关于scrapy框架 python爬虫进阶篇
scrapy的好处在于能自动配置多线程请求来加快爬虫运行的速度,同时作为框架我们只需要配置较少的部分。
参考自 : https://blog.csdn.net/zjiang1994/article/details/52779537
一、关于scrapy的安装
首先去这个网站下载所需要的插件 https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
找到Twisted an event-driven networking engine目录下适合自己的版本 cp后表示python版本
之后,再执行命令 pip install scrapy 即可安装
如果出现什么问题可以参考 https://blog.csdn.net/wanzhuanit/article/details/79913431 看是否有对应解决
二、关于scrapy框架的基础构造
以下图片转自b站
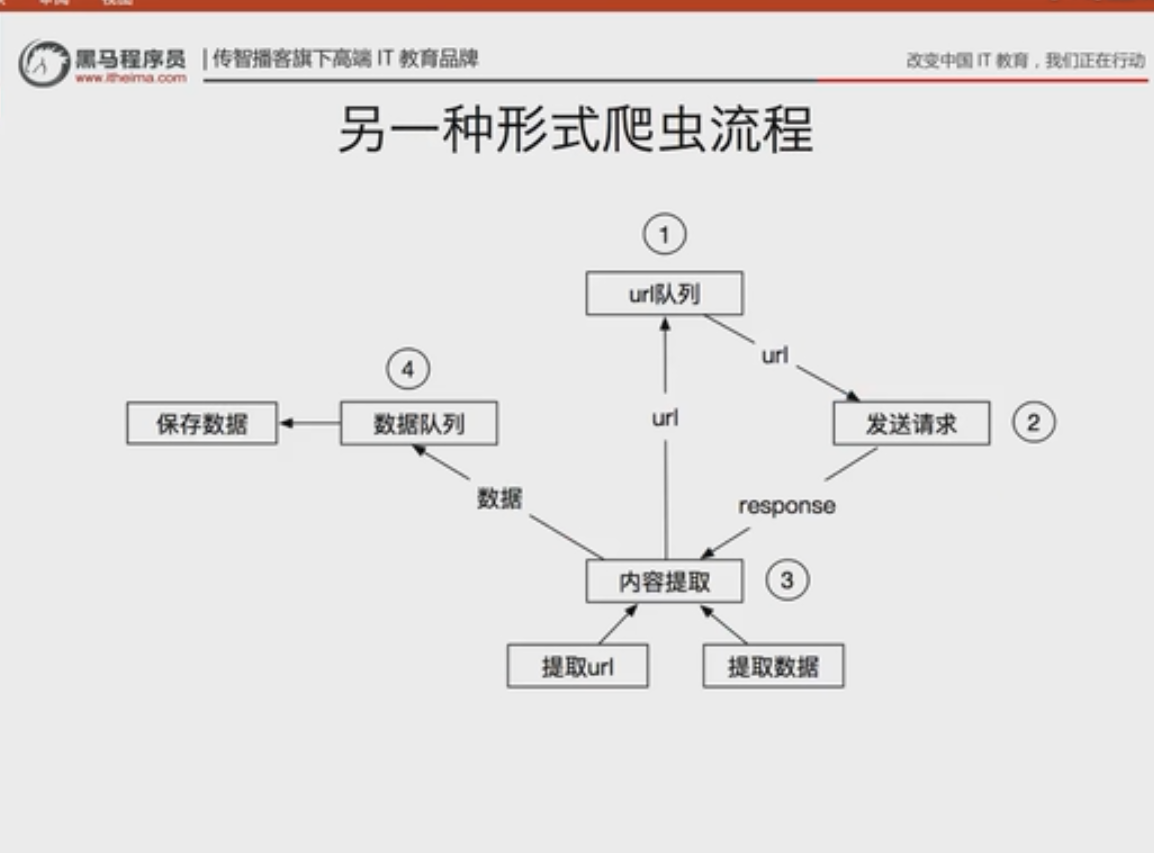
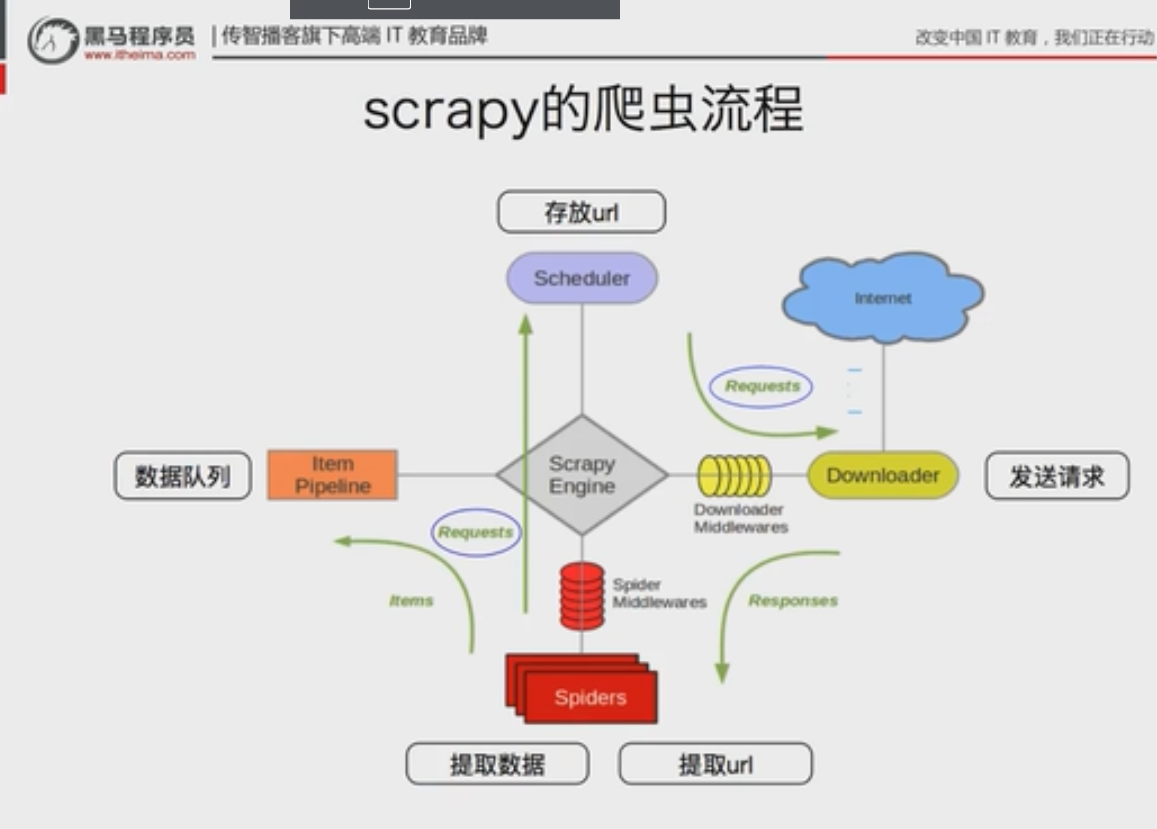

也可以观看 : https://blog.csdn.net/weixin_39553904/article/details/110959729 这篇文章也包含了其他坑
三、创建项目
首先,调用命令提示符,转到对应的文件目录下面,运行命令scrapy startproject +文件名 即可创建
注意:这里的文件名不能是scarpy或者test这种,不然会报错 可以是scarpydemo
建好后,我们发现有以下几个文件:
| 文件 | 说明 |
|---|---|
| items.py | 把爬取到的数据放进变量(定义采集的数据字段、结构化数据) |
| pipelines.py | 把变量中的数据储蓄当文件中(数据持久化) |
| settings.py | 配置文件(启用或者设置优先级) |
| spiders | 编写爬虫规则 |
| middleware.py | 中间件,如为请求添加cookie、ua等 |
其次,我们需要生成一个爬虫 在cmd中转到项目文件夹下运行 scrapy genspider+爬虫名+爬取的网站域名 我们就会发现在目录文件下面多了一个我们创建的爬虫程序。
也可以通过直接在文件夹下面新建一个py文件然后对于spider进行继承:
import scrapy
class ItcastSpider(scrapy.Spider):
#用于区别Spider的爬虫名字
name = "itcast"
#允许访问的域
allowed_domains = []
#爬取的地址
start_urls = []
#爬取方法
def parse(self, response):
pass
最后,当我们完成爬虫的代码时,再回到cmd中,运行 scrapy crawl+爬虫名字 即可运行,也可以在cfg同一层目录下创建main.py,通过导入包(from scrapy.cmdline import execute)来实现命令运行execute("scrapy crawl bilibili".split())
但是在运行的时候信息日志也会被显示出来,如果只想显示结果,我们可以在settings.py中经行相关信息的配置输入LOG_LEVEL = "WARNING" 此时,被warning等级要小的日志就不会被显示出来了(详细的关于logging请看后文)
四、运用scrapy完成一个爬虫
最基本的爬虫配置只要牵扯到爬虫规则、储蓄爬取到数据的列表变量规则、将变量转为文件的形式储存
这三个要配置的依次对应了spiders、items、pipelines
关于spider
首先,我们制定爬虫规则:
import scrapy
class ItcastSpider(scrapy.Spider): #继承自scrapy.spider
name = 'itcast' #爬虫名字
