

阿里云服务器centos7.3下搭建hadoop伪分布式环境
一、软硬件环境
CentOS 7.2 64位
OpenJDK-1.8.0
Hadoop-2.7
二、安装SSH客户端
安装ssh:
yum install openssh-clients openssh-server
(如果系统中没有yum命令使用 sudo apt install yum安装 如有lock问题参看如下解决方法)
当我的Ubuntu install某个东西时,给出下面提示 E: Could not get lock /var/lib/dpkg/lock-frontend - open (11: Resource temporarly unavailable) E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), is an other process using it? 删除锁定文件,行了 sudo rm /var/lib/dpkg/lock-frontend sudo rm /var/lib/dpkg/lock
安装完成后,使用以下命令测试:
①查看是否安装成功:
rpm -qa | grep ssh
②启动SSH服务。
systemctl restart sshd
ssh localhost
输入 root 账户的密码,如果可以正常登录,则说明SSH安装没有问题。
配置SSH免key登陆
hadoop是一个分布式系统,节点间通过ssh通信,为了避免在连接过程中人工输入密码,需要进行ssh免key登陆的配置,由于本例是在单机上模拟分布式过程,因此需要针对本机(localhost)进行免key登陆的配置。 依此输入如下命令进行配置:
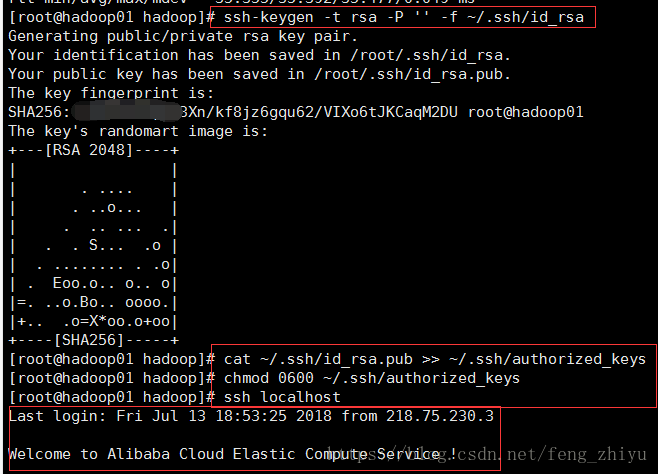
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
完成后尝试用SSH连接本机,如果不需要输入密码就能登陆,说明配置成功: ssh localhost
结果显示:
三、配置Java环境
安装jdk
使用 yum 来安装1.8版本 OpenJDK:
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
(如果之前已经安装了jdk,可以通过which java找到安装的路径,我之前已经安装好了)
安装完成后,键入java和javac,如果能输出对应的命令帮助,则表明jdk已正确安装。
配置java环境变量
执行命令:
vim ~/.bashrc
在结尾追加:(jvm中java-1.8.0.???具体是多少自己看一下可能版本换了)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
保存文件后执行下面命令使 JAVA_HOME 环境变量生效:
source ~/.bashrc
为了检测系统中java环境是否已经正确配置并生效,可以分别执行以下命令:
java -version $JAVA_HOME/bin/java -version
若两条命令输出的结果一致,且都为我们前面安装的 openjdk-1.8.0 的版本,则表明 JDK 环境已经正确安装并配置。
四.安装hadoop
下载 Hadoop
本教程使用 hadoop-2.7 版本,使用 wget 工具在线下载
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/hadoop-2.7.5.tar.gz
(这种下载方式可能比较慢)
建议从别处(百度云或者其他镜像)下载好了拷贝过来
安装 Hadoop
将 Hadoop 安装到 /usr/local 目录下:
tar -zxf hadoop-2.7.5.tar.gz -C /usr/local
对安装的目录进行重命名,便于后续操作方便:
mv ./hadoop-2.7.5/ ./hadoop
提示No such file or directory:需要先切换到local路径下再执行
在hadoop中配置环境变量
检查Hadoop是否已经正确安装:
/usr/local/hadoop/bin/hadoop version
Error:
JAVA_HOME is not set and could not be found.
echo $java_home 为空
注意区分大小写:echo $JAVA_HOME即可输出正确路径
如果成功输出hadoop的版本信息,表明hadoop已经成功安装。

