SQL HierarchyID 数据类型
http://www.cftea.com/c/2009/04/GVQCPXGMHTEC3XEM.asp
我将在本文里向你介绍 SQLServer2008 的一个新特点:HierarchyID 数据类型。我们会看到这个新的数据类型提供了处理树形结构的一个崭新的方法。它增加了 T-SQL 的功能并提升了性能。
本文通过与基于 CTE 的典型方法相比较,深入的介绍了该新的数据类型并给出了一些例子。
对于信息系统而言,管理具有层次结构的数据是常见的问题。它是如此的经典以至于我们可以找到很多案例,例如,著名的 Employee 表。其他例子如管理目录树或文件系统的建模。
Employee 层次问题比较简单,我们必须存储雇员列表以及他们的上级领导。我们用下面的模式来表示:
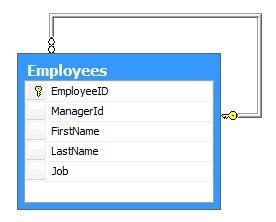
图 1、经典的 Employee 表
即使这个设计是简单的,但查询它可不是件容易的事情。有一些查询示例:
- 找出某个雇员的所有下属
- 算出雇员在公司里的级别
- 等等.
SQL Server 2000 用户使用基于游标或临时表的方法来写这些查询。虽然简单,却牺牲了易维护性和性能。
SQL Server 2005 提出了一个巧妙的方法:在 T-SQL 里使用 CTE。CTE 允许你写递归查询。下面是针对 Employee 表计算级别的一个 CTE 的例子:
AS
(
SELECT emp.EmployeeId, emp.LoginId, emp.LoginId, 1 AS HierarchyOrder
FROM HumanResources.Employee AS emp
WHERE emp.ManagerId isNull
UNION ALL
SELECT emp.EmployeeId, emp.LoginId, Parent.LastName, HierarchyOrder + 1
FROM HumanResources.Employee AS emp
INNER JOIN UpperHierarchy AS Parent
ON emp.ManagerId = parent.EmployeeId
)
SELECT *
From UpperHierarchy
你可以针对 AdventureWorks 数据库来运行该查询。
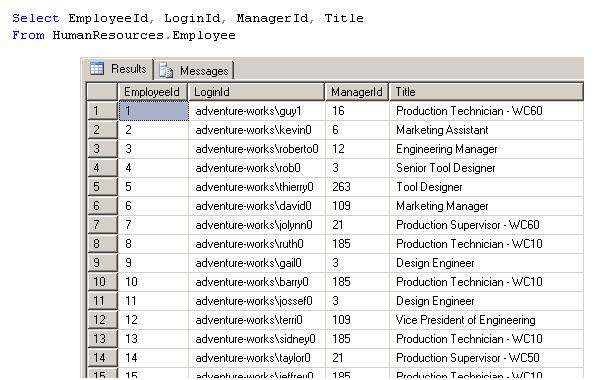
图 2、AdventureWorks 的 Employee 表
CTE 对于用表来呈现树形结构有了很大的改进,但也留下了一些问题。顺便说一下,查询复杂度降低了,但是性能呢?即使优化了 CTE 的执行计划,你也可能处于可能没有索引的境地。
为了提供一个对层次结构真正的支持,SQL Server 2008 引入了一个新的数据类型:HierarchyID。它是一个可管理的类型(.NET),通过 SQL Server 的 SQL CLR 来处理。
图 3、系统数据类型
它没有存父元素的标识符,但一系列的信息可用来定位层次结构里的元素。该类型表示了树结构里的一个节点。
如果你查看 HierachyId 类型列的值,你会看到都是二进制的值。
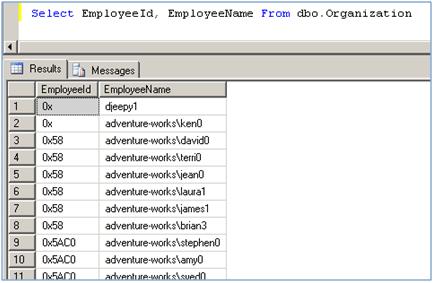
图 4、HierachyId 列的值
我们可以用一个字符串的格式表示 HierachyId 类型。该格式清楚地显示了该类型所包含的信息。字符串用下面的格式来表示:
它显示了下面图形所表示的树形结构。记住节点的第一个子元素不总是 1,也可能是 /1.2/。
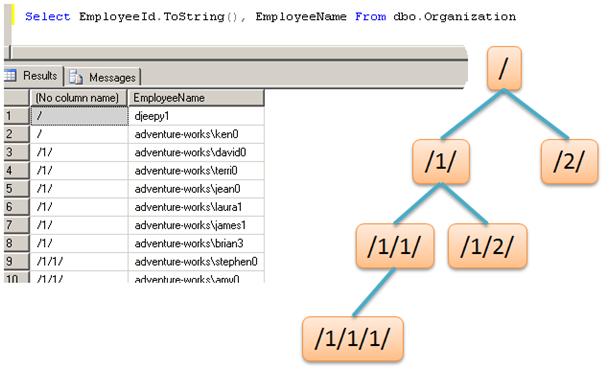
图 5、用字符串表示层次结构
你可能注意到了用来显示字符串格式的查询直接在列上使用到了函数 ToString()。HierarchyId 可以通过一系列到函数来维护,稍后会讲到。
HierarchyId 可以象其他任何类型一样用于创建表的 DDL 语句。在下面的例子里,我们将创建一个表 Organization。在这里,它仅包含了数据类型为 HierarchyId 的一列以及雇员相应的姓名。
(