allowed_domains = ['itcast.cn'] #限制爬取的域名
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee'] #起始的网站信息
def parse(self, response):
item = []
#这部分是爬取部分,处理从start_url处获得的request请求
ret1=response.xpath("//div[@class='tea_box4 box_teacher ']//h2//text()")#通过xpath方法进行提取
#.extract()表示提取除路径外的文字,这列可以试着打印ret1和ret2观察她们的区别
ret2 = response.xpath("//div[@class='tea_box4 box_teacher ']//h2//text()").extract()
li_list = response.xpath("//div[@class='tea_box4 box_teacher ']//li")
for li in li_list:
item["name"] = li.xpath(".//div[@class='main_bot']//h2/text()").extract_first()
item["title"] = li.xpath(".//div[@class='main_bot']//h2//span/text()").extract_first()
item["image_path"] ="http://www.itcast.cn"+str(li.xpath(".//div[@class='main_pic']//img/@src").extract_first())
yield item
代码中涉及到的xpath方法仅仅为一种在网页中搜索定位相应元素的方法,如果有爬虫基础的同学应该很好理解。
主要运用:筛选属性包含某字符串的标签(如id = 'bigbaong' 查询包含'big'字符的就可以筛选到)
res = response.xpath("//a[contains(@id,'big')]") 而像<span>这样的分级直接写span就好。
而在定位到标签后,再加@属性名就可以取出其属性中的值。
注意:for循环中的每个xpath前都要加. 如果不加的话会出现直接将最终的数列显示出来的结果(可以尝试以下加深理解)
而且有些网页的结构体中检查与抓包得到的网页源码是会有小部分出入的,这个时候使用xpath就可能会出错,所以要抓包对比过源码后才能放心使用xpath(因为浏览器会给不规范的html代码加上一些)更多关于xpath请看下面链接:
xpath基础: https://blog.csdn.net/qq_27283619/article/details/88704479
xpath易错点:https://blog.csdn.net/pzqingchong/article/details/51487750
关于item
而这段代码中涉及到的数组item我们可以通过scrapy框架定义她的数组规则——在item.py中新建类来制定数组item的规则:
class itcast_item(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
image_path = scrapy.Field()
#-------------------以下为item常用语句-------------------#
course = CourseItem() #定义一个item
course['title'] = "语文" #赋值
#取值
course['title']
course.get('title')
#获取全部键
course.keys()
#获取全部值
course.items()
此时我们制定的规则就包括需要的name、title和image_path三个类别了,再将这层规则引入到爬虫文件当中,完整代码如下:
import scrapy
from scrapydemo.items import itcast_item #引入在item中的配置(爬虫项目名+item+所制定的变量规则类名)
class ItcastSpider(scrapy.Spider):
name = 'itcast' #爬虫名字
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
def parse(self, response):
item = itcast_item()#实例一个容器保存爬取的信息
ret1=response.xpath("//div[@class='tea_box4 box_teacher ']//h2//text()")
ret2 = response.xpath("//div[@class='tea_box4 box_teacher ']//h2//text()").extract()
li_list = response.xpath("//div[@class='tea_box4 box_teacher ']//li")
for li in li_list:
item["name"] = li.xpath(".//div[@class='main_bot']//h2/text()").extract_first()
item["title"] = li.xpath(".//div[@class='main_bot']//h2//span/text()").extract_first()
item["image_path"] ="http://www.itcast.cn"+str(li.xpath(".//div[@class='main_pic']//img/@src").extract_first())
yield item #返回信息
而将信息完整的储蓄到变量文件中后,我们就可以考虑将变量中的数据保存到电脑文件中了,此处我们转向pipeline.py
关于pipeline.py
Pipeline经常进行一下一些操作:清理HTML数据、、验证爬取的数据(检查item包含某些字段)、查重(并丢弃)、将爬取结果保存到数据库中以及一些初始值的设置,本篇仅演示将爬取到的数据保存到本地以及数据的二次处理。
from scrapy.exceptions import DropItem
import scrapy
import json #是用json的格式存储的文件(一般的字段储蓄只要导入这个包即可)
from scrapy.pipelines.images import ImagesPipeline
class MyPipeline(object):#MyPipeline是这个保存规则的名字
def __init__(self):
#打开文件
self.file = open('date.json','w',encoding='utf-8')#创建名为date,json的文件
def process_item(self,item,spider):
#读取item中的数据
line = json.dumps(dict(item),ensure_ascii=False) +"\n"
#逐行写入文件
self.file.write(line)
#返回item
return item
#在spider被开启的时候调用(仅执行一次),我们可以在这个函数中设置初始值或者实例化数据库
def open_spider(self,spider):
spider.hello = "world" # 在其他程序中引用的时候只要slef.hello就可以了
#该方法在spider被关闭的时候调用
def close_spider(self,spider):
pass
class ImgPipeline(ImagesPipeline):#用于保存图片的规则
#通过抓取的图片url获取一个Request用于下载
def get_media_requests(self, item, info):
