[论文速览] MAGE@MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
Pre
title: MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
accepted: CVPR2023
paper: https://arxiv.org/abs/2211.09117
code: https://github.com/LTH14/mage
ref: https://mp.weixin.qq.com/s/AfWWwrEpYAHI03tIzVxMiQ
关键词:Representation Learning, Image Synthesis, masking, quantized tokenization
阅读理由:对标MAE,结合了图片生成跟表征学习,效果很好
Idea
使用VQGAN得到离散的图片token,通过可变比例的mask统一处理图片生成跟表征学习两个任务,还可以加入对比学习进一步提高性能。
Motivation&Solution
- 生成跟表征学习是CV两个关键任务,但这些模型通常独立训练,忽视了互相协助的可能,增大了模型训练跟维护开销 —— 在掩码图片建模预训练中使用可变的掩码比例,这样通过高遮盖比例实现图片生成,在低遮盖比例下实现表征学习,将二者统一在一个框架中,称之为MAsked Generative Encoder (MAGE)
- 以往的的MIM输入都是像素,导致生成图片质量低下,多样性不足 —— MAGE输入输出都使用语义token
Background

图1 在ImageNet-1k上不同方法的线性探测跟类别无条件生成的对比
在自然语言处理中,像 BERT 这样的模型不仅能够生成高质量的文本,还能够提取文本中的特征,另一个例子是DALLE-2,他们都能同时结合两类任务。

图2 MAE 与 MAGE 重构对比,遮盖率75%,MAGE的结果更清晰且多样,注意MAGE是对token,而MAE是对patch进行遮掩
但通过调节遮盖率直接结合这俩类方法效果不好,图片会模糊,因为它们都用简单的像素重建损失。比如MAE他重建的质量就不行,细节跟纹理会丢失,其他MIM方法也有类似问题
输入输出用token不仅提高质量、多样性,对于表示学习,可允许网络在高语义级别上操作而不会丢失低级细节,使得比其他MIM方法有更高的 linear probing 性能。
看图1,MAGE在class-unconditional generation上的性能已经接近了更简单的class-conditional image generation的SOTA表现(~6FID),加上对比学习的MAGE-C还能进一步涨点
Self-supervised Learning in Computer Vision
早期的无监督表示学习重点在设计 pretext 任务,然后训练网络来预测伪标签,这样得到的表示严重落后于监督学习
后面对比学习横空出世,性能接近有监督的预训练,提到SimCLR、MoCo、Contrastive-Multiview-Coding、BYOL
最近MIM很有效,BEiT重建masked输入里的离散视觉token,PeCo把MoCo-v3作为VQGAN训练里的感知模型,进一步得到了更好的tokenizer,MAE吧MIM当做像素级别的降噪重建任务,CMAE进一步将MAE跟对比损失结合起来。其他工作如MaskFeat和MVP预测从教师模型产生的特征。
然而当前基于MIM的自监督学习有利于下游任务表示的性能,而重建图像的质量不行
Generative Models for Image Synthesis.
近年GAN用得多,但不稳定而且模式坍塌。
另一个主流是二阶段系统:首先把图片tokenize到隐空间,然后进行最大似然估计,再从隐空间采样。VQVAE-2就是这样,它比GAN结果更多样。ViT-VQGAN的编码器解码器基于ViT,并在隐空间应用自回归生成。MaskGIT探索用双向Transformer进行token建模,并提出并行解码,有更快的推理速度。最近的扩散模型也在图片合成上取得了更好的效果
