[论文速览] DropKey
Pre
title: DropKey
accepted: CVPR 2023
paper: https://arxiv.org/abs/2208.02646
code: in paper
关键词: Transformer, dropout,
阅读理由: 方法简单通用,效果又好像很好,(组会)
Idea
在注意力计算阶段随机 drop 部分 key 以鼓励网络捕获目标对象的全局信息,从而避免了由过于聚焦局部信息所引发的模型偏置问题
Motivation&Solution
- 基于 Transformer 的方法在训练数据量较小的时候容易过拟合
- 使用CNN常用的 Dropout 又会有一些问题:
- 在 softmax 归一化后进行随机 Drop 会打破注意力权重的概率分布并且无法对权重峰值进行惩罚,导致模型仍会过拟合于局部特定信息
- 网络深层中较大的 Drop 概率会导致高层语义信息缺失,而浅层中较小的 drop 概率会导致过拟合于底层细节特征,因此恒定的 drop 概率会导致训练过程的不稳定
以往在Transformer上应用dropout都是直接 drop softmax 后的注意力权重,现在改为 drop 用于计算的key,即dropout-before-softmax
Background
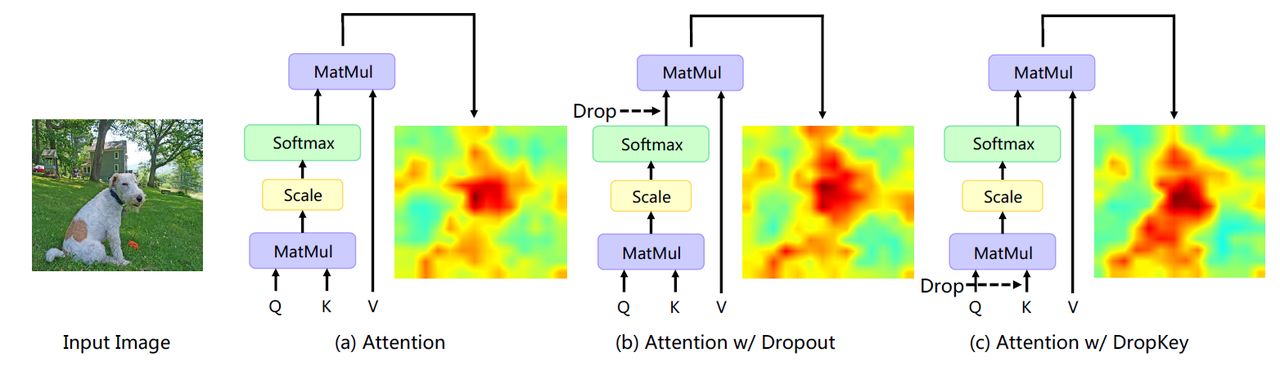
(a)有过拟合问题,(b)仍过拟合部分模式
Method(Model)
Overview
推导还蛮复杂的:

实际上具体实现并非mask掉key,而是mask query@key 的相似度矩阵:

几种不同的mask方式:
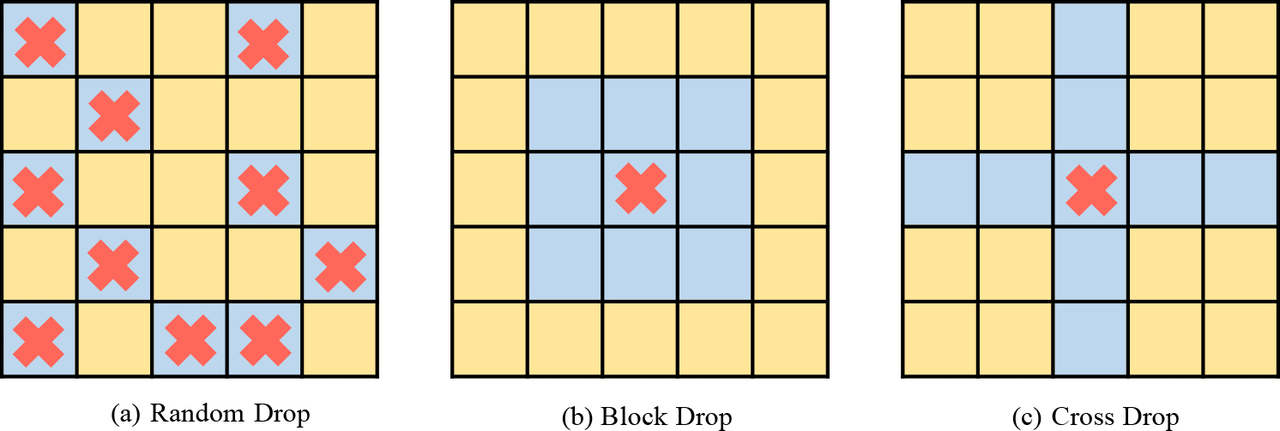

蓝色去掉,黄色保留,红色是 valid seed 这里是探究结构化drop的差异,结论是随机就挺好的
Experiment
Results

在CIFAR10和CIFAR100上对比DropOut跟DropKey,实线的是DropKey
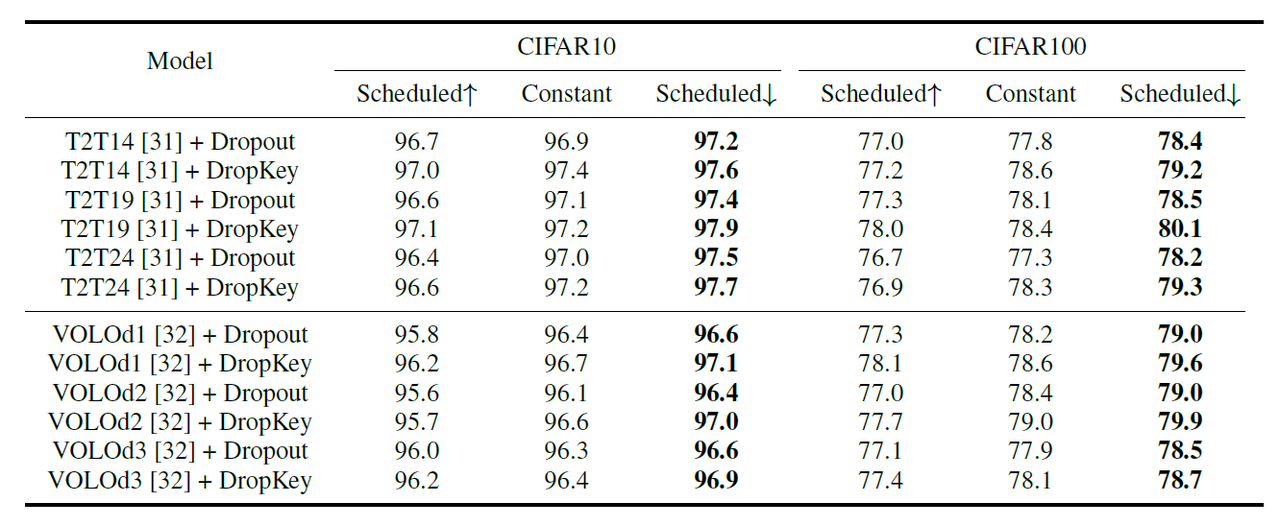
一般而言,ViT 会叠加多个注意力层以逐步学习高维特征。从上表的实验可以看出,随着层数的不断加深而逐渐降低 drop 的概率效果最好。此外,该研究还发现这种方法不仅适用于 DropKey,还可以显著提高 Dropout 的性能。
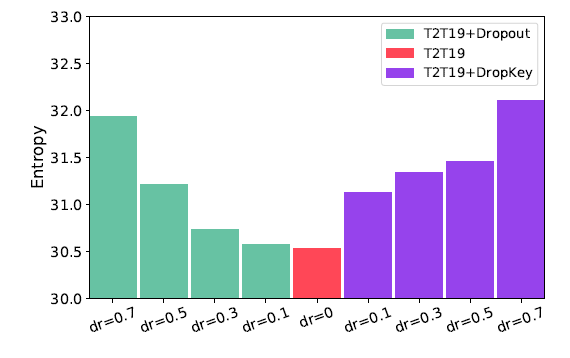
小的熵值表示模型更聚焦于sparse patches,由于class token对于聚合整张图的信息有帮助,这里计算它的熵作为模型提取全局信息能力的度量

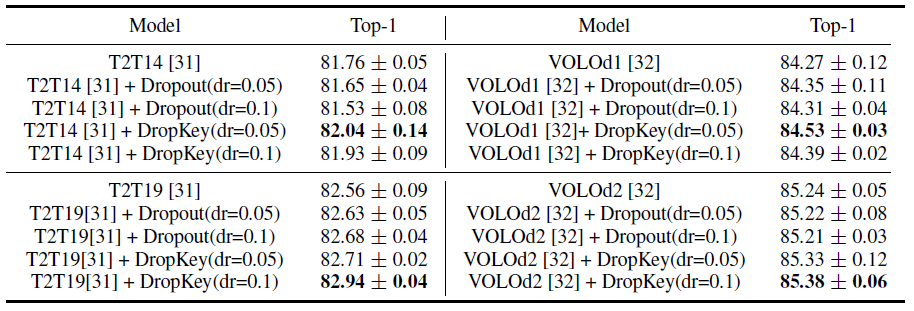
在ImageNet上面比较Dropout和DropKey,dr表示drop比例

DropKey在HUMBI(多视图人体模型数据集)上面的可视化,可以看出DropKey学到的表达更加鲁棒。Dropout只注意到肘部关节点附近的顶点,而DropKey会综合全局信息,考虑到手腕和手臂附近的顶点
Conclusion
Critique
感觉方法很简单效果好像也可以,不知道实际任务中有没有效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号