#返回Request根据图片url下载
yield scrapy.Request(item['image_path'])
#当下载请求完成后执行该方法
def item_completed(self, results, item, info):
#获取下载地址
image_path = [x['path'] for ok, x in results if ok]#可用来返回是否成功的布尔值
if not image_path:#如果失败了
raise DropItem("Item contains no images")#抛出错误信息
#将地址存入item
item['image_path'] = image_path
return item
详细的关于是否保存成功的代码解释可以参考: https://blog.csdn.net/pineapple_C/article/details/108435328
关于setting
我们已经制定了名为MyPipeline的下载规则,但是想让她投入使用,我们还要在settings中为她进行注册,同时进行优先级的排序(从最优先的1依次往后),此外,还需要规定图片的下载地址。
ITEM_PIPELINES = {
'scrapydemo.pipelines.MyPipeline': 1,
'scrapydemo.pipelines.ImgPipeline':100,#先获取信息,后进行图片下载
}
IMAGES_STORE = 'D:\\img\\' #下载地址
CONCURRENT_ITEMS = 100 #限制同时下载的数量防止溢出(并发请求)
ROBOTSTXT_OBEY = True#robot协议,默认开启,会导致某些协议内禁止爬取的数据无法被爬虫检测到
LOG_LEVEL = "WARNING"
##——————————以下作为介绍————————##
DOWNLOAD_DELAY = 3 #每次请求前停三秒
CONCURRENT_REQUESTS_PER_DOMAIN = 16 #每个域名的最大并发请求数
CONCURRENT_REQUESTS_PER_IP = 16 #每个ip的最大并发请求数
COOKIES_ENABLED = False#cookies携带功能被关闭,在统一域名下访问下一个网站不会携带上一个网站的cookies
#默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
#而后的spider middlewares以及downloader middlewares模块都是中间件,可以设置相关优先级
#extensions模块是插件 AutoThrottle模块是自动限速(防止网站被我们爬崩)
#最后是HTTP caching HTTP缓存
想要了解更多throttle可转:https://blog.csdn.net/fredricen/article/details/105074608 概括:throttle确保一段时间内只执行一次debounce (防抖)连续操作后再执行
如果要在其他文件中引用setting中的数据,只需要spider.settings.get("User_Agent",None)就可以引用User_Agent的数据了
而如果要对数据进行二次处理,可以按照如下代码:
import re
class Ygpipeline(object):
def process_item(self,item,spider):
item["content"] = self.process_content(item["content"])
return item
def process_content(self,content):
content = [re.sub(r"\xa0\s","",i) for i in content] #对不需要的数据进行替换删除
content = [i for i in content if len(i)>0]#如果是字符串长度为零就把他删掉
