Redis SDS
Redis 的SDS 结构
Redis是基于C语言开发的,对于数据结构就存在于C语言的数据类型有类同的地方,对于C语言的字符串而言,存在一些问题,在使用中需要多注意,为了避免这样的事情,Redis 自己定义了SDS 用来作为动态字符串,并作为Redis默认的字符串。
C字符串
C语言使用长度为N+1 的字符数组来表示长度为N的字符串,并且字符数组的最后一个元素总是空字符‘\0',用于表示字符结束。也正是因为这个性质,导致C语言不能存储二进制数据,如图片音频等,而这对于一个数据库而言是不允许的。
部分属性:
-
获取字符串长度:C语言中没存储字符串长度的字段,这样也就意味着每次获取字符串长度的时间复杂度O(n),效率较差
-
默认‘\0’结尾:上边已经说过,C默认遇到‘\0’认为字符串达到末尾,这样对于二进制文件是不安全的。
-
字符串拼接:C语言不记录字符串长度,容易在字符串拼接是产生缓冲区溢出的问题,如A和B的存储空间上相邻,如果A进行字符拼接,如果没有对字符进行扩容就会导致拼接的字符把字符B的信息覆盖。
-
字符串裁剪:对于C字符串不记录长度,那么对于字符裁剪如果不进行字符空间分配,就会导致空间泄漏,裁剪后的空间默认还在使用其他没有
-
对于字符增减:因为不知道长度,所以每次字符拼接都需要进行空间分配,如果不分配就会产生内存泄漏,内存溢出的问题。
SDS
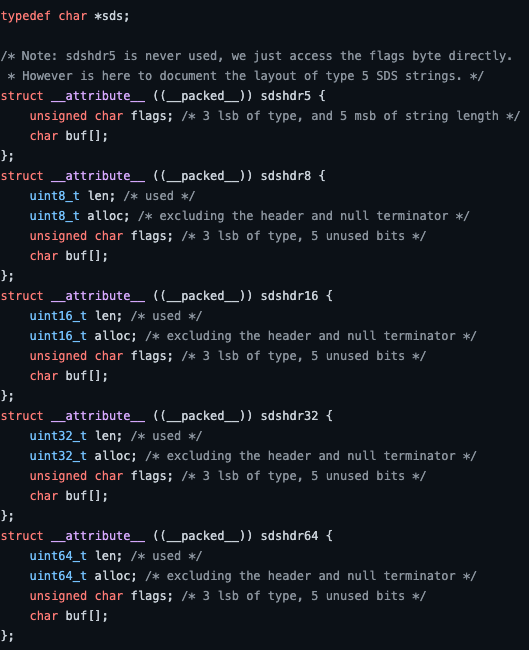
上图是redis源码中对于SDS的数据结构,可以看到分了很对种,sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64其中sdshdr5于其他的结构不同,之所以要定义不同的类型,是为了让不同的字符串使用不同长度的header,从而节省内存。
SDS结构体的的组成有:
-
len: 记录buf数组中已使用的字节数量
-
alloc: 分配的buf数组长度,不包括头和空字符结尾
-
flags: 标志位, 最低3位表示header类型,另外5个位没有使用。类型对应下面5中类型,用3个bit位就可以表示
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
- buf[]: 字符数组,用于存放字符串
基本属性:
-
获取长度:由于有len字段时间复杂度O(1)
-
字符增减:缓冲区溢出,SDS在字符修改时会进行检查,判断时候满足修改条件,不满足自动扩容,
-
二进制安全:因为SDS对字符进行处理,所以在存储二进制数据时也是安全的。
-
兼容C的部分函数;因为SDS的buf 数组默认会添加一个‘\0’ 符合C语言字符串的结构,所以对C语言的函数可以服用。
-
关于效率:如果每次修改都会进行频繁的空间扩容,或者缩减,那么对于非关系数据库是不能接受的,于是redis 产生了两种方式
-
空间预分配:优化SDS的字符串增长,对一个SDS进行扩容时,不仅会添加必须的空间,也会额外分配未使用的空间。
- 分配策略:SDS修改之后长度小于1MB,会添加一个与新增大小长度大小一样的未使用空间;如果修改之后大于1MB 则会分配1MB大小未使用的空间。
-
惰性空间释放:优化缩小SDS操作,如果SDS进行缩小,不会立即重新分配多出来的字节,而是使用free字段记录,等待下次使用。 同时提供有API进行真正的清除,防止造成空间浪费。
-
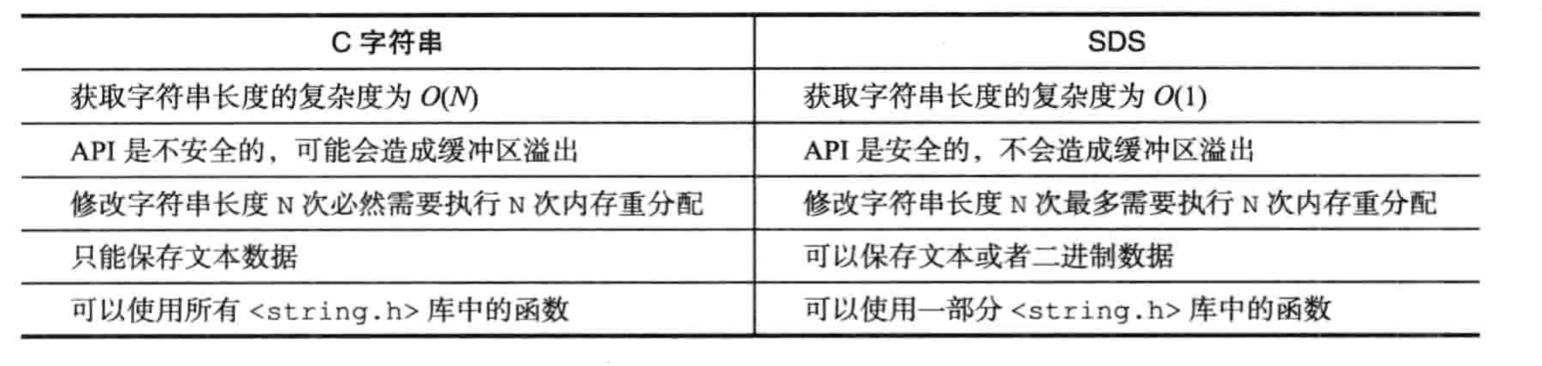
贴一个的总结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号