[论文阅读] GAS-NeXt@Few-Shot Cross-Lingual Font Generator
Pre
title: GAS-NeXt: Few-Shot Cross-Lingual Font Generator
accepted: arxiv 2022
paper: https://arxiv.org/abs/2212.02886
code: https://github.com/cmu-11785-F22-55/GAS-NeXt
关键词: few-shot, cross-lingual, font generation
阅读理由: 新作,有代码,简单易读(快速应对组会),对输入多张风格图片的方式有兴趣
Motivation
当前少有模型支持跨语言字体生成,而 AGIS-Net 将字体生成看作I2I任务,局限于只能转换统一语言的,而且依赖于fine-tuning。本文希望结合 AGIS-Net 和 Font Translator GAN 得到一个用于少样本跨语言字体生成的模型。
Idea
在AGIS-Net的基础上直接缝合了FTransGAN,无创新,实验部分算是AGIS-Net的删减版
Background
相关工作分GAN、Font generation、Style Transfer三个方面,讲得都比较简单,其中有提到MX-Font跟CG-GAN,但并未与其进行对比
Method(Model)
Overview
- few-shot:local texture refinement loss(AGIS-Net)
- 跨语言字体生成:加入FTransGAN的上下文感知注意力和层注意力
- 无需fine-tuning:加入FTransGAN的上下文感知注意力和层注意力
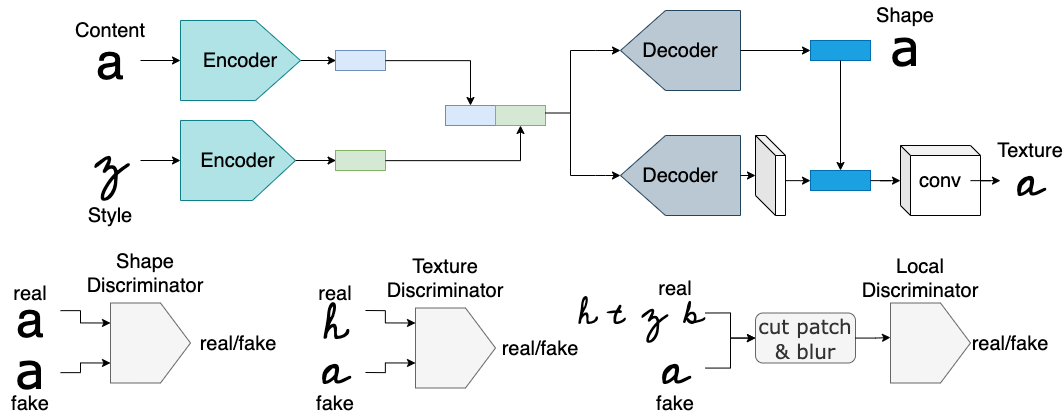
图1 AGIS-Net架构
图1上面是简单的流程示意,下面是三种判别器的例子,从左到右分别是shape判别器、texture判别器、局部判别器
Generator
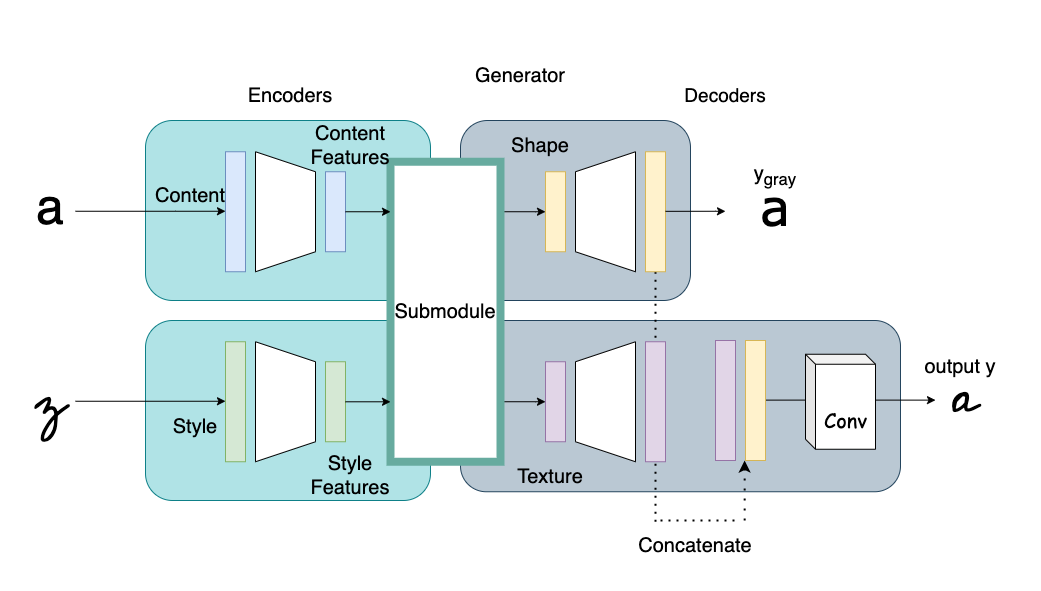
图5 AGIS-Net Generator