return content
如此,一个运用scrapy框架基本的爬虫就完成了,如需要,可以在setting中设置useragent、代理等数据。
五、关于logging模块的使用
当我们面对单个爬虫较多、文件复杂的程序的时候,我们可以巧妙的运用logging来实现将日志保存到本地并且在日志中新增我们想增加的内容。
对于scrapy文件来说,我们可以直接在setting中设置LOG_FILE="./a.log" 即可将日志保存至当前目录下的a文件中,而终端不再显示日志信息。我们可以通过在某个文件开头import logging ,再在正文中使用logging.warning(item)来实现在日志用输出item的目的,之所以选用warning方法是因为我们已经在设置中设置了低于warning等级的不记入日志当中。
而要知道当前数据出自哪个.py文件的运行结果,只需要在开头增加logger = logging.getLogger(__name__)而后在正文中用logger.warning(item)即可显示数据来源。
而对于一般的文件,比如说log_a.py 我们要使用logging只需要import logging 在正文中用logging.basicConfig()进行日志输出样式的规定(只要在百度搜索该方法,就会有很多已经写好的日志规则)就可以在后文中应用logging的方法了
(logger = logging.getLogger(__name__)同样适用)如果我们需要在另外一个文件中比如log_b.py使用logging方法只需要from log_a.py import logger就可以正常使用了。

转自b站教程
六、url跟进(翻页)
把由当前页面进行操作得到新的url防到url的队列中,具体操作只需要在scrapy.py中加入下列代码:
#url跟进开始
#获取下一页的url信息
url = response.xpath("//a[contains(text(),'下一页')]/@href").extract()
if url :#如果下一页存在(根据实际网页判断)
page = 'http://www.imooc.com' + url[0]
#将url变成request请求返回给函数parse
yield scrapy.Request(page, callback=self.parse)
#url跟进结束
注意:如果上面的程序有在进行一个for循环,下面有一个yield的传回request请求,那么二者可能会同时进行导致传入的item数据和我们预想的顺序不太一样。
scrapy.Request还有其他方法设置:
scrapy.Request(url,callback,method='GET',hesders,body,cookies,meta,dont_filter=Flase)
meta:实现在不同的解析函数中传数据时,meta会默认携带部分信息(下载延迟,请求深度等) 比如上述url跟进代码中将request请求传给了parse函数,如果我们增加meta={"url":page}#默认为字典形式则我们就可以在parse函数中通过response.meta["url"]来在parse函数中引用数据page
dont_filter:让scrapy的url去重功能不会过滤当前url,对于需要重复请求的url有重要用途
注意:因为这里给出了单独存放cookies的地方,所以把cookies放到header中会无效
关于有些网站跟进显示的url不会发生变化
阿贾克斯请求 指是由javascript生成的进一步url,我们可以通过抓包来看到她整个实现的过程,其难点在于如何判断是否有下一页,这点我们也可以通过抓包来解决(总页面以及当前页面信息)
七、关于scrapy shell
只要在命令界面输入scrapy shell +网页url就可以进入调式面板,你可以输入相关命令,结果会直接显示出来。
八、scrapy进阶
携带cookies登录
