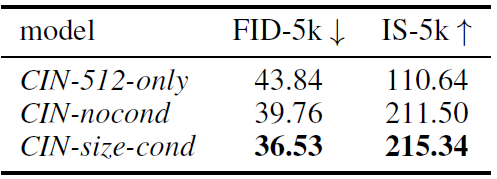
表2 以原始空间尺寸为条件提高了 class-conditional ImageNet 在512x512分辨率的性能
表2里第一行是只用512大小的图训练模型,第二行是图片都用上但没有加 size-conditioning ,第三行是加上了 size-conditioning 。作者说第一行不行是它丢了太多图片,数据集小,过拟合了。第二行用的小图片太模糊。

图4 SDXL跟之前版本的比较。每个模型都用DDIM采样器推理50步,cfg-scale=8.0

算法1 描述了 size- 和 crop-conditioning 的结合

图5 更改 crop-conditioning 的影响。
跟前面的 size-conditioning 一样,作者又搞了个 \(c_{crop}\) ,用 \(c_{top},\; c_{left}\) 分别记录 random cropping 随机裁切掉的上方和左边的像素,又是那个傅里叶编码,然后跟 size-conditioning 结合用。推理时设置 \((c_{top},c_{left}) = (0,0)\) 就能得到物体在中心的图片。
Multi-Aspect Training
真实图片的尺寸和比例都不尽相同,而文本到图片模型的输出则大多都是512或1024的方图,因此作者微调了模型以适应不同比例。按不同比例将数据分桶,尽量保持像素总计(pixel count)接近 \(1024^2\) ,相应地调整高宽到64的倍数,附录有训练用的完整比例列表。
优化时batch内的图片都来自同一个桶,然后不同训练step交替用不同的桶,而且像上面那两种conditioning一样,搞了个桶的条件,即 \(c_{ar} = (h_{tgt},w_{tgt})\)
实践中是把该技术用于预训练后的微调
Improved Autoencoder
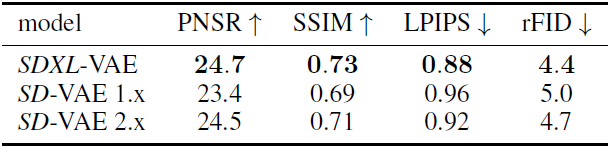
表3 自编码器重建性能的比较,图片大小256x256,SDXL-VAE是从0训练的
Stable Diffusion 是一个 LDM,工作于预训练自编码器的隐空间。虽然大部分语义组合是由LDM完成的,但改进自编码器能提升生成图片里的局部和高频细节。为此作者重新训练了相同架构的自编码器,但用了更大的batch-size,又用上了指数移动平均来更新参数。
Putting Everything Together
最终的SDXL是多阶段来训练的,先 600,000 步训练 base model ,batchsize 2048,然后再用更大分辨率的图片训 200,000 步,最终用上 multi-aspect 训练。

