
本文参考康琪大佬的博客:使Flink SQL Kafka Source支持独立设置并行度
一直觉得 Flink Sql 需要指定算子并行度的功能,哪怕是基于 SQL 解析出来的算子不能添加并行度,source、sink、join 的算子也应该有修改并行度的功能。
恰好看到大佬的博客,Kafka 是最常用的数据源组件了,所以决定在 sqlSubmit 中也加入相应的实现。
Streaming Api 设置并行度
基于 Flink Streaming api,要给 Kafka Source 指定并行度,只需要在 env.addSource() 后面调用 setParallelism() 方法指定并行度就可以,如下:
val kafkaSource = new FlinkKafkaConsumer[ObjectNode](topic, new JsonNodeDeserializationSchema(), Common.getProp)
val stream = env.addSource(kafkaSource)
.setParallelism(12)
Sql Api 设置并行度
先看一个读kafka 的 SQL
-- kafka source
CREATE TABLE user_log (
user_id STRING
,item_id STRING
,category_id STRING
,behavior STRING
,ts TIMESTAMP(3)
,process_time as proctime()
, WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
);
CREATE TABLE user_log_sink (
`day` string
,num bigint
,min_user_id bigint
,max_user_id bigint
) WITH (
'connector' = 'print'
);
insert into user_log_sink
select `day`
, num
, min_user_id, max_user_id
from(
select DATE_FORMAT(ts,'yyyyMMdd') `day`
,count(distinct user_id) num
,min(cast(replace(user_id,'xxxxxxxxxxxxx','') as bigint)) min_user_id
,max(cast(replace(user_id,'xxxxxxxxxxxxx','') as bigint)) max_user_id
from user_log
-- where DATE_FORMAT(ts,'yyyyMMdd') = date_format(current_timestamp, 'yyyyMMdd')
group by DATE_FORMAT(ts,'yyyyMMdd')
)t1
where num % 2 = 0
;
流图如下:
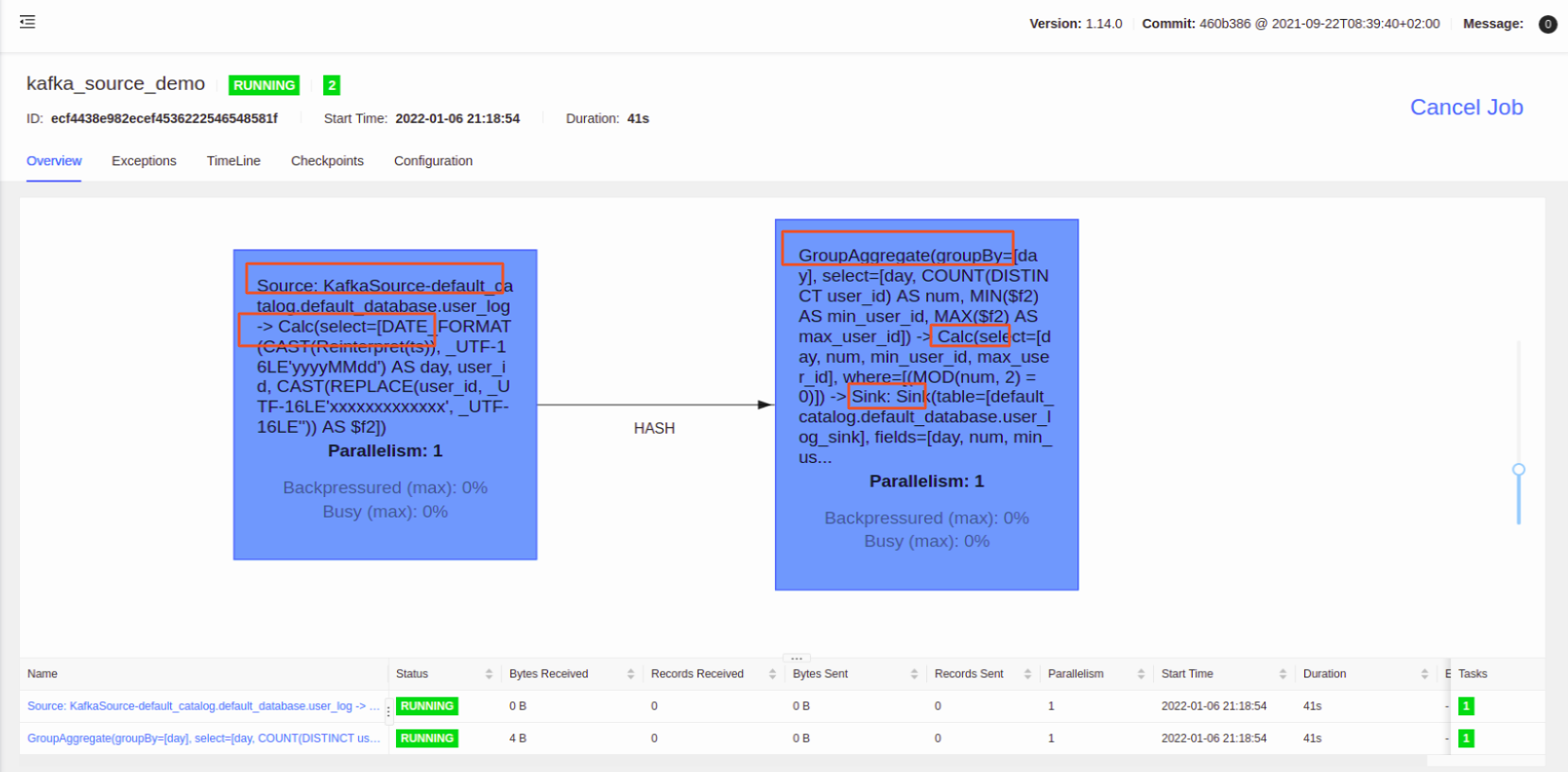
仔细看任务流图,所有的算子的并行度都是参数: table.exec.resource.default-parallelism 指定的
要修改 Source 的并行度,其他算子的并行度保持不变,从 Streaming Api 看,只需要给 sql 翻译后的 StreamSource 指定并行度,就可以做到我们想要的结果。
那就直接找到 flink sql 源码 kafka source 创建的地方: KafkaDynamicSource.getScanRuntimeProvider 方法
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext context) {
final DeserializationSchema<RowData> keyDeserialization =