但上面的生成模型都无法从图片中抽取高质量的语义表达,也有工作探索用隐特征作为表达的可能性,但表现只有次优。
Method(Model)
Overview
先用预训练的VQGAN将输入图片转换为语义token,然后按[0.5, 1]的比例随机遮掩,再用编解码的Transformer(ViT)架构处理未遮掩的token,以此预测遮住的token,损失用交叉熵。并通过在编码器输出上增加一个类似SimCLR的对比损失来提高所学表达的可分离性。
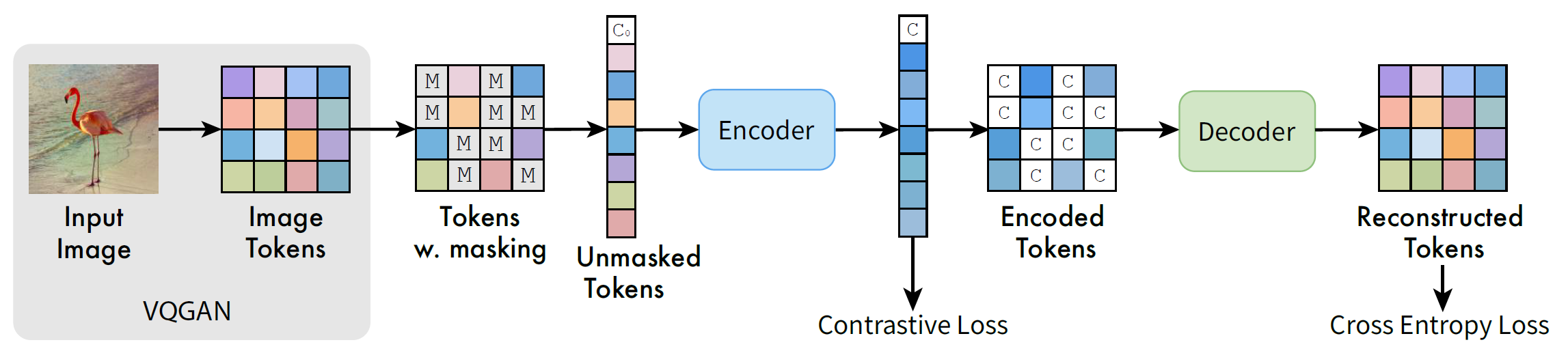
图3 MAGE框架
Pre-traning
Tokenization. 对图片进行tokenize
Masking Strategy. 首先从中心0.55,左0.5右1截断的高斯分布中抽取遮盖比例$ m_r$ ,然后若输入序列长度为 \(l\) ,就随机遮掉 \(m_r \cdot l\) 的token,将其换成可学习的mask token [M],见图3。
因为\(m_r \geq 0.5\),进一步随机丢掉 \(0.5 \cdot l\) 的 masked tokens,这极大加速了训练并减小了内存开销,还有益于生成跟表示的性能
Encoder-Decoder Design. 在mask并且丢弃token之后,将可学习的“假”类别token \([C_0]\) 加到输入序列上,然后序列扔给ViT编码器。编码器输出首先pad回原输入长度,填入学到的 \([C]\)。根据MAE, \([C]\) 可以汇总全局信息,因此用它而不是(MAE那种)可学习的、多图片共享的masking token去pad。
代码中似乎没有使用 casual_mask ,好像预测被遮掩部分是可以利用全局信息的,这样看不就相当于一个 Transformer Encoder? 但看无条件图片生成部分又好像要一步步迭代生成?
Reconstructive Training. 在ground-truth one-hot token跟解码器输出之间使用交叉熵:
其中 \(Y_M\) 是所有token \(Y\) 中未被mask的部分, \(p(y_{i}|Y_{M})\) 是网络基于未遮掩token预测出的概率,并且跟MAE一样只优化那些遮住的token
Contrastive Co-training. 类似SimCLR,编码器输出接GAP,然后再接两层MLP,最终输出加一个InfoNCE损失:
其中z表示两层MLP之后归一化的特征,B是batchsize,\(\tau\)是温度。正样本对是同一张图片的两个增强版本,负样本对是同一个batch中其他的样本,最终损失有:
其中 \(\lambda = 1\) ,不使用对比学习中常用的其他增强:color jitter, random grey scale 或 gaussian noise,因为 reconstructive loss 作为正则化项防止编码器学到一些捷径。但代码里没看到对比损失的使用?
Posttraining Evaluation
图片生成策略采用类似MaskGIT的 iterative decoding。首先给定一张所有token都遮住的空白图片,然后每个iteration就预测剩余仍遮着的token的一部分,并根据预测概率进行采样,然后把相应遮住的token换成采样到的预测token。
每iteration替换的token数量遵循余弦函数,也就是说一开始换的少,后面替换的多,生成一张图片一共用20步。
对于表示学习,就将ViT编码器输出的GAP结果送给分类头
Experiment
Training Detail
输入图片分辨率为256x256,经过VQGAN tokenizer之后token序列长度为16x16(共256个token)。跟MAE一样,使用强随机裁剪、resize(0.21)以及随机翻转作为默认增强。同时也用更弱的随机裁剪、resize版本(0.81),称其为"w.a."