图6 1024x1024样本,左边是SDXL的,右边过了refiner。prompt "Epic long distance cityscape photo of New York City flooded by the ocean and overgrown buildings and jungle ruins in rainforest, at sunset, cinematic shot, highly detailed, 8k, golden light"
Refinement Stage 模型有时会给出低质量的样本,如图6,为此在相同潜空间 训练了另一个LDM,专注于生成高质量高分辨率的图,并对基础模型(base model)生成的样本应用SDEdit的降噪过程。这步不一定要,但能提升结果的质量。
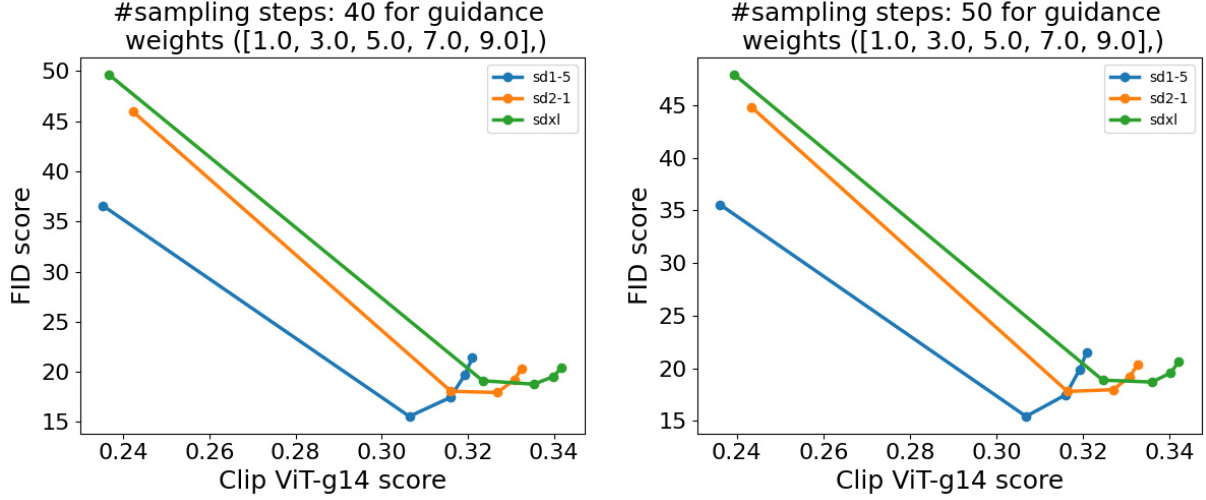
图12 画出不同 cfg scales 时的 FID vs CLIP分数 SDXL 似乎只在文本对齐上略微提升,看CLIP分数。而FID分数不如其他两个,这跟人类的评估是相反的
性能评估依靠用户调查,SDXL有 48.44% 的满意度,然而在经典性能指标如 FID、CLIP 上却不如之前的模型
Future Work
SDXL在图片质量、prompt遵循(prompt adherence)和编排(composition)上都有大进步,但下面还有一些点可以改进:
- 单阶段。SDXL是两阶段,需要refiner
- 文本合成。虽然更大的文本编码器(OpenCLIP ViT-bigG)有助于改进文本渲染能力,引入字节级别的(byte-level)tokenizer 或 单纯把模型做大都可能进一步提升文本合成能力。
- 架构。在本工作的探索阶段,短暂试过Transformer架构,如UViT和DiT但没有直接好处,但仍保持乐观,认为调调参能用上更大规模的Transformer架构
- 蒸馏。对原模型的改进很大,但推理时的开销也很大,将来可以加上各种蒸馏(guidancedistillation, knowledge-distillation and progressive distillation)
- 将来可以考虑 EDM-框架,因为它在连续时间的形式允许更加灵活的采样并且不需要 noise-schedule corrections
EDM-framework

图7 SDXL失败样例。复杂的prompt不行:细致的空间安排和细节描述(例如左上)。同时手并不总是正确生成(如左上),模型有时会把两个概念互相混淆(右下)。所有样本都是 DDIM 采样器和 cfg-scale=8.0 随机采样来的。
首先,合成复杂结构(人手)还是不大行,原因可能是手和类似的物体在照片里的差异很大,很难去抽取真实3D形状和物理限制(physical limitations)的知识。
第二,真实感(photorealism)还不够,某些细微差异,如隐约的灯光效果或些微的纹理差异仍有所缺失或不足。
再者,模型训练依赖大规模数据集,会不经意地带来社会和伦理偏见...
还有图7里概念混淆(concept bleeding)的问题,意外的合并或不同视觉元素的重叠...根本原因可能是预训练文本编码器的使用:第一,他们训练来将信息压缩为单一token,因此它们可能无法只绑定正确的属性和对象。第二,对比损失在一个batch里需要负样本有不同绑定(binding),也可能导致这个问题。
此外,图片还行,但里面有字的话效果就不好,无法渲染长的、清晰易读的文本。
Critique
淡化了模型的结构介绍,附录内容好多,Acknowledgements、Limitations都扔到了附录里,跟平常看的论文不大一样,没想到加的方法都挺简单的,直接把会变化的信息都作为条件输入模型...
而且有意思的是在讲limitation时接一些可能的办法,好多 further scaling,果然越大越好?
而且本来是要看看怎么融合条件的,不过论文里没有详细的模型结构,只说用了 classfier-free guidance

 浙公网安备 33010602011771号
浙公网安备 33010602011771号