图6 AGIS-Net Generator 子模块
这里的decoder相应encoder,也分成两个,content-shape,style-texture。如图5、6,形状解码器拼合上一层的输出,然后从编码器层去抽取内容风格特征以生成形状图片 \(y_{gray}\) 。实际上encoder部分的特征也会通过跳跃连接加入到两个decoder的生成中。
从图6可以看到,纹理编码器通过简单的拼接将形状、纹理信息结合,即两个解码器输出结合在一起,然后通过卷积才能得到输出图片 \(y\)。这图画得很怪,中间那个Submodule应该是多余的
这整个其实就是AGIS-Net的架构跟处理流程,因为AGIS-Net做的是彩色字体的转换,其中texture指的是是真实样本,带颜色、形状的,shape是它的灰度版本,没颜色。两个解码器相当于把生成分为了两步:先生成形状再上色。
实际上根据shape跟texture的定义,本文中这两个岂不是同一个东西?毕竟作者用的图片都是二元的,没有texture一说
Discriminator
这部分作者没写,那就看下AGIS-Net的,反正都一样,就是图1里下部的三个判别器

图AGIS-Net-2 模型架构

图AGIS-Net-4 局部判别器
局部判别器就是对图片随机裁剪,然后施加高斯模糊来得到负样本,然后其他两个判别器是PatchGAN。
Objective Function
目标函数共4项,分别是对抗损失,L1损失,上下文损失跟局部纹理精炼损失,即 \(L_{adv} + L_{1} + L_{CX} + L_{local}\)
Adversarial Loss 略
L1 Loss 计算 \(y_{gray},\; y\) 与各自groundtruth的L1距离,其中 \(y\) 那一项的权重更大,也就是说转换的结果相比shape更重要?
Contextual Loss 似乎来自The Contextual Loss for Image Transformation with Non-Aligned Data,说L1 Loss和L2 Loss这种损失需要图像对齐,而Contextual Loss可用于非对齐数据,不使用GAN也可以有好的风格转换效果
根据本论文的介绍,该损失度量图片特征图之间的相似度,聚焦于高层风格特征。令 \(x_i,\; y_i\) 分别表示 \(X,\; Y\) 第i个/第j个特征图,则 \(x_i,\; y_i\) 之间的相似度CX定义为移位归一化余弦距离的归一化指数(normalized exponential of the shifted normalized cosine distances):
这里 \(d_{ij}\) 是 \(x_i,\; y_i\) 之间的余弦距离, \(h,\; \epsilon\) 是超参数,分别设置为 0.5, 1e-5
特征用预训练好的VGG19抽取, \(\phi^l\) 表示VGG19的第l层所抽取的特征,实验中取 \(\lambda_{CXgray}=15.0,\; \lambda_{CXtex}=25.0\) ,contextual loss如下:
大概就是用VGG19每一层抽取的每一个特征图去计算相似度,用它们之间的余弦相似度来确定特征之间的差距。说是效果好,但感觉计算代价不小
Local Textual Refinement Loss 局部判别器 \(D_{local}\) 将裁剪的真实图片patch 作为正样本,而模糊化的真图片patch、合成的图片patch作为负样本,损失写为下列形式:
其中 \(\lambda_{l o c a l}=1.0\) ,这是AGIS-Net提出用来做 few-shot 风格转换任务的,说是新颖且计算高效
Experiment
Training Detail
给出三个指标的表达式:
Pixel-level Accuracy (pix-acc)
PA是Pixel-level Accuracy (pix-acc),其中 \(n_{jj}\) 表示类别j的正确数量, \(t_j\) 是标记为类别j的像素数量。使用灰度图去评估,因此类别是二元的,总之取平均的像素级精度去评估合成图片的总体质量。
Dataset
找了一些现成的数据集,包括CASIA那个,说考虑到纯上下文输入(plain context inputs),对于汉字使用尽可能常见的平均字体风格,而英文字母就用MC-GAN的Code New Roman