import scrapy
import re
class doubanSpider(scrapy.Spider):
name = 'csdn'
allowed_domains = ['douban.com']
start_urls = ['https://www.douban.com/people/232123671/']#个人主页,需要登录才能进入所以需要start_request
def start_requests(self):
cookies = """
浏览器中获取的cookies值
"""
print(cookies)
cookies = {i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")} # 把字符串变为字典
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies=cookies
)
def parse(self, response):
print(response.body)
print(re.findall("豆瓣id", response.body.decode()))#检查是否登录成功
注意:response.body是byte类型的http正文响应 response.text是文本形式的http正文响应
response.text = response.body.decode(response.encoding)
如果想要查看最后cookies的传输过程可以在setting中COOKIES_DEBUG=True
scrapy发送post请求模拟登录
使用scrapy.Request对网页发送的是get 请求,而post请求我们需要用scrapy.FormRequset方法来发送,同时运用formdata(默认接受字典类型的数据)来写道需要的post数据。
首先,我们需要通过抓包来确定正常登录的时候我们需要通过表单提交哪些数据,除了账号密码验证码外会有一些隐藏在原本网页中的数据来防爬,我们可以通过网页搜索来获取到相关的值,最后做成一个字典,这边假设表单中需要login、password、commit三个数据:
post_data = dict(
login="账号",
password = "密码",
commit = commit,#原本网页中隐藏值(commit的值在前已经通过xpath找到并赋值)
)
yield scrapy.FormRequest(
"登录页面的url",
formdata = post_data,
callback = self.after_login#转到after_login的函数中
)
##我们可以在after_login函数中执行
#print(response.url," : ",response.status)
#print(re.findall(r'user_name',response.body.decode()))
##来检验是否登录成功response.body为bytes类型,而我们需要的是str类型,故要加上.decode()
从响应中找到from表单进行登录
除了规规矩矩用模拟post请求外,我们还可以在获取到的网页响应中获取到填写账号密码的表单,这样的话就不用管在登录界面的隐藏值,直接将账号密码填入表单中进行登录即可。
yield scrapy.FormRequest.form_response(#该方法可以在响应中找出form表单
response,
formdata = {"login":"账号","password":"密码"},
callback = self.after_login
)
关于middlewares.py
与pipline一样,编写一个类,然后再setting中开启他,其默认有两种方法:process_request和process_response
process_request(self,request,spider):当每个request通过下载中间件时该方法被调用