createDeserialization(context, keyDecodingFormat, keyProjection, keyPrefix);
final DeserializationSchema<RowData> valueDeserialization =
createDeserialization(context, valueDecodingFormat, valueProjection, null);
final TypeInformation<RowData> producedTypeInfo =
context.createTypeInformation(producedDataType);
final KafkaSource<RowData> kafkaSource =
createKafkaSource(keyDeserialization, valueDeserialization, producedTypeInfo);
return new DataStreamScanProvider() {
@Override
public DataStream<RowData> produceDataStream(StreamExecutionEnvironment execEnv) {
if (watermarkStrategy == null) {
watermarkStrategy = WatermarkStrategy.noWatermarks();
}
// 创建 DataStreamSource
return execEnv.fromSource(
kafkaSource, watermarkStrategy, "KafkaSource-" + tableIdentifier);
}
@Override
public boolean isBounded() {
return kafkaSource.getBoundedness() == Boundedness.BOUNDED;
}
};
}
从源码可以看到创建了 KafkaSource ,并且 调用了 execEnv.fromSource 方法,按照 Streaming api 的思路,直接在 execEnv.fromSource 后面添加 setParallelism 就好了,改好的代码如下:
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext context) {
final DeserializationSchema<RowData> keyDeserialization =
createDeserialization(context, keyDecodingFormat, keyProjection, keyPrefix);
final DeserializationSchema<RowData> valueDeserialization =
createDeserialization(context, valueDecodingFormat, valueProjection, null);
final TypeInformation<RowData> producedTypeInfo =
context.createTypeInformation(producedDataType);
final KafkaSource<RowData> kafkaSource =
createKafkaSource(keyDeserialization, valueDeserialization, producedTypeInfo);
return new DataStreamScanProvider() {
@Override
public DataStream<RowData> produceDataStream(StreamExecutionEnvironment execEnv) {
if (watermarkStrategy == null) {
