多线程与多进程 python爬虫进阶篇
借鉴:https://blog.csdn.net/qq_40244755/article/details/90043484
观前提示:因为python自身编辑器的原因,python多线程有时候甚至会降低效率,所以我们一般使用多进程而不是多线程,即用multiprocessing替代Thread multiprocessing库来弥补thread库因为GIL而低效的缺陷。本篇学习主要是为了探究线程进程的运行知识。
名词介绍
(不影响之后阅读,可跳过)
涉及名词参考:https://www.cnblogs.com/yuanchenqi/articles/6755717.html
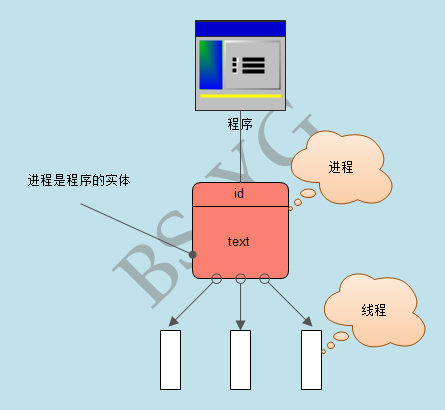
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
线程则是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
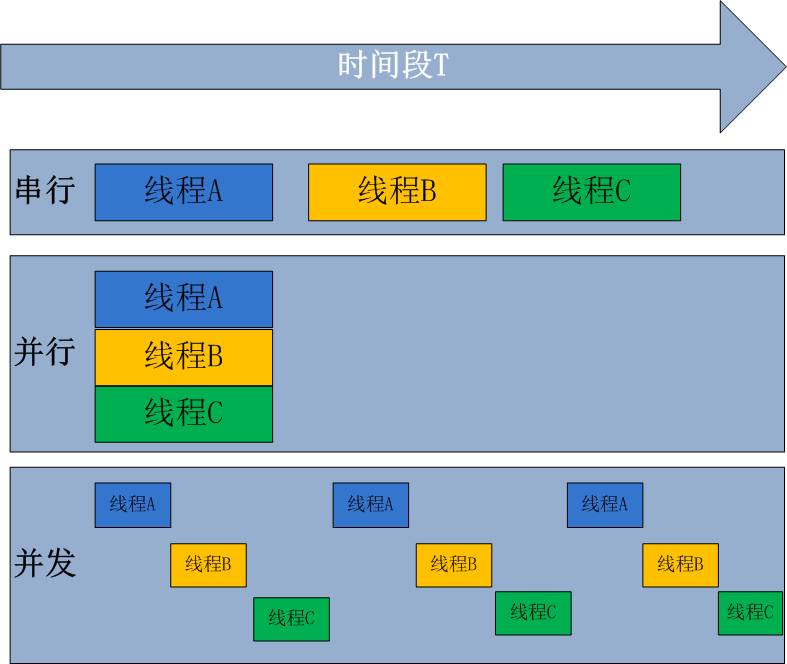
串行、并发与并行:
同步与异步
同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态,当有消息返回时系统会通知进程进行处理。
多线程
要完成一个多线程代码,我们将分以下步骤去进行:
①创建一个可供多个线程共享的数据队列
②准备好产生数据的函数(producer生产者)以及传入数据后对数据经行操作的函数(consumer消费者)
③创建线程,将生产者与消费者对应上
④运行产生数据的线程,将要传入的数据准备好
⑤通过for循环使消费函数多线程同时运行
⑥等待所有线程运行完毕
(以上为大体框架,下面为详细的实现介绍)
首先,我们要引入threading库去创造线程对象
t= Thread(target=countdown, args=(10,)) #创建线程对象
cutdown为我们要执行线程的函数名
args为我们要放入我们执行线程函数的传入变量,一般为组元类型
我们可以通过查看布尔值:t.is_alive()来判断该线程是否在运行
如果一个线程需要在后台运行,我们可以将他创立成后台线程:
t = Thread(target=countdown, args=(10,), daemon=True)
接下来,我们看一下一个完整线程的运行:
class CountDownTask:
def __init__(self):
self._running = True
def terminate(self):
self._running = False
def run(self, n):
while self._running and n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
if __name__ == '__main__':
c = CountDownTask()
t = Thread(target=c.run, args=(10,))
t.start() #运行这个线程
c.terminate() #结束这个线程
t.join() #表示等待该线程结束后再执行之后的代码
而将多个线程连在一起,为了保持各个线程之间的通讯,我们引入Queue库来创建一个能被多个线程共享的Queue队列,并运用put() 和 get() 方法来向队列中添加或者删除元素 。
put() 将数据存入队列 get()从队列中取出数据并将该数据从队列中删除
from queue import Queue
from threading import Thread
def producer(out_q):
while True:
out_q.put(1)
def consumer(in_q):
while True:
data = in_q.get()
if __name__ == '__main__':
q = Queue()
t1 = Thread(target=consumer, args=(q, ))
t2 = Thread(target=producer, args=(q, ))
t1.start()
t2.start()
此处的producer(生产者:产生数据)和consumer(消费者:引入数据进行相关操作)是两个不同的线程但是但是此处共享队列q 这样当生产者生产了数据后,消费者会拿到,然后消费它。(同步与异步)
同理,我们看下列一个简单的多线程爬虫程序
def run(in_q, out_q):
headers = {.....}
while in_q.empty() is not True:#确认队列中还有数据没有被执行
'''
爬虫的爬取部分代码略
注意:
传入的url通过url=in_q.get()来获取
最后的数据通过put方法放入out_q中(相当于list的append)
'''
in_q.task_done()#通知队列已完成任务
if __name__ == '__main__':
queue = Queue()#创建任务队列
result_queue = Queue()#创建结果队列
for i in range(1, 1001): #往队列中添加任务
queue.put('http://www.g.com?page='+str(i))
print('queue 开始大小 %d' % queue.qsize())
for index in range(10):#使用十个线程来执行
thread = Thread(target=run, args=(queue, result_queue, ))
thread.daemon = True # 随主线程退出而退出
thread.start()
queue.join() # 队列消费完 线程结束
print('queue 结束大小 %d' % queue.qsize())
print('result_queue 结束大小 %d' % result_queue.qsize())
注意:因为queue的get()方法会删除队列中的数据,所以如果我们要看队列中的内容注意做好备份
while not queue.empty():
item = queue.get()
datem.append(item)
print(item)
执行完这段程序后,原来的queue队列中的数据就已经完全被删完了
多线程以生产者和消费者格式写的完整代码如下:
from queue import Queue
import threading
from threading import Thread
import requests
from bs4 import BeautifulSoup
import re
import my_fake_useragent as ua
findname = re.compile(r'<span class="title">(.*?)</span>')
findscore = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>',re.S)
def producer(in_q): # 生产者
ready_list = []
while in_q.full() is False:
for i in range(0, 10): # 往队列中添加任务
url = 'https://movie.douban.com/top250?start=' + str(i * 25)
if url not in ready_list:
ready_list.append(url)
in_q.put(url)
else:
continue
def consumer(in_q, out_q): # 消费者