图AGIS-Net-5 英文/中文数据集中内容输入字形图片的例子
Results

表1 AGIS-Net和baseline评估指标
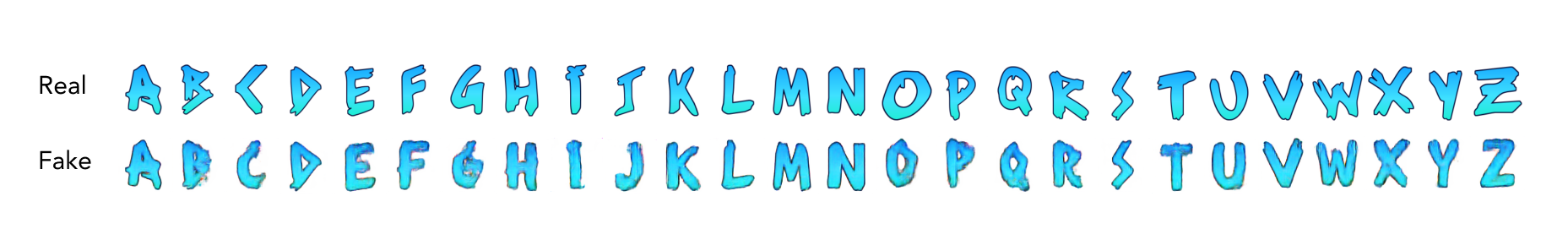
图2 生成字体的例子
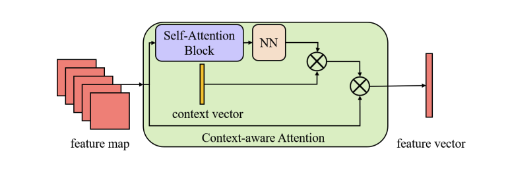
图11 上下文感知注意力

图12 层注意力
作者缝上了FTransGAN,使用上下文感知注意力去捕获局部风格特征,利用层注意力捕获全局风格特征。判别器方面就是FTransGAN的加上AGIS-Net的局部判别器。图11、图12直接就照搬FTransGAN的原图,清晰度还不行。这部分可参看之前写过的FTransGAN阅读笔记

