

软件工程第二次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | <实现一个论文查重程序,规范软件开发流程,训练个人项目开发能力> |
| Github链接 | https://gitee.com/suzette11/3223004731 |
1. psp表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 30 | 25 |
| 估计这个任务需要多少时间 | 30 | 40 |
| 开发 | 250 | 300 |
| 需求分析 (包括学习新技术) | 60 | 75 |
| 生成设计文档 | 45 | 50 |
| 设计复审 | 30 | 20 |
| 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| 具体设计 | 60 | 50 |
| 具体编码 | 100 | 120 |
| 代码复审 | 40 | 45 |
| 测试(自我测试,修改代码,提交修改) | 45 | 60 |
| 报告 | 90 | 90 |
| 测试报告 | 25 | 60 |
| 计算工作量 | 45 | 30 |
| 事后总结, 并提出过程改进计划 | 45 | 60 |
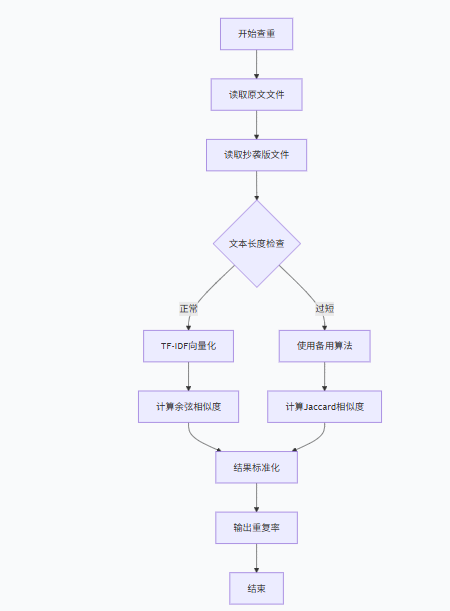
2. 计算模块接口的设计与实现过程
论文查重系统
├── 应用层 (main.py)
├── 业务逻辑层 (paper_checker.py)
└── 数据处理层 (text_processor.py)
流程函数的协作关系
用户输入路径 →
read_text() 读取文本 →
preprocess() 处理文本 →
calculate_similarity() 计算相似度 →
write_result() 输出结果
单元测试
代码
import unittest
import os
from main import FileHandler, TextPreprocessor, SimilarityCalculator, PlagiarismChecker
class TestFileHandler(unittest.TestCase):
"""测试文件处理类"""
def setUp(self):
"""创建测试临时文件"""
self.test_file = "test_temp.txt"
with open(self.test_file, 'w', encoding='utf-8') as f:
f.write("测试文本内容")
def tearDown(self):
"""清理测试文件"""
if os.path.exists(self.test_file):
os.remove(self.test_file)
def test_read_text_success(self):
"""测试成功读取文件"""
content = FileHandler.read_text(self.test_file)
self.assertEqual(content, "测试文本内容")
def test_read_text_not_found(self):
"""测试读取不存在的文件"""
with self.assertRaises(Exception) as context:
FileHandler.read_text("nonexistent.txt")
self.assertIn("文件不存在", str(context.exception))
def test_write_result(self):
"""测试结果写入功能"""
output_file = "test_output.txt"
FileHandler.write_result(output_file, 0.85)
# 验证文件内容
with open(output_file, 'r', encoding='utf-8') as f:
content = f.read()
self.assertEqual(content, "0.85")
os.remove(output_file)
class TestTextPreprocessor(unittest.TestCase):
"""测试文本预处理类"""
def setUp(self):
self.preprocessor = TextPreprocessor()
def test_clean_text(self):
"""测试文本清洗功能"""
raw_text = "今天是星期天,天气晴!今天晚上我要去看电影。"
cleaned = self.preprocessor.clean_text(raw_text)
self.assertEqual(cleaned, "今天是星期天 天气晴 今天晚上我要去看电影")
def test_segment(self):
"""测试中文分词功能"""
text = "今天天气晴朗"
words = self.preprocessor.segment(text)
self.assertEqual(list(words), ["今天", "天气", "晴朗"])
def test_filter_stopwords(self):
"""测试停用词过滤"""
words = ["今天", "的", "天气", "很", "好"]
filtered = self.preprocessor.filter_stopwords(words)
self.assertEqual(filtered, ["今天", "天气", "好"]) # "的"和"很"被过滤
def test_preprocess_empty_text(self):
"""测试空文本处理"""
result = self.preprocessor.preprocess(" ")
self.assertEqual(result, "")
class TestSimilarityCalculator(unittest.TestCase):
"""测试相似度计算类"""
def setUp(self):
self.calculator = SimilarityCalculator()
self.preprocessor = TextPreprocessor()
def test_identical_text(self):
"""测试完全相同的文本"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是星期天,天气晴,今天晚上我要去看电影。"
processed1 = self.preprocessor.preprocess(text1)