EmployeeID hierarchyid NOT NULL,
EmployeeName nvarchar(50)NOT NULL
)
我们使用 AdventureWorks 数据库的表 Employee 的数据来填充表 Organization。我们将使用上面描述的 CTE 来实现填充。为了确定根节点的值,我们要使用 HierarchyId 类型的 GetRoot() 函数(注意 GetRoot 像 HierarchyId 其他的函数一样,是区分大小写的):
为了确定子节点的值,我们使用父节点的 GetDescendant 函数:
这个函数的参数可以在其他节点(同一级别)间的某个位置放置子节点。
下面是给出的修改过的 CTE 脚本。它复制 Employee 表的层次结构到使用新类型的新表 Organization 里:
AS
(
SELECT EmployeeId, LoginId,hierarchyid::GetRoot()
FROM HumanResources.Employee
WHERE ManagerId is Null
UNION ALL
SELECT Sub.EmployeeId, Sub.LoginId, Parent.Node.GetDescendant(null, null)
FROM HumanResources.Employee AS Sub
INNER JOIN UpperHierarchy AS Parent
ON Sub.ManagerId = Parent.EmpId
)
Insert Into dbo.Organization(EmployeeId, EmployeeName)
Select Node, LastName
From UpperHierarchy
<>
由于它的二进制格式,HierarchyId 类型是可变长的,这使它很简洁地表示了它所包含的信息。举个例子,对于有 100000 人的一个层次结构,它的大小是 40bit,这仅仅是 int 的 25% 多一点。当然,根据层次结构填充的方式(节点的平均子节点数量,即密度),使用的可见或多或少是重要的。
该类型支持比较。理解树形结构遍历以便知道怎样进行元素比较的方式是重要的。如下图所描述的,比较最初发生在树的深度上(深度优先),然后是同一级别的节点之间。
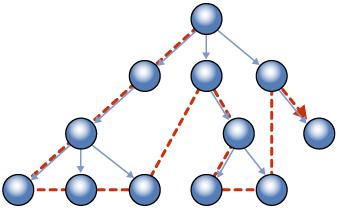
图 6、深度优先(SQLServer2008CPT2BOL)
我们会看到可以索引表来允许宽度优先的遍历树。
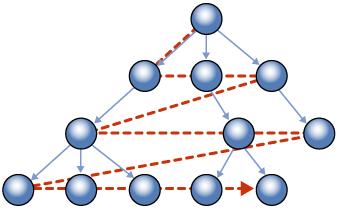
图 7、宽度优先(SQLServer2008CPT2BOL)
为了创建这类型的索引,我们需要知道表里每条记录的级别。我们可以直接从 HierarchyID 列上使用 GetLevel() 函数来得到这个信息。所以我们在表上添加一个计算列来提供雇员的级别。
Add HierarchyLevel As EmployeeID.GetLevel()
一旦创建了新列,我们可以索引它,并用宽度优先的方式来遍历树。
ON Organization(HierarchyLevel,EmployeeID);
HierarchyId 类型天生就不支持唯一性。例如,同一个表里可能有两个根节点。显然,在你的程序里可能会陷入完整性的问题,但是,它也不可能唯一索引树而使整个树变得能聚集。
为了解决这个局限,我们可以在 HierarchyId 列上添加主键(或唯一索引):
PK_Organization PRIMARY KEY
(
EmployeeID
)
HierarchyId 上的主键或唯一索引允许表的深度优先索引。
对于前面的数据填充,该 DDL 将报错。事实上,每个节点的子节点都有相同的索引,这不允许唯一。为了纠正这个问题,我们需要在每一级别上排序子节点来重新组织树。为了实现它,有必要给 GetDescendant() 函数传递参数。该操作将在稍后进行说明。
与上面描述的传统建模方式相反,外键引用父记录天生也不支持。事实上,HierarchyId 类型存储树里节点的路径,而不是父节点。
不过,使用 GetAncestor() 函数来轻易获取父节点的标识符倒是可行的,如下面的语句:
From dbo.Organization
GetAncestor() 返回 HierarchyId。如果 HierarchyId 列是表的主键(如我们的例子),添加一个外键引用到自身就是可行的了。
Add ParentId AS EmployeeId.GetAncestor(1)PERSISTED
REFERENCES dbo.Organization(EmployeeId)
现在,我们的表有了和最初模型相同的完整性规则了。
<>
HierarchyID 数据类型通过一系列的函数来操作:
- GetAncestor
- GetDescendant
- GetLevel
- GetRoot
- ToString
- IsDescendant
- Parse
- Read
- Reparent
- Write
在前面的例子里我们看到了前 5 个函数,接下来的 5 个在下表作出了解释:
| 函数 | 描述 |
| IsDescendant | 允许知道一条记录是不是层次结构里另一个的子节点。 |
| Parse | 它和 ToString() 正好相反,它使从字符串里得到 HierarchyID 值成为可能。 |
| Read | 类似 Parse,但针对 varbinary 值。 |
| Write | 类似 ToString,但针对 varbinary 值。 |
| Reparent | 允许通过更改父节点来移动层次结构里的节点。 |
警告:所有的函数都是区分大小写的。
由于 HierarchyID 类型比简单指向父记录复杂,所以当插入新元素时要确定它的值也更复杂。GetDescendant() 函数给我们了一个可用的节点值。然而,在我们的例子里,HierarchyID 列有唯一约束,它使我们在做的时候使用 GetDescendant 变得不可行。顺便说一下,我们必需提供另外的信息:子节点列表里节点的索引。
要完成它,我们传递同一级别的节点作为 GetDescendant 函数的参数。当然,我们可以传递 NULL 值来把节点放在最初或最后的位置。
在下面的例子里,我们插入一个节点,使它成为一个节点的最后子节点。之前,需要一些步骤来获取同一级别的节点:
SELECT @sibling = Max(EmployeeID)
FROM dbo.Organization
WHERE EmployeeId.GetAncestor(1)= @Parent;
--inserting node
INSERT dbo.Organization(EmployeeId, EmployeeName)
VALUES(@Parent.GetDescendant(@sibling,NULL), @Name)
我们不总是要(或可能)获取同一级别的节点来执行插入。也许有一些隐含的策略来确定节点的位置。
例如,假定我们有一个 order 列,它决定了同一级别节点间节点的位置。我们可以把节点路径计算后表示成一个字符串:
在本例中,由于节点 @Parent 是根节点,结果会是 /<order>/。根据 Parse() 函数,我们可以利用这个值取创建新的节点。
VALUES(HierarchyId::Parse(@NewPath),'aChild')
你可能注意到了 SQL Server 2008 里仅在一行里声明变量并赋值的新语法。
CTE 现在是无法使用的里。要返回层次结构里的一个完整分支,查询很简单:
From dbo.Organization
Where @BossNode.IsDescendant(EmployeeId)
警告:一个节点包含在它自身的后代里,所以 @BossNode 是它自己的后代。
要找出所有的上级,正好要颠倒上面的查询:
From dbo.Organization
Where EmployeeId.IsDescendant(@BossNode)
不再需要一列去存储计算后的级别:
From dbo.Organization
Where EmployeeId.GetLevel() = 3
我们来比较新类型和 CTE 的性能。为了比较,我们来举个例子,它的需求是重新获取经理 'adventure-works \ james1' 的所有分支。表就用本文提到的表:Employee(传统模型)和 Organization(HierarchyID)。
