字符串和编码
背景:
日常工作中,或多或少的都会遇到编码问题,大都定义为UTF-8 或者GB2312 都能处理,但是总觉得一知半解,今稍微总结下
白话理解:
1.字符编码产生原因:
在计算机底层存储中都是由一串01编码组成的二进制文件,但是人类无法读懂复杂冗长的二进制文件,所以编码的产生就是为了将人类文字和二进制文件相互转换。
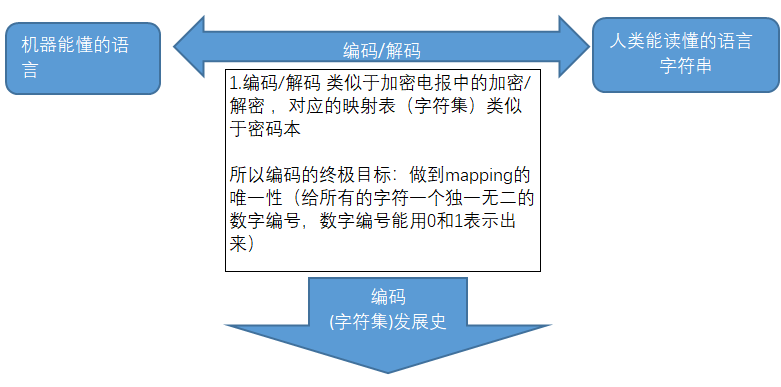
2.字符编码(密码本 字符集)的发展史:
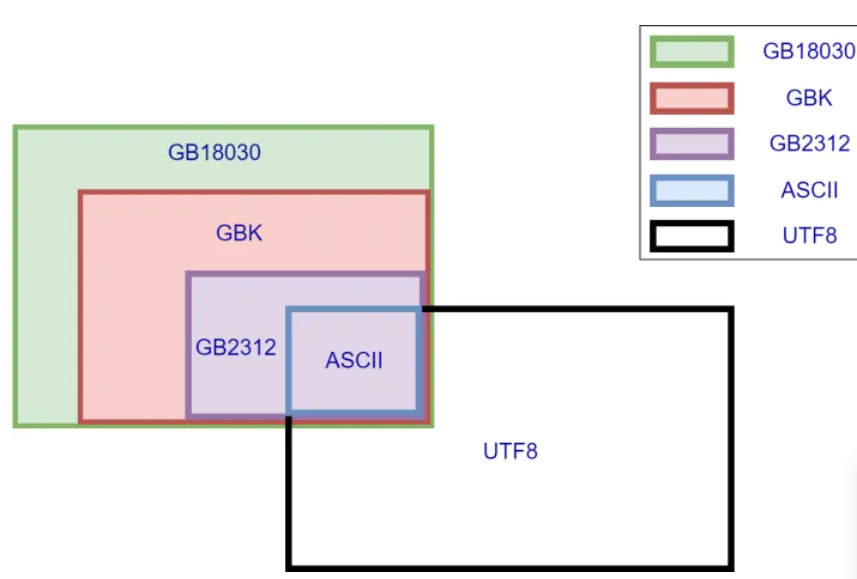
字符编码的发展细节查看摘录部分,此处想说的是ASCII、GB2312、GBK、GB18030、UTF8、ANSI、Latin1等编码的产生都是对应时期一个产物,他们的产生都是为了解决对应之前编码的一个问题,所以其兼容性如下
类似例子 如记事本里打“联通”为什么会变成乱码?_菠菜cqb的博客-CSDN博客_联通为什么是乱码(https://blog.csdn.net/spinachcqb/article/details/11616451)
==》UTF-8编码是现在标准的解决方案,当遇到乱码或者编码出错的时候,先想想原本数据是用什么编码存储的,然后使用对应的方式解码就好。单纯从二进制数据是无法判断它是用什么编码存储的。
正是由于不完全兼容,所以经常会出现乱码问题,乱码的原因是编码(加密)和解码(解密)用的不是同一个字符集(密码本)。服务器和计算机内存中统一使用的都是Unicode编码,当需要保存到硬盘或者需要传输的时候,就一般转换为UTF-8编码,但是实际文件保存时部分字符不属于UTF-8 部分,所以utf-8 无法找到正确的码值转换关系就乱码或者解码不正确。综上解决乱码问题的方式就是文件打开和保存都明确指定字符编码,不要让计算机去匹配猜测用哪个编码,有可能猜错的!!!

理论摘录:
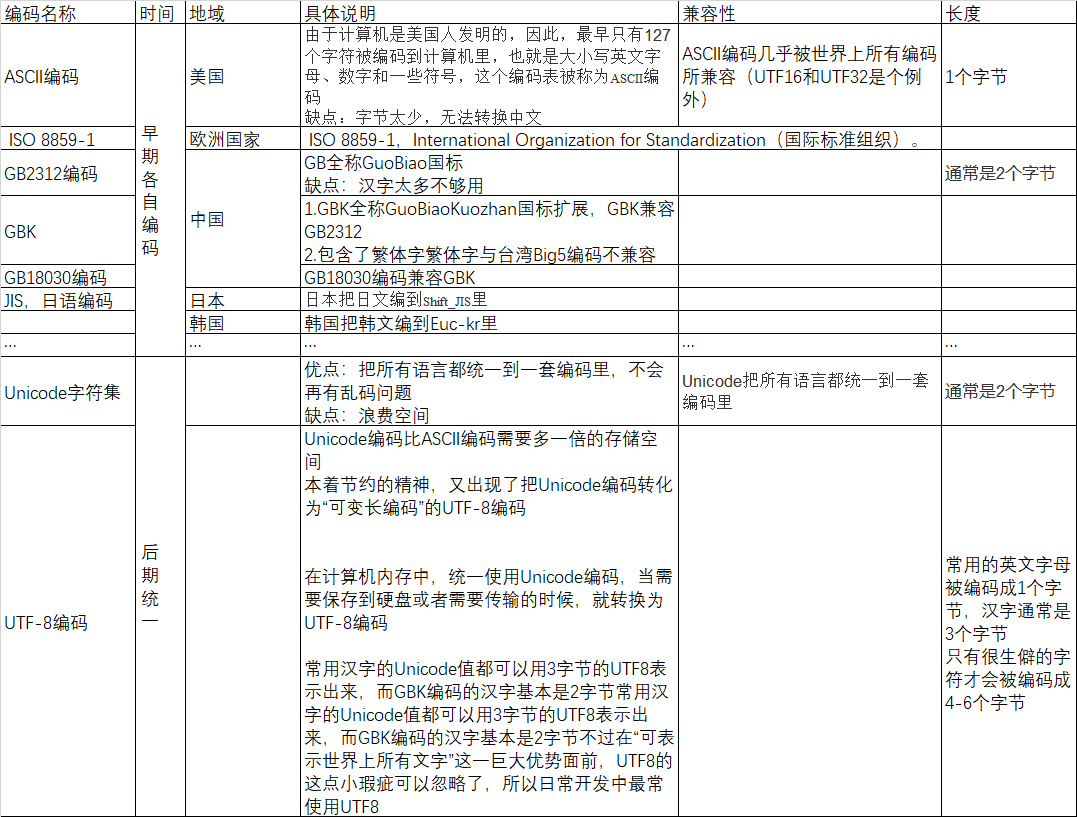
学习摘抄原文链接:
1.https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
2.https://blog.csdn.net/huanglong0438/article/details/117652697
3.https://zhuanlan.zhihu.com/p/107943002
4.https://zhuanlan.zhihu.com/p/46216008

 浙公网安备 33010602011771号
浙公网安备 33010602011771号