五.hadoop伪分布式环境配置
(1)设置 Hadoop 的环境变量
编辑 ~/.bashrc,在结尾追加如下内容:
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使Hadoop环境变量配置生效:
source ~/.bashrc
修改 Hadoop 的配置文件
Hadoop的配置文件位于安装目录的 /etc/hadoop目录下,在本教程中即位于 /usr/local/hadoop/etc/hadoop 目录下,需要修改的配置文件为如下两个:
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
(2)编辑core-site.xml,修改<configuration></configuration>节点的内容为如下所示:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>location to store temporary files</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
(3)配置HDFS文件,编辑 hdfs-site.xml,修改<configuration></configuration>节点的内容为如下所示:
<configuration> //设置HDFS文件副本数
<property> <name>dfs.replication</name> <value>1</value> </property>
//设置HDFS元数据文件存放路径 <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property>
<property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hodoop/tmp/dfs/data</value> </property>
//设置其他用户执行操作是会提醒没有权限的问题
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(4)(5)的xml位置没找到,未进行配置
(4)配置MapReduce文件mapred-site.xml
<property> <name>mapreduce.framework</name> <value>yarn</value> </property>
(5)配置YARN文件yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
(6)从节点配置文件slaves
hadoop000
格式化NameNode:
/usr/local/hadoop/bin/hdfs namenode -format
输出以下信息表示格式化成功:

启动NameNode和DataNode进程:
/usr/local/hadoop/sbin/start-dfs.sh
执行过程中会提示输入用户密码,输入 root 用户密码即可。另外,启动时ssh会显示警告提示是否继续连接,输入 yes 即可
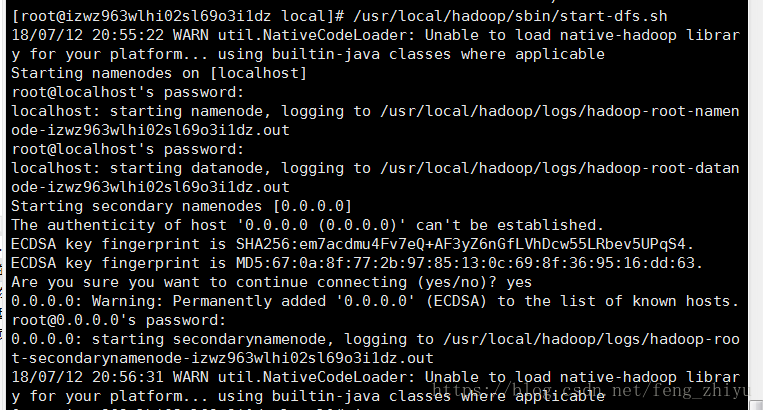
检查NameNode和DateNode是否正常启动。
jps
如果NameNode和DataNode已经正常启动,会显示NameNode、DataNode和SecondaryNameNode的进程信息:

如果jps命令后只显示jps的进程无其余三个进程信息,处理措施:
检查xml文件修改的是否正确
六、运行伪分布式实例
查看Hadoop自带的例子
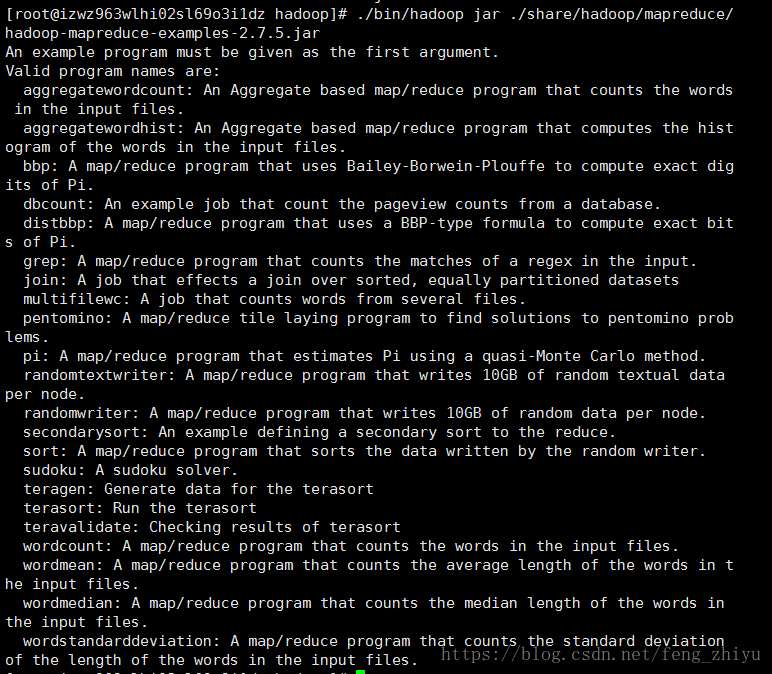
Hadoop附带了丰富的例子,执行以下命令查看:
cd /usr/local/hadoop ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
在HDFS中创建用户目录hadoop:
准备实验数据
本教程中,我们将以 Hadoop 所有的 xml 配置文件作为输入数据来完成实验。执行下面命令在 HDFS 中新建一个 input 文件夹并将 hadoop 配置文件上传到该文件夹下:
/usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
此时会出现警告:

原因:
Apache提供的hadoop本地库是32位的,而在64位的服务器上就会有问题,因此需要自己编译64位的版本。
1、首先找到对应自己hadoop版本的64位的lib包,可以自己手动去编译,但比较麻烦,也可以去网上找,好多都有已经编译好了的。
2、可以去网站:http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 下载对应的编译版本
3、将准备好的64位的lib包解压到已经安装好的hadoop安装目录的lib/native 和 lib目录下:
下载hadoop版本2.7.5对应的64位的lib包:
[root@izwz963wlhi02sl69o3i1dz hadoop]#
wget http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.7.0.tar

解压到已经安装好的hadoop安装目录的lib/native 和 lib目录下:
[root@izwz963wlhi02sl69o3i1dz hadoop]# tar -xvfhadoop-native-64-2.7.0.tar -C /usr/local/hadoop/lib/native [root@izwz963wlhi02sl69o3i1dz hadoop]# tar -xvfhadoop-native-64-2.7.0.tar -C /usr/local/hadoop/lib

4、添加环境变量
[root@izwz963wlhi02sl69o3i1dz hadoop]# vim /etc/profile
5、添加以下内容
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
6、让环境变量生效
[root@izwz963wlhi02sl69o3i1dz hadoop]# source /etc/profile
source 后边有空格
7、自检hadoop checknative –a 指令检查
再次在HDFS 中创建用户目录 hadoop:
/usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
![]()
不再出现警告。
准备实验数据
本教程中,我们将以 Hadoop 所有的 xml 配置文件作为输入数据来完成实验。执行下面命令在 HDFS 中新建一个 input 文件夹并将 hadoop 配置文件上传到该文件夹下:
[root@izwz963wlhi02sl69o3i1dz hadoop]# cd /usr/local/hadoop
[root@izwz963wlhi02sl69o3i1dz hadoop]# ./bin/hdfs dfs -mkdir /user/hadoop/input
[root@izwz963wlhi02sl69o3i1dz hadoop]# ./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
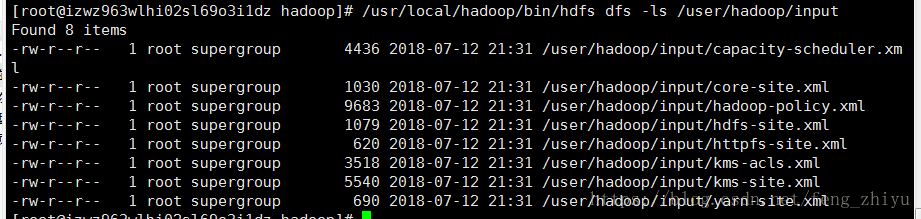
使用下面命令可以查看刚刚上传到 HDFS 的文件:
/usr/local/hadoop/bin/hdfs dfs -ls /user/hadoop/input
运行实验:
[root@izwz963wlhi02sl69o3i1dz hadoop]# cd /usr/local/hadoop
[root@izwz963wlhi02sl69o3i1dz hadoop]# ./bin/hadoopjar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar grep/user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
[root@izwz963wlhi02sl69o3i1dz hadoop]# cd/usr/local/hadoop [root@izwz963wlhi02sl69o3i1dz hadoop]# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
上述命令以 HDFS 文件系统中的 input 为输入数据来运行 Hadoop 自带的 grep 程序,提取其中符合正则表达式 dfs[a-z.]+ 的数据并进行次数统计,将结果输出到 HDFS 文件系统的 output 文件夹下。
查看运行结果
上述例子完成后的结果保存在 HDFS 中,通过下面命令查看结果:
红色圈出的部分是运行成功的结果:
/usr/local/hadoop/bin/hdfs dfs -cat /user/hadoop/output/*

删除HDFS 中的结果目录:
/usr/local/hadoop/bin/hdfs dfs -rm -r /user/hadoop/output

运行Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录不能存在,否则会提示错误,因此在下次运行前需要先删除输出目录。
(一)HDFS操作
关闭Hadoop进程:
/usr/local/hadoop/sbin/stop-dfs.sh
再次启动Hadoop进程的命令:
①一次性启动所有进程:
[root@izwz963wlhi02sl69o3i1dz hadoop]#/usr/local/hadoop/sbin/start-dfs.sh
②单独启动某个进程
hadoop-daemon.sh start namenode/datanode/secondarynode
七、部署完成
参考:
官方文档
https://blog.csdn.net/feng_zhiyu/article/details/81018869

 浙公网安备 33010602011771号
浙公网安备 33010602011771号