优化器用AdamW,1600epoch,ViT-B的batchsize=4096,ViT-L的batchsize=2048。使用80epoch warmup的余弦学习率调度,基础学习率ViT-B、ViT-L都是 \(1.5 \times 1e^{-4}\),并根据 \(batchsize/256\) 进行缩放。
Dataset
ImageNet-1k
Image Generation
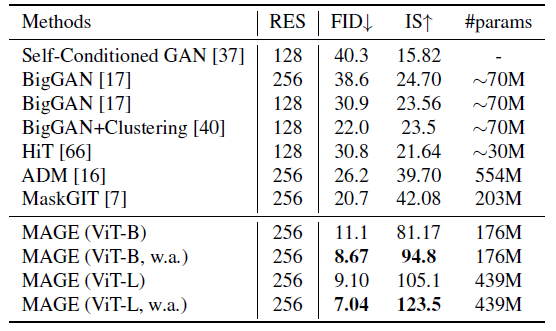
表1 跟SOTA生成模型在class-unconditional generation上ImageNet256x256的定量比较。参数量包括编码器解码器跟detokenizer
Class-Unconditional Image Generation. 不用任务参数上的微调就能实现该任务,结果如表1,结果远超之前的SOTA,作者认为是因为本框架抽取的特征更好。而ViT-L加上弱增强能得到跟 class-conditional generation 相近的性能(比如MaskGIT的6.18)

图4 MAGE (ViT-L)生成的图片 a使用默认策略训练而生成的图片 b训练时的增强较弱 二者的还原度跟多样性都很好
使用强增强策略训练的模型得到的指标更低,作者认为是因为用于计算FID的ImageNet验证集采用中心裁剪并且resize到256,生成的图像的比例较小,FID就更高(更符合验证集的分布?)。但这不代表生成的图片质量就不好,如图4,默认策略生成的图片更放大,更偏离中心,但图片仍然很真实而且质量很高。
Image Classification
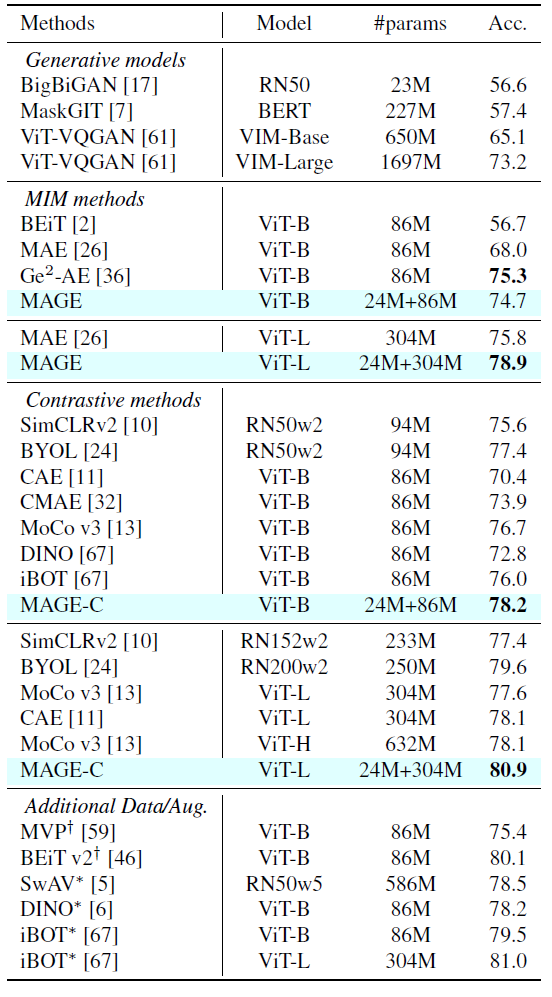
表2 ImageNet-1k上linear probing的top-1精度 十字标识指需要额外的教师模型(CLIP) 星号标识方法用了multi-crop增强 MAGE的参数量包含VQ-GAN tokenizer跟ViT编码器
Linear Probing. 这是自监督评估的一个主要方法,如表2所示,效果很好,而且没使用color jitter, random grey scale, multi-crop augmentations 等增强