header = {
'User-Agent': ua.UserAgent().random()
}
while in_q.empty() is not True: # 确认队列中还有数据没有被执行
page = requests.get(url=in_q.get(), headers=header)
html = page.text
bs = BeautifulSoup(html, "html.parser")
for item in bs.find_all('div', class_="item"):
item = str(item)
name = re.findall(findname, item)[0]
score = re.findall(findscore, item)[0]
out_q.put(str(threading.current_thread().getName()) + '::' + str(name) + '=' + str(score))
in_q.task_done()
if __name__ == '__main__':
queue = Queue(maxsize=10) # 创建任务队列
result_queue = Queue() # 创建结果队列
print('queue 开始大小 %d' % queue.qsize())
producer_thread = Thread(target=producer, args=(queue,))
producer_thread.daemon = True
producer_thread.start()
for index in range(10):
consumer_thread = Thread(target=consumer, args=(queue, result_queue,))
consumer_thread.daemon = True
consumer_thread.start()
queue.join() # 队列消费完 线程结束
print('queue 结束大小 %d' % queue.qsize())
print('result_queue 结束大小 %d' % result_queue.qsize())
while not result_queue.empty():
item = result_queue.get()
print(item)
其他可用于调试的库方法:
返回当前的线程变量:threading.currentThread()
用于返回线程的名字:threading.current_thread().getName()
返回正在运行的线程数量:threading.activeCount()
关于GIL锁:
获得锁:threadLock.acquire()
成功获得锁定后返回True,否则超时后将返回False。可选的timeout参数不填时将一直阻塞直到获得锁定
释放锁: threadLock.release()
多进程
多进程与多线程基本一致,其思路是创建多个进程并将他们放到进程池中,进程池调用多个核进行同时运算(理论上进程池的最大上限和CPU的核数有关)
我们直接来看代码理解:
import multiprocessing, requests,re, os
from bs4 import BeautifulSoup
import my_fake_useragent as ua
findname = re.compile(r'<span class="title">(.*?)</span>')
findscore = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>', re.S)
def consumer(in_q, out_q): # 消费者
header = {
'User-Agent': ua.UserAgent().random()
}
while in_q.empty() is not True: # 确认队列中还有数据没有被执行
page = requests.get(url=in_q.get(), headers=header)
html = page.text
bs = BeautifulSoup(html, "html.parser")
for item in bs.find_all('div', class_="item"):
item = str(item)
name = re.findall(findname, item)[0]
score = re.findall(findscore, item)[0]
print('%s :: %s = %s'%(os.getpid(),str(name),str(score)))
out_q.put(str(os.getpid()) + '::' + str(name) + '=' + str(score))
in_q.task_done()
if __name__ == '__main__':
queue = multiprocessing.Manager().Queue()#多进程之间的通讯队列,实现进程间的数据共享
#注:multiprocessing.Manager也可以设置共享列表或字典
result_queue = multiprocessing.Manager().Queue()
for i in range(0, 10):#producer
url = 'https://movie.douban.com/top250?start=' + str(i * 25)
queue.put(url)
pool = multiprocessing.Pool(3) # 创建异步进程池(非阻塞)设置最大同时运行线程数为3
#注:这里的异步指的是启动子进程的过程,与父进程本身的执行(爬虫操作)是异步的
for index in range(10):
pool.apply_async(consumer, args=(queue, result_queue,))
# 维持执行的进程总数为3,当一个进程执行完后启动一个新进程.
pool.close()
pool.join()
queue.join() # 队列消费完 线程结束
print('queue 结束大小 %d' % queue.qsize())
print('result_queue 结束大小 %d' % result_queue.qsize())
更多关于多进程
参考:https://www.liaoxuefeng.com/wiki/1016959663602400/1017628290184064
进程池批量创建子进程后运行的逻辑可以通过下列代码理解:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid)#查看现在父节点
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
运行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.
0、1、2、3同时执行,4滞后执行
如果子进程是外部进程,我们可以通过subprocess模块启动他
import subprocess
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)
如果子程序需要输入,我们可以通过communicate()方法输入
p = subprocess.Popen(['nslookup'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('utf-8'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号