process_response(self,request,response,spider):当下载器完成http请求的时候,传递响应给引擎的时候调用
如此,我们就可以在setting中定义useragent列表,然后在process_request中选择一个useragent进行request访问 记得导入random模块,random.choice()方法可以在列表中随机选择一条,具体代码为:
class RandomUserAgent(object):
def process_request(self,request,spider):
useragent = random.choice(USER_AGENTS)
request.headers["User_Agent"] = useragent #添加自定义的UA给request的headers赋值即可
class ProxyMiddleware(object):
def process_request(self,request,spider):
request.meta["proxy"] = "http://124.115.126.76.808"
#添加代理只需要在request的meta信息中增加proxy字段,代理的形式为:协议+ip地址+端口
class CheckUserAgent:#检测选到的ua是否可用
def process_response(slef,request,response,spider):
print(dir(response.request))
print(request.headers["User-Agent"])
return response #对于response方法我们需要有一个return 的request或者response,而上述的request方法则不用
关于scrapy多线程引发的问题
当item中所要储蓄的数据很杂很乱的时候,十分容易出现多个程序的for循环并行操作,导致最后信息出现重复对不上号的结果,所以,我们需要通过深拷贝来解决这一个问题。(python中普通的拷贝为浅拷贝,指拷贝地址而非值,深拷贝是指另外创一个item项目并把原来地址中的值复制到现在item的地址中)如下图:
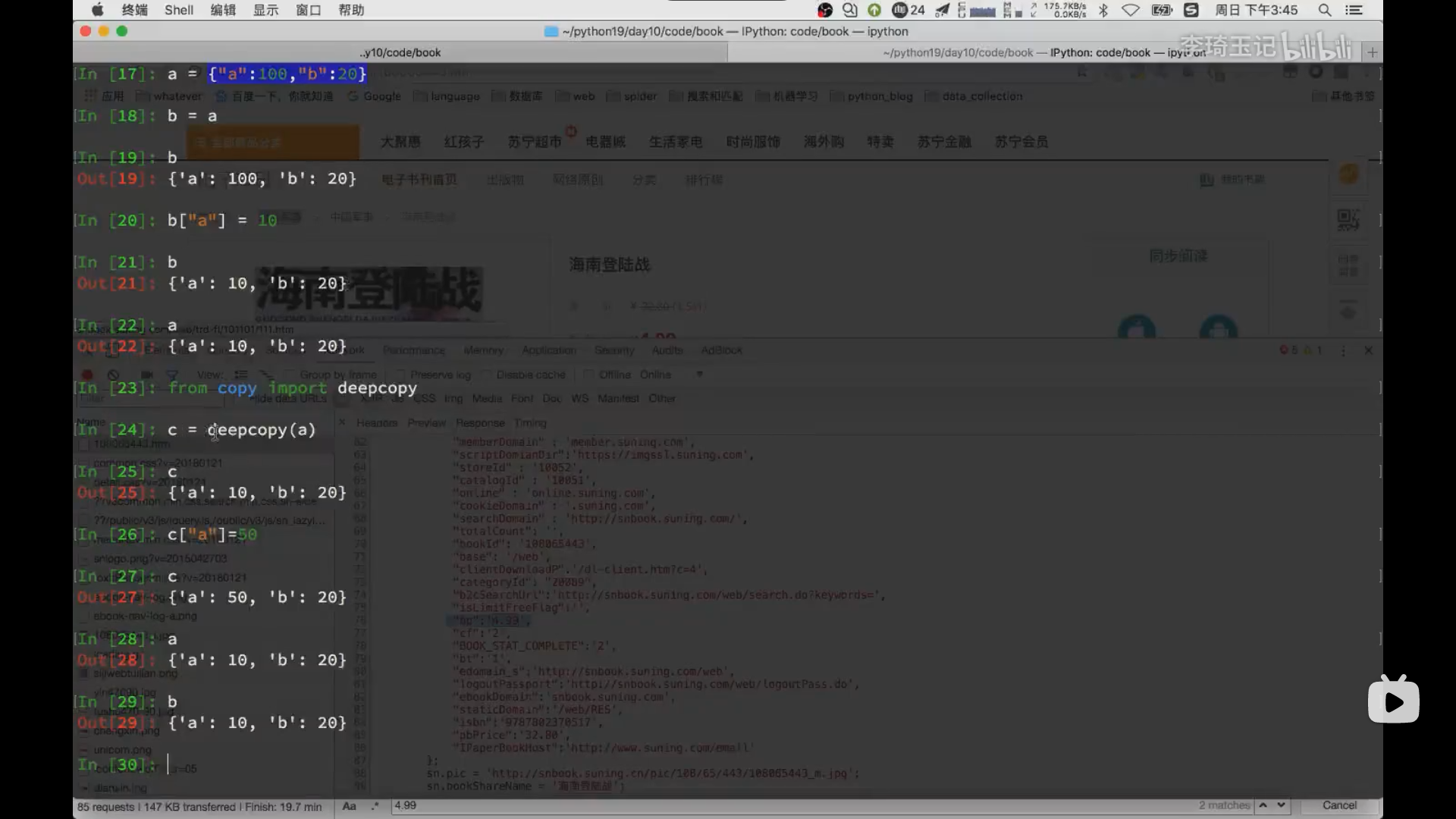
引用深拷贝我们需要导入深拷贝的函数from copy import deepcopy 然后,只需要在yield中meta={"item":deepcopy(item)}即可解决由多线程引发的该类问题
crawlspider爬虫
crawlspider类爬虫简化了url跟进中的代码量。 具体创建只需要scrapy genspider -t crawl 爬虫名 "域名限制"
创建完成后我们会发现其相较一般的scrapy差在多了rules,少了prase
我们只需要在rules内完成下一页网址的搜索即可(url地址不完整程序会自动补充),但是我们不能在这个程序中定义parse函数(因为有特殊的功能需要实现)
别忘记运用了正则表达式要import re
rules = (
#在当前页面中查找每个分类的链接,在点进去的网页进行数据查找(提取出来的url的response会交给callback处理)
Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.html'),callback='parse_item'),#d+表示多个数字
#寻找下一页的链接(follow提取到当前规则的url后,针对这个url的页面再进入一次rules)
Rule(LinkExtractor(allow=r'/web/site0/tab5240/module14430/page\d+\.htm'),follow=True),
)
def parse_item(self,response):
pass


 浙公网安备 33010602011771号
浙公网安备 33010602011771号