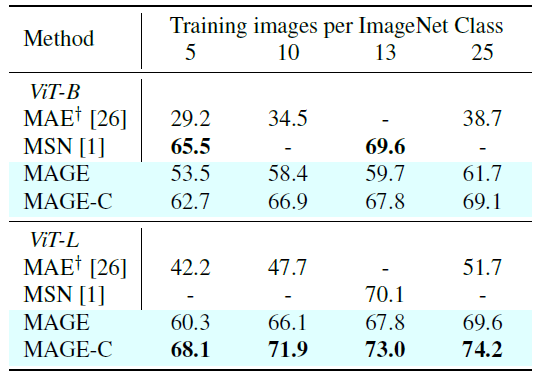
表3 ImageNet-1k上few-shot评估MAE上的十字标识模型由作者实现,MSN标识用了multi-crop augmentation
Few-shot Learning. 冻住预训练模型的权重,然后加一个线性分类器并用少量标注样本去训练,效果比MAE好很多,成为了self-supervised label-efficient learning的SOTA

图5 从ImageNet-1k迁移到另外8个数据集的性能,本文方法在其中6个数据集中超越了SimCLR、MAE
Transfer Learning.另一个自监督表征的重要属性是对不同数据集的可迁移性,在few-shot设置下(每类25样本)评估MAGE的迁移学习能力。如图5所示,因为MAGE在语义token上训练,因此对domain shift更加鲁棒
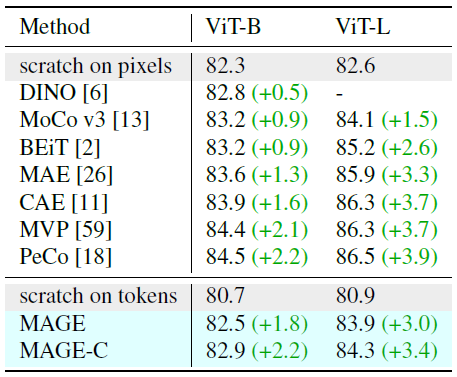
表4 ImageNet-1k上微调表现 在语义token上从头训练的ViT跟原图像素上训练的保持一样的训练设置
Fine-tuning. 表4展示了MAGE跟其他自监督方法的微调性能,所有与训练的编码器参数都会改变。跟DINO一样,但略逊于MoCo v3,作者认为这是量化token的使用导致的,可作为将来的研究方向,而且本文方法较baseline仍有巨大提升。
Analysis
这部分的实验都基于ViT-B,可变mask率的实验训练400epoch,量化tokenization的实验训练1600epoch

表5 MAGE以不同mask比例分布在ImageNet-1k上的top-1精度 当sigma为0的时候,遮盖比例固定,生成质量很差,FID大于50,因此表中直接记为N/A
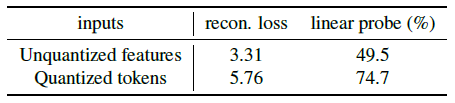
表6 非量化特征跟量化token做输入时的重建损失以及线性探测精度 用非量化特征更容易推断出遮掩的token,因此在线性探测上表现得更差
Masking Design. 看表5,结果显示可变的mask比例很有必要
