
第一次个人项目作业
第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程-19信安2 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 实现论文查重算法 + PSP表格 + 使用JProfiler性能分析 + GitHub管理 |
1、代码链接
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 450 | 540 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 40 | 40 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 50 | 60 |
| · Coding | · 具体编码 | 360 | 420 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 240 |
| Reporting | 报告 | 50 | 70 |
| · Test Report | · 测试报告 | 20 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 1450 | 1710 |
3、计算模块接口的设计与实现过程
3.1 主要的类
- MainPaperCompare类:main方法
- Hamming类:计算海明距离
- SimHash类:计算 SimHash 值
- Txt类:读写 txt 文件
- ShortStringException类:处理文本内容过短的异常
- HtmlSpirit类:删除文档中的HTML标签
3.2 算法
-
算法简介
-
SimHash也即相似hash,是一类特殊的信息指纹,常用来比较文章的相似度,与传统hash相比,传统hash只负责将原始内容尽量随机的映射为一个特征值,并保证相同的内容一定具有相同的特征值。而且如果两个hash值是相等的,则说明原始数据在一定概率下也是相等的。但通过传统hash来判断文章的内容是否相似是非常困难的,原因在于传统hash只唯一标明了其特殊性,并不能作为相似度比较的依据。
-
SimHash最初是由Google使用,其值不但提供了原始值是否相等这一信息,还能通过该值计算出内容的差异程度。
-
-
算法原理
- 分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
-
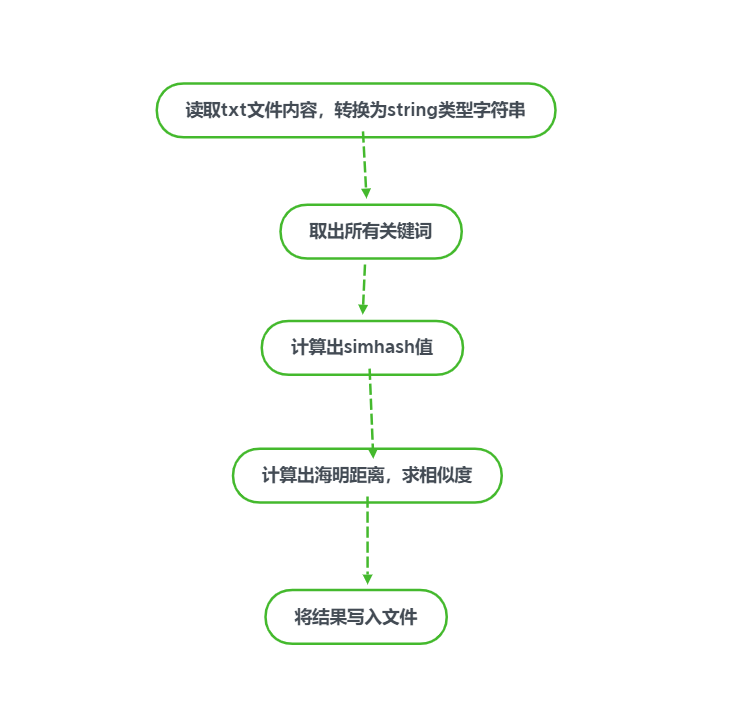
流程图
![]()
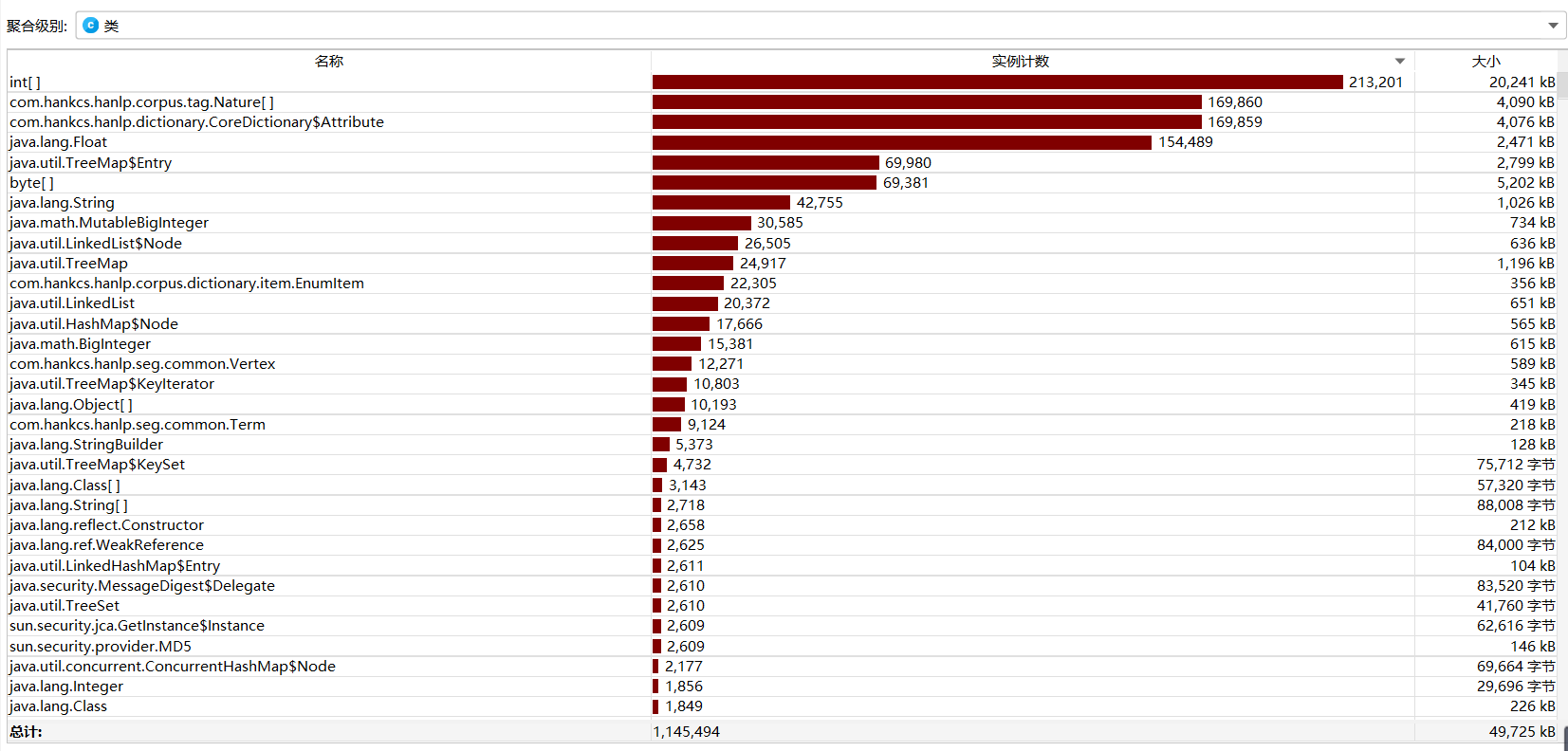
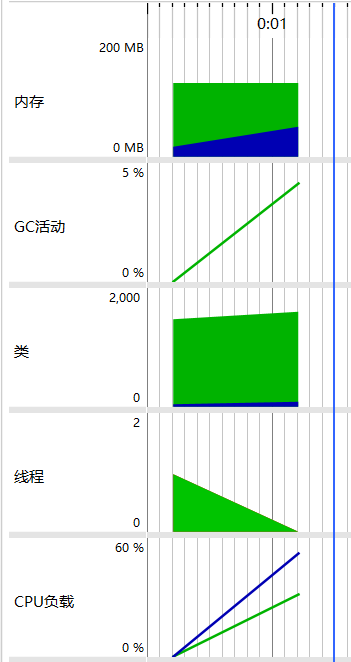
性能测试
- 测试标准文本消耗
![]()
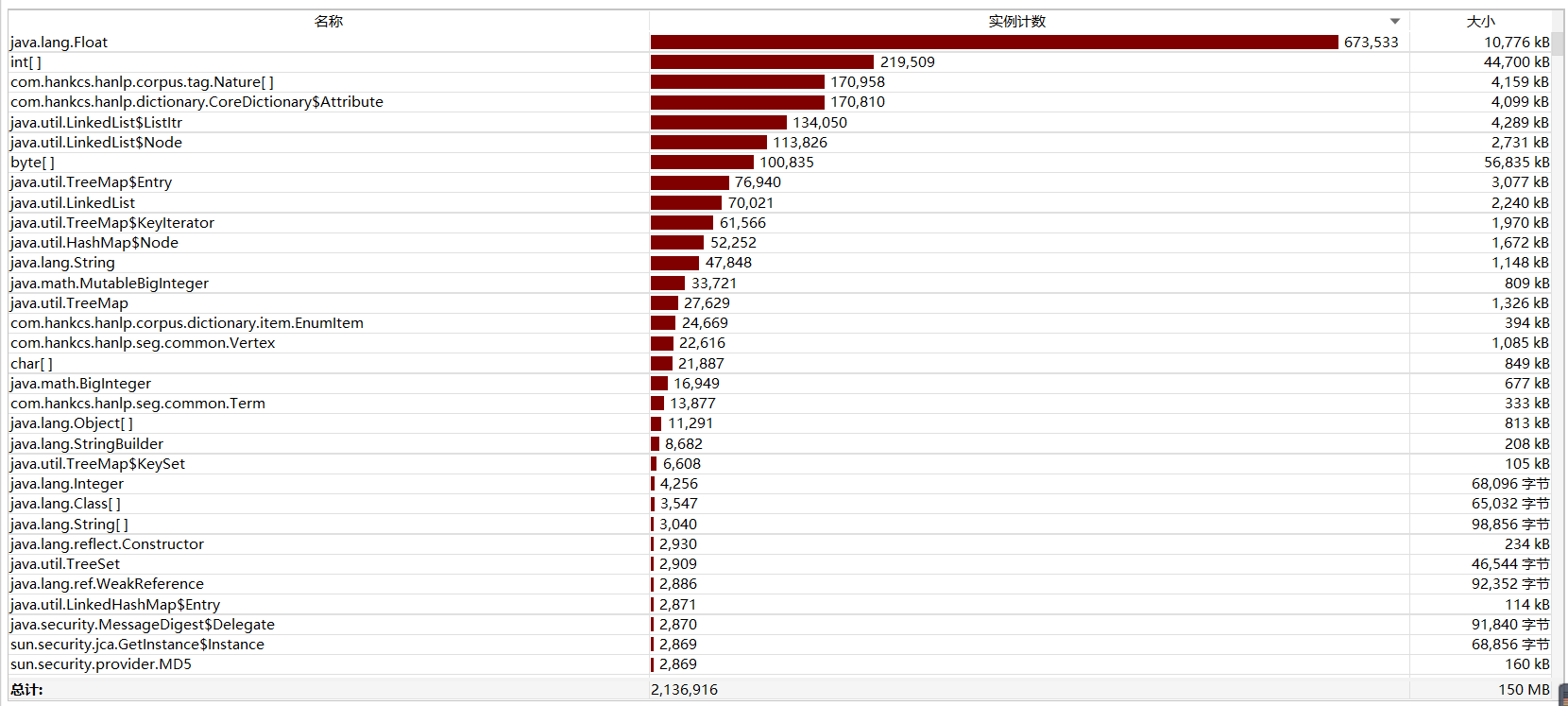
- 测试HTML文本消耗
![]()

单元测试
- 主方法测试
public void testOrigAndAll(){
String[] str = new String[6];
str[0] = Txt.readTxt("D:\\大学\\大三\\大三上\\软件工程\\测试文本\\orig.txt");
str[1] = Txt.readTxt("D:\\大学\\大三\\大三上\\软件工程\\测试文本\\orig_0.8_add.txt");
str[2] = Txt.readTxt("D:\\大学\\大三\\大三上\\软件工程\\测试文本\\orig_0.8_del.txt");
str[3] = Txt.readTxt("D:\\大学\\大三\\大三上\\软件工程\\测试文本\\orig_0.8_dis_1.txt");
str[4] = Txt.readTxt("D:\\大学\\大三\\大三上\\软件工程\\测试文本\\orig_0.8_dis_10.txt");
str[5] = Txt.readTxt("D:\\大学\\大三\\大三上\\软件工程\\测试文本\\orig_0.8_dis_15.txt");
String ansFileName = "D:\\大学\\大三\\大三上\\软件工程\\测试文本\\result.txt";
for(int i = 0; i <= 5; i++){
double ans = Hamming.getSimilarity(SimHash.getSimHash(str[0]), SimHash.getSimHash(str[i]));
Txt.writeTxt(ans, ansFileName);
}
}
异常处理

总结
- 因为以前并没有试过类似的项目开发经验,很多东西都要重头摸索,包括算法的查询、实现、测试等,本次作业让我各方面能力都有了一定的增长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号