YOLOv8改进 | 2023 | LSKAttention大核注意力机制助力极限涨点
一、本文介绍
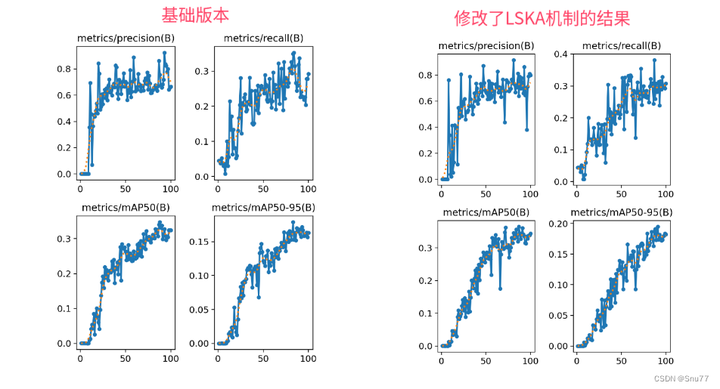
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv8,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv8的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文还将提供代码实现细节和使用方法,展示这种改进对目标检测、语义分割等方面的积极影响。通过实验YOLOv8在整合LSKAttention机制后,实现了检测精度提升(下面会附上改进LSKAttention机制和基础版本的结果对比图)。
二、LSKAttention的机制原理


《Large Separable Kernel Attention》这篇论文提出的LSKAttention的机制原理是针对传统大核注意力(Large Kernel Attention,LKA)模块在视觉注意网络(Visual Attention Networks,VAN)中的应用问题进行的改进。LKA模块在处理大尺寸卷积核时面临着高计算和内存需求的挑战。LSKAttention通过以下几个关键步骤和原理来解决这些问题:
-
核分解:LSKAttention的核心创新是将传统的2D卷积核分解为两个1D卷积核。首先,它将一个大的2D核分解成水平(横向)和垂直(纵向)的两个1D核。这样的分解大幅降低了参数数量和计算复杂度。
-
串联卷积操作:在进行卷积操作时,LSKAttention首先使用一个1D核对输入进行水平方向上的卷积,然后使用另一个1D核进行垂直方向上的卷积。这两步卷积操作串联执行,从而实现了与原始大尺寸2D核相似的效果。
-
计算效率提升:由于分解后的1D卷积核大大减少了参数的数量,LSKAttention在执行时的计算效率得到显著提升。这种方法特别适用于处理大尺寸的卷积核,能够有效降低内存占用和计算成本。
-
保持效果:虽然采用了分解和串联的策略,LSKAttention仍然能够保持类似于原始LKA的性能。这意味着在处理图像的关键特征(如边缘、纹理和形状)时,LSKAttention能够有效地捕捉到重要信息。
-
适用于多种任务:LSKAttention不仅在图像分类任务中表现出色,还能够在目标检测、语义分割等多种计算机视觉任务中有效应用,显示出其广泛的适用性。
总结:LSKAttention通过创新的核分解和串联卷积策略,在降低计算和内存成本的同时,保持了高效的图像处理能力,这在处理大尺寸核和复杂图像数据时特别有价值。
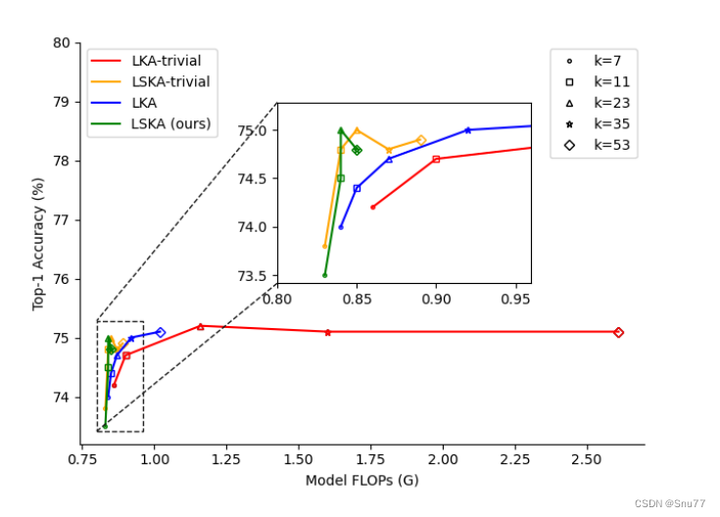
上图展示了在不同大核分解方法和核大小下的速度-精度权衡。在这个比较中,使用了不同的标记来代表不同的核大小,并且以VAN-Tiny作为对比的模型。从图中可以看出,LKA的朴素设计(LKA-trivial)以及在VAN中的实际设计,在核大小增加时会导致更高的GFLOPs(十亿浮点运算次数)。相比之下,论文提出的LSKA(Large Separable Kernel Attention)-trivial和VAN中的LSKA在核大小增加时显著降低了GFLOPs,同时没有降低性能
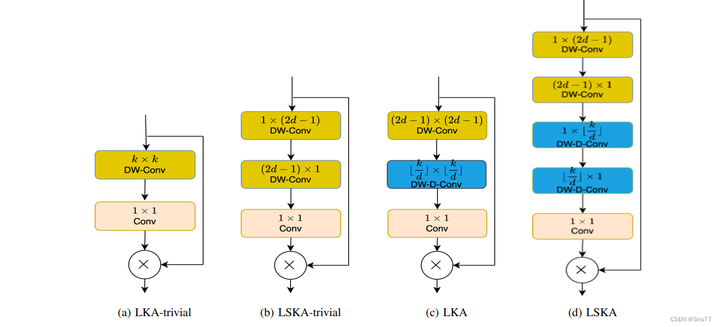
上图展示了大核注意力模块不同设计的比较,具体包括:
-
LKA-trivial:朴素的2D大核深度卷积(DW-Conv)与1×1卷积结合(图a)。
-
LSKA-trivial:串联的水平和垂直1D大核深度卷积与1×1卷积结合(图b)。
-
原始LKA设计:在VAN中包括标准深度卷积(DW-Conv)、扩张深度卷积(DW-D-Conv)和1×1卷积(图c)。
-
提出的LSKA设计:将LKA的前两层分解为四层,每层由两个1D卷积层组成(图d)。其中,N代表Hadamard乘积,k代表最大感受野,d代表扩张率。
个人总结:提出了一种创新的大型可分离核注意力(LSKA)模块,用于改进卷积神经网络(CNN)。这种模块通过将2D卷积核分解为串联的1D核,有效降低了计算复杂度和内存需求。LSKA模块在保持与标准大核注意力(LKA)模块相当的性能的同时,显示出更高的计算效率和更小的内存占用。
具体改进方法可访问如下地址:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号