watermarkStrategy = WatermarkStrategy.noWatermarks();
}
DataStreamSource<RowData> dataDataStreamSource = execEnv.fromSource(
kafkaSource, watermarkStrategy, "KafkaSource-" + tableIdentifier);
int defaultParallelism = execEnv.getParallelism();
// add by venn for custom source parallelism
// 很多任务不需要设置并行度,所以加了个判空条件
// 如果设置的并行度等于 全局的并行度也不做处理
if (parallelism != null && parallelism > 0 && parallelism != defaultParallelism) {
dataDataStreamSource.setParallelism(parallelism);
// todo 参考博客的大佬有断开 source 算子和后续算子的 算子链,我觉得不需要,如果并行度不一样自动会断开
// 并行度一样,也不需要断开算子链
// dataDataStreamSource.disableChaining();
}
return dataDataStreamSource;
}
@Override
public boolean isBounded() {
return kafkaSource.getBoundedness() == Boundedness.BOUNDED;
}
};
}
并行度设置需要在 Kafka Table Source 配置项中添加并行度的配置,参考 Flink 自定义 Http Table Source 自定义 source 中获取配置 sql ddl 中的参数的方法:
- 在 KafkaConnectorOptions 类中添加配置项
public static final ConfigOption<Integer> SOURCE_PARALLELISM
= ConfigOptions.key("source.parallelism")
.intType()
.noDefaultValue()
.withDescription("Defines a custom parallelism for the source. By default, if this option is not defined, the planner will derive the parallelism for each statement individually by also considering the global configuration.");
- 在 KafkaDynamicTableFactory 中添加可选参数: SOURCE_PARALLELISM 和 获取参数值并传递到创建 Kafka Source 的地方
添加可选参数不添加,解析 sql DDL 时,无法解析参数
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(FactoryUtil.FORMAT);
options.add(KEY_FORMAT);
options.add(KEY_FIELDS);
options.add(KEY_FIELDS_PREFIX);
options.add(VALUE_FORMAT);
options.add(VALUE_FIELDS_INCLUDE);
options.add(TOPIC);
options.add(TOPIC_PATTERN);
options.add(PROPS_GROUP_ID);
options.add(SCAN_STARTUP_MODE);
options.add(SCAN_STARTUP_SPECIFIC_OFFSETS);
options.add(SCAN_TOPIC_PARTITION_DISCOVERY);