CTE 脚本:
AS
(
SELECT emp.EmployeeId, emp.LoginId, emp.LoginId, 1 AS HierarchyOrder
FROM HumanResources.Employee AS emp
WHERE emp.LoginId ='adventure-works\james1'
UNION ALL
SELECT emp.EmployeeId, emp.LoginId, Parent.LastName, HierarchyOrder + 1
FROM HumanResources.Employee AS emp
INNER JOIN UpperHierarchy AS Parent
ON emp.ManagerId = parent.EmployeeId
)
SELECT EmployeeId, LastName
From UpperHierarchy
使用 HierarchyID 的脚本如下所示。你会注意到有二步:第一步是获取父节点,第二步是找出分支:
Select @BossNode = EmployeeID From dbo.Organization Where EmployeeName = 'adventure-works\james1'
Select *
From dbo.Organization
Where @BossNode.IsDescendant(EmployeeId)= 1
从 SSMS 里可以看到,执行计划给了我们一些性能方面的信息。
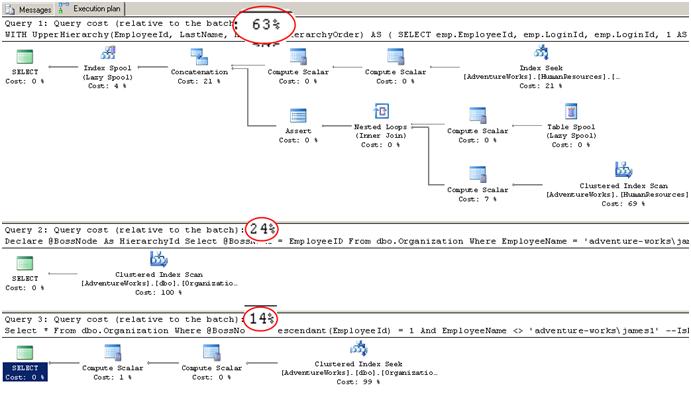
图 8、性能基准
我们可以看到 CTE 占了批处理的 63%。这意味着 HierarchyID 要好 50%。
我们可以看到返回父节点(james1)这一步占了查询的大部分(使用了扫描),因为列没有索引。但是,由于方法2里采占用了相同的比率,我们可以忽略这一点。
我们也可以看到 CTE 的执行计划比 HierarchyID 类型要复杂得多。这是因为主键允许表的唯一扫描。
如果我们来看这些需求使用的系统资源,那么对于 CTE 而言,结论是灾难性的。事件探查器跟踪显示了多个执行:
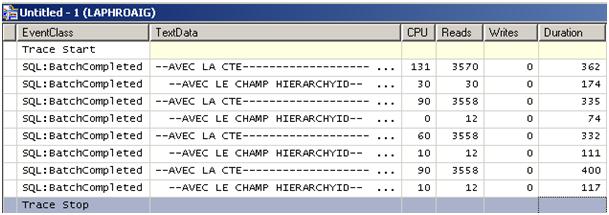
图 9、系统资源使用情况
我们可以看到 duration 列里 1/3-2/3 的比例。然而 IO 使用情况却上升到了 300。CTE 过多使用临时表(Table Spool),这意味着很多的读操作。CPU 使用也多用了 9 倍。
HierarchyID 取得了压倒性的胜利。
从性能来看,当你在关系型数据库里要建模树形结构时,可以毫不犹豫的使用 HierarchyID 类型。该新类型实现了它的目的。它实现了复杂需求(IsDescendant, GetDescendant 等等)所要求的信息并代替了技巧方面的使用(GetLevel, GetAncestor 等等)。
然而,要是没有特殊的需求,我建议你考虑明智地(比如它满足你的需求的话)使用这个新的类型。事实上,HierarchyID 类型也有一些缺点。
首先,该类型要求更多的技巧,所以更难使用和维护。在现实中要使用它也很犯难,因为 HierarchyID 也可能是低效率的,例如,插入变得更复杂且需要更多的CPU。
所以,对于 IT 的每个技术,在选择 HierachyID 之前,你应该正确地评估你的需求。有一些线索可以帮助你去选择。下面的情形可用传统的设计:
如果键很大且你需要优化存储,即时 HierachyID 很小,也会快速超过 4 个字节。
如果你要直接查询唯一元素,主键或唯一索引应该更好。
如果你经常移动中间节点,用 HierachyID 进行层次结构的更新会越来越慢。
我们对 SQL Server 的新类型做了全面概述,不过也少了一些主题,如 HierarchyID 在管理过程或函数上的使用。我们也可以在应用程序里使用 Framework3.5 的 ADO.NET 来处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号