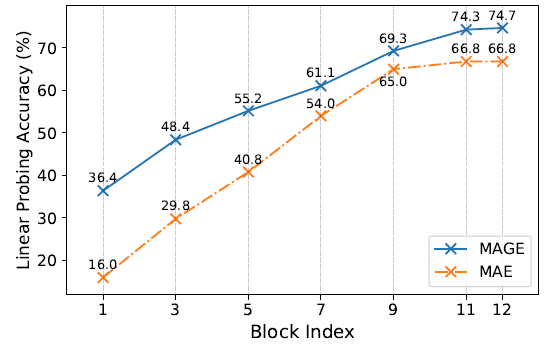
图6 MAE跟MAGE在ViT-B的不同transformer block上的线性探测精度
Tokenization. 用量化的语义token 做输入跟重建目标有不少好处:
- 生成时可以将输出用于下一轮的输入,保证了重建跟生成的高质量跟多样性,如图2图4
- 网络在语义级别上操作,不会丢失低级细节,可抽取更好的表示,如图6所示
- 量化器(quantizer)阻止了VQ-GAN CNN编码器创造的捷径,如果直接用它抽的特征不进行quantization,由于相邻特征像素的感受野严重重叠,很容易用邻近的非量化特征像素去推断mask后的特征像素,如图6所示。这表明预训练任务太简单会导致shortcut solutions,导致学到的表达很差。
最后再贴两张附录的图:

图11 MAGE (ViT-L)做image inpainting的更多结果
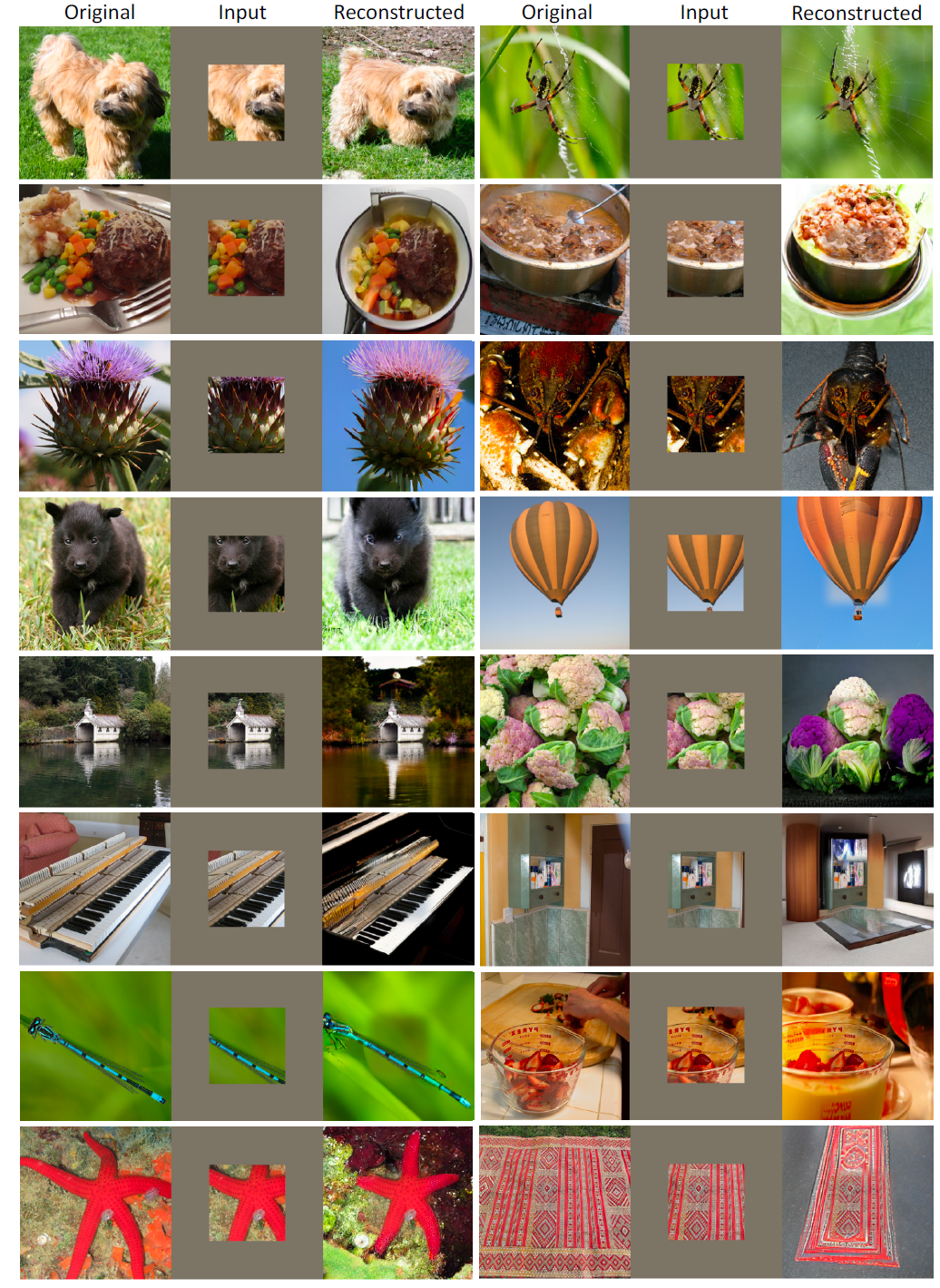
图13 MAGE (ViT-L)做image outpainting on large outpainting mask (uncropping) 的更多结果
Conclusion
MAGE是一个基于masking的方法,它将图片生成跟表示学习统一在一个简单且高效的框架下。方法关键是量化token跟可变masking比例的使用,它是第一个使用相同数据跟训练范式且在两个任务上都达到SOTA的模型,一个自然的后续研究是使用更大的无标注数据及进行训练,如JFT300
Critique
idea很不错,实验内容非常充实(附录还有一堆),而且讲得比较清晰,各种训练细节也有。
代码开源,但没有条件图片生成部分。
Unknown
- Image Classification: Fine-tuning 好像是在ImageNet-1k上预训练,然后再微调的性能,没看懂,具体是在哪个数据集微调? scratch on xx 的结果是将ViT作为baseline得出的?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号