options.add(SCAN_STARTUP_TIMESTAMP_MILLIS);
options.add(SINK_PARTITIONER);
options.add(SINK_PARALLELISM);
options.add(DELIVERY_GUARANTEE);
options.add(TRANSACTIONAL_ID_PREFIX);
options.add(SINK_SEMANTIC);
options.add(SOURCE_PARALLELISM);
return options;
}
解析参数:
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
.....
// 字段值可能为空,所以类型为 Integer
final Integer parallelism = tableOptions.getOptional(SOURCE_PARALLELISM).orElse(null);
return createKafkaTableSource(
physicalDataType,
keyDecodingFormat.orElse(null),
valueDecodingFormat,
keyProjection,
valueProjection,
keyPrefix,
getSourceTopics(tableOptions),
getSourceTopicPattern(tableOptions),
properties,
startupOptions.startupMode,
startupOptions.specificOffsets,
startupOptions.startupTimestampMillis,
context.getObjectIdentifier().asSummaryString(),
parallelism);
}
新加一个 createKafkaTableSource 的重载方法,添加 parallelism 变量为参数
protected KafkaDynamicSource createKafkaTableSource(
DataType physicalDataType,
@Nullable DecodingFormat<DeserializationSchema<RowData>> keyDecodingFormat,
DecodingFormat<DeserializationSchema<RowData>> valueDecodingFormat,
int[] keyProjection,
int[] valueProjection,
@Nullable String keyPrefix,
@Nullable List<String> topics,
@Nullable Pattern topicPattern,
Properties properties,
StartupMode startupMode,
Map<KafkaTopicPartition, Long> specificStartupOffsets,
long startupTimestampMillis,
String tableIdentifier,
Integer parallelism) {
return new KafkaDynamicSource(
physicalDataType,
keyDecodingFormat,
valueDecodingFormat,
keyProjection,
valueProjection,
keyPrefix,
topics,
topicPattern,
properties,
startupMode,
specificStartupOffsets,
startupTimestampMillis,
false,
tableIdentifier,
parallelism);
}