图4 模型生成结果对比
Results(AGIS-Net)
补一点AGIS-Net的结果,因为更细致,而且有本文没做的彩色字体生成结果

图AGIS-Net-6 艺术字形图片合成的例子

图AGIS-Net-7 跟其他模型结果对比
AGIS-Net还做了更多的实验,比如调整few-shot样本数、输入的风格图片数量,对局部风格损失、上下文损失跟跳跃连接的消融实验、其他语言转换、失败样本、跟其他模型比较shape...
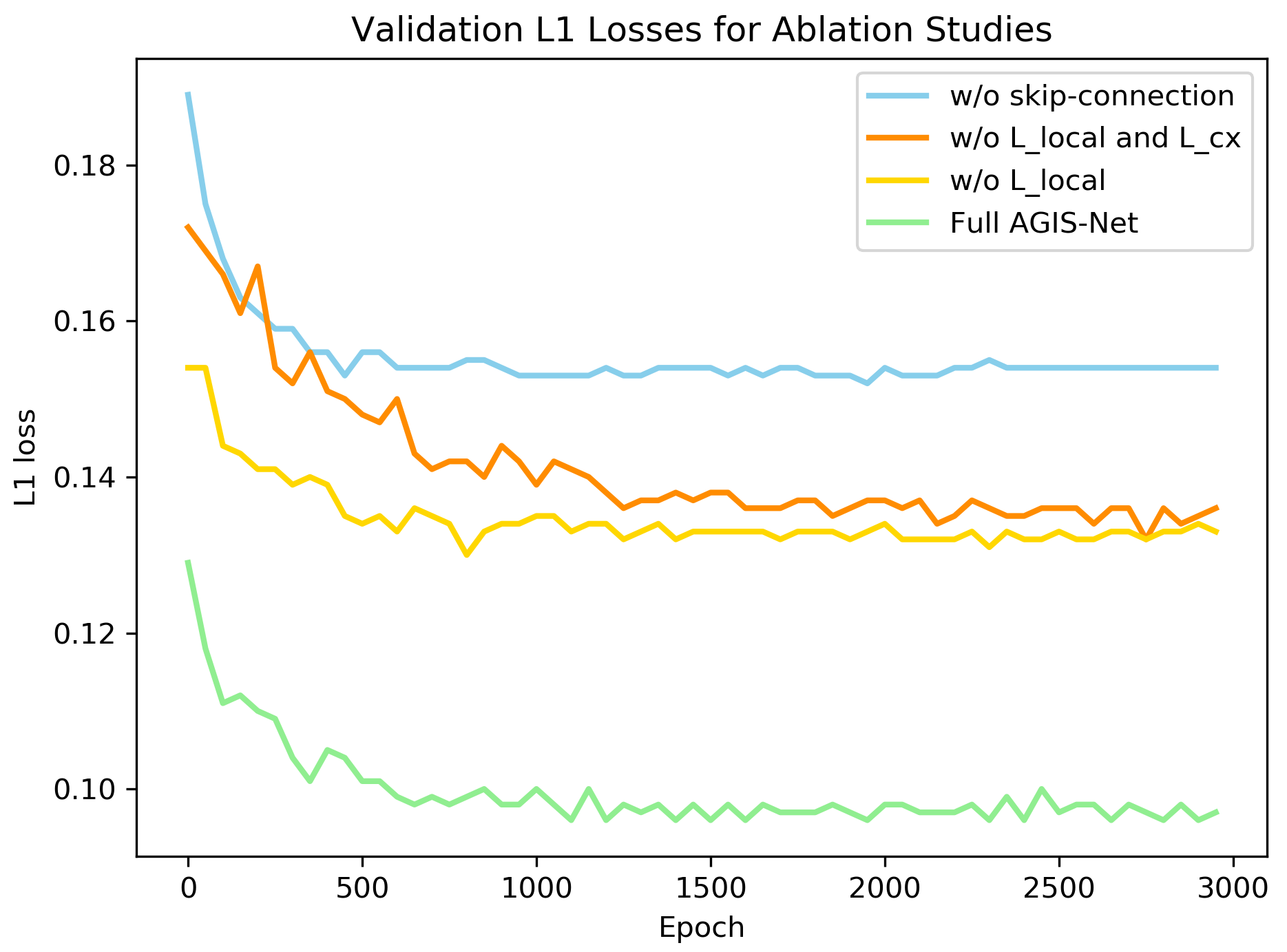
图AGIS-Net-13 fine-tuning阶段对所有字形图片进行消融的L1损失

图AGIS-Net-17 用预训练、few-shot learning都没见过的汉字进行合成

图AGIS-Net-18 用汉字字形图片训练的模型去合成日文韩文
Conclusion
指标上跟FTransGAN接近,但局部细节处的视觉效果比它好一些,看图4。说不知道有关于跨语言字体生成的正式讨论,本文的模型就给将来这方面的研究充当了一个基础。
将来工作一方面可以深挖局部判别器,另一方面可以做彩色字体风格,本文模型对于彩色字体的生成并不理想,作者尝试过将三通道分离然后分别生成,最后把三个通道重建为一个图片,但效果很差,因为三个通道在不同的像素区域生成结果,导致不完全的重叠。
不过彩色字体很少看到有工作在做,好像不是很实用?而且这个更贴近风格迁移,I2I那些
Critique
本文似乎是卡内基梅隆大学的某一次课程作业的结果,三个作者应该都是在校生。就文章来说确实是水一些,可以理解,感觉就本科毕设水平。
低情商:缝合怪;高情商:一篇顶俩。总之收获还是有的,看这篇相当于看了AGIS-Net,行文模型到效果都差不多,那个 Contextual Loss 之前确实没听说过。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号