KafkaDynamicSource 构造方法中添加 Integer 类型的变量 parallelism 接收 KafkaDynamicTableFactory 传递过来的 parallelism 参数。
大功告成了吗,测试一下先
全部SQL 同上,在 kafka source 的属性中添加参数: 'source.parallelism' = '2'
- 注: 全局并行度为 1
CREATE TABLE user_log (
user_id STRING
,item_id STRING
,category_id STRING
,behavior STRING
,ts TIMESTAMP(3)
,process_time as proctime()
, WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
,'source.parallelism' = '2'
);
任务流图:
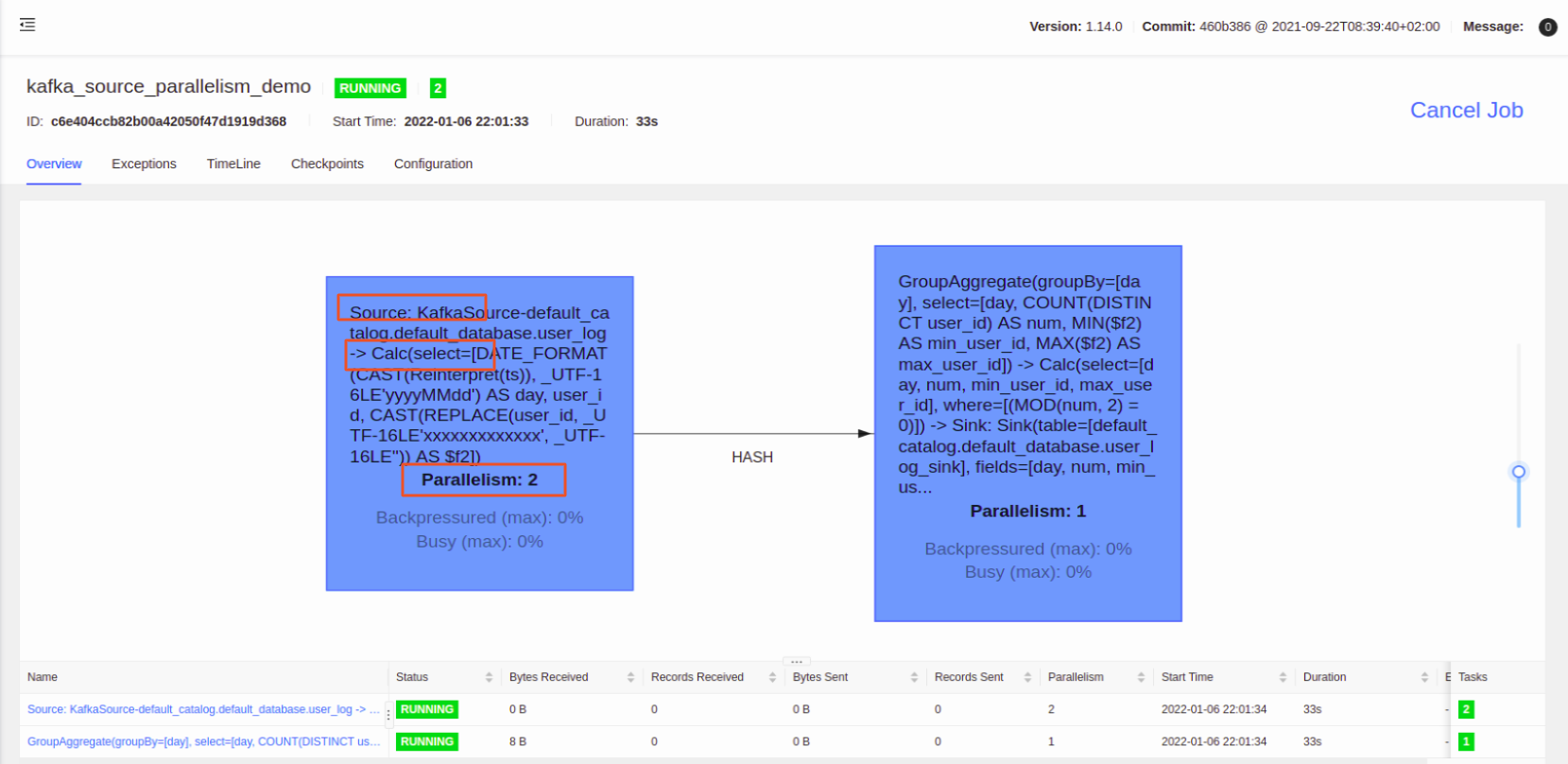
算子的并行度跟预期的有点不一样,只设置了 source 的并行度,后续的 Calc 的并行度也跟着变了
查看 Calc 算子的源码可以看到:
@Override
protected Transformation<RowData> translateToPlanInternal(PlannerBase planner) {
final ExecEdge inputEdge = getInputEdges().get(0);
final Transformation<RowData> inputTransform =
(Transformation<RowData>) inputEdge.translateToPlan(planner);
final CodeGeneratorContext ctx =
new CodeGeneratorContext(planner.getTableConfig())
.setOperatorBaseClass(operatorBaseClass);
final CodeGenOperatorFactory<RowData> substituteStreamOperator =
CalcCodeGenerator.generateCalcOperator(
ctx,
inputTransform,
(RowType) getOutputType(),
JavaScalaConversionUtil.toScala(projection),
JavaScalaConversionUtil.toScala(Optional.ofNullable(this.condition)),
retainHeader,
getClass().getSimpleName());
return new OneInputTransformation<>(
inputTransform,
getDescription(),
substituteStreamOperator,
InternalTypeInfo.of(getOutputType()),
inputTransform.getParallelism());
}
substituteStreamOperator 就是 CodeGen 生产的 Calc 算子,并行度直接取的输入算子的并行度 inputTransform.getParallelism()
所以 Calc 算子的并行度和 Kafka source 的并行度一样,修改源码将并行度设置为 全局并行度
protected Transformation<RowData> translateToPlanInternal(PlannerBase planner) {
final ExecEdge inputEdge = getInputEdges().get(0);
final Transformation<RowData> inputTransform =
(Transformation<RowData>) inputEdge.translateToPlan(planner);
final CodeGeneratorContext ctx =
new CodeGeneratorContext(planner.getTableConfig())
.setOperatorBaseClass(operatorBaseClass);
final CodeGenOperatorFactory<RowData> substituteStreamOperator =
CalcCodeGenerator.generateCalcOperator(
ctx,
inputTransform,
(RowType) getOutputType(),
JavaScalaConversionUtil.toScala(projection),
JavaScalaConversionUtil.toScala(Optional.ofNullable(this.condition)),
retainHeader,
getClass().getSimpleName());
// add by venn for custom source parallelism
int parallelism = inputTransform.getParallelism();
int defaultParallelism = ExecutionConfig.PARALLELISM_DEFAULT;
if (parallelism != defaultParallelism) {
// update calc operator parallelism to default parallelism
parallelism = defaultParallelism;
}
return new OneInputTransformation<>(
inputTransform,
getDescription(),
substituteStreamOperator,
InternalTypeInfo.of(getOutputType()),
parallelism);
}
生成完的算子流图:
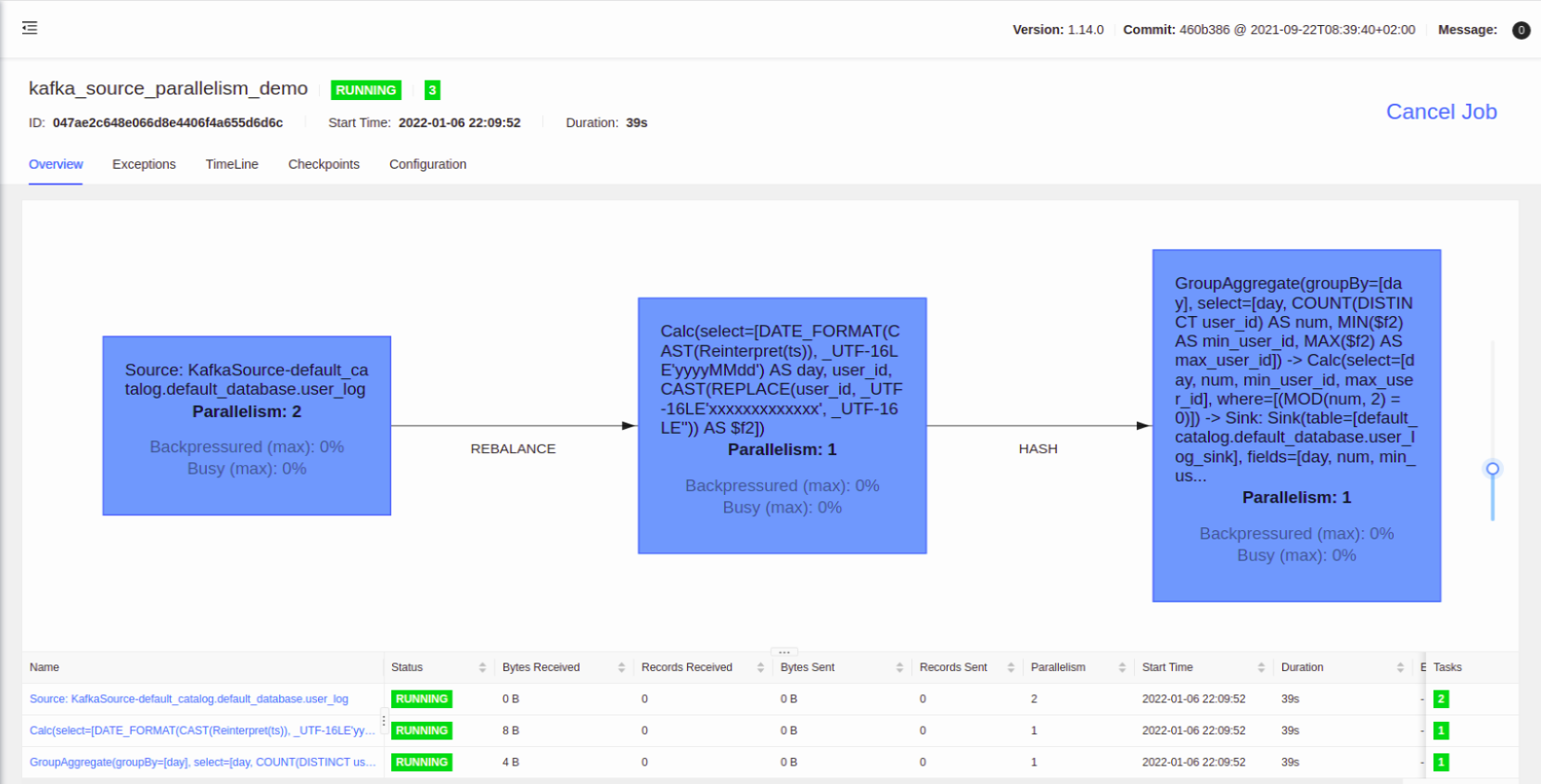
现在才大功告成
完整代码参考: github sqlSubmit
-----------------------分割线------------------------------------
- 2022-01-13 改
在 sqlSubmit 的配置文件中添加了参数: table.exec.source.force-break-chain ,用以在 kafka sql source 后面判断是否要断开下游算子和 source 的 chain。
由于在 CommonExecCalc 拿不到 ddl 中定义的参数,添加了一个任务级别的参数( 在 sqlSubmit.properties 中添加参数 table.exec.source.force-break-chain 默认值为 false,如果为 true 会断开 chain),通过 env 放到 GlobalJobParameter 中,KafkaDynamicSource 通过 env 从 GlobalJobParameter 中取,CommonExecCalc 有 planner 可以直接拿到任务级别的参数。
- 对于指定了 kafka sql source 的情况,是否需要断开 source 算子和后续的算子:根据 source 的并行度和默认并行度判断是否断开,还是用参数控制是否断开。最后还是决定安装大佬博客里的写的,用参数控制是否断开。主要是source 和后续算子的关系不定,如果只是基于并行度判断是否 chain 在一起太过僵硬,还不如再加一个参数控制,这样默认算子会 chain 在一起,下游算子和 source 并行度保持一致,如果需要端口,后续算子的并行度会和全局并行度保持一致。
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号