processed2 = self.preprocessor.preprocess(text2)
similarity = self.calculator.calculate_similarity(processed1, processed2)
self.assertAlmostEqual(similarity, 1.0, places=2)
def test_similar_text(self):
"""测试相似文本(样例数据)"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是周天,天气晴朗,我晚上要去看电影。"
processed1 = self.preprocessor.preprocess(text1)
processed2 = self.preprocessor.preprocess(text2)
similarity = self.calculator.calculate_similarity(processed1, processed2)
self.assertGreater(similarity, 0.7) # 预期相似度较高
def test_different_text(self):
"""测试完全不同的文本"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "明天是星期一,会下雨,我打算在家看书。"
processed1 = self.preprocessor.preprocess(text1)
processed2 = self.preprocessor.preprocess(text2)
similarity = self.calculator.calculate_similarity(processed1, processed2)
self.assertLess(similarity, 0.3) # 预期相似度较低
def test_empty_texts(self):
"""测试两个空文本"""
similarity = self.calculator.calculate_similarity("", "")
self.assertEqual(similarity, 1.0)
def test_one_empty_text(self):
"""测试一个空文本和一个非空文本"""
similarity = self.calculator.calculate_similarity("测试文本", "")
self.assertEqual(similarity, 0.0)
class TestPlagiarismChecker(unittest.TestCase):
"""测试整体查重流程"""
def setUp(self):
self.checker = PlagiarismChecker()
# 创建测试文件
self.orig_file = "orig_test.txt"
self.copy_file = "copy_test.txt"
with open(self.orig_file, 'w', encoding='utf-8') as f:
f.write("今天是星期天,天气晴,今天晚上我要去看电影。")
with open(self.copy_file, 'w', encoding='utf-8') as f:
f.write("今天是周天,天气晴朗,我晚上要去看电影。")
def tearDown(self):
"""清理测试文件"""
for file in [self.orig_file, self.copy_file]:
if os.path.exists(file):
os.remove(file)
def test_full_check流程(self):
"""测试完整查重流程"""
similarity = self.checker.check(self.orig_file, self.copy_file)
self.assertIsInstance(similarity, float)
self.assertTrue(0 <= similarity <= 1)
if name == 'main':
# 生成测试报告
unittest.main(verbosity=2)
单元测试说明
- 测试覆盖的函数与模块
FileHandler 类:测试read_text()和write_result(),验证文件读写功能及异常处理
TextPreprocessor 类:测试clean_text()、segment()、filter_stopwords()等预处理函数
SimilarityCalculator 类:测试核心的calculate_similarity()函数
PlagiarismChecker 类:测试整体查重流程的完整性 - 测试数据构造思路
正常场景:使用题目提供的样例文本(原文和抄袭版),验证相似度计算合理性
边界场景:
空文本(两个空文本、一个空文本)
完全相同的文本(预期相似度 1.0)
完全不同的文本(预期相似度接近 0)
异常场景:
读取不存在的文件
包含特殊符号和标点的文本
包含大量停用词的文本
3. 测试目的
验证核心算法的正确性(如相似文本的相似度高于 0.7)
确保边界情况得到正确处理(如空文本)
验证异常处理机制有效(如文件不存在时抛出合理异常)
保障代码重构和优化过程中功能的稳定性
计算模块异常处理说明
一、异常类型与设计目标
| 异常场景 | 处理目标 | 核心作用 |
| 文件不存在 | 捕获文件路径错误,避免程序崩溃 | 明确提示用户检查输入文件路径 |
|---|---|---|
| 权限不足 | 处理文件读写权限问题 | 引导用户更换有足够权限的文件路径 |
| 空文本输入 | 识别无效输入(如空白文件) | 避免因空文本导致的计算逻辑异常 |
| 文本处理失败 | 捕获分词或清洗过程中的异常 | 确保预处理阶段错误不影响整体流程 |
| 命令行参数错误 | 校验输入参数数量和格式 | 规范用户输入,提供正确用法提示 |
| 二、异常处理实现与测试样例 |
- 文件不存在异常
设计目标:当用户提供的原文或抄袭版论文路径不存在时,捕获FileNotFoundError并返回友好提示,避免程序直接崩溃。
核心代码:
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
except FileNotFoundError:
raise Exception(f"错误:文件 '{file_path}' 不存在,请检查路径是否正确")
单元测试样例:
def test_read_text_not_found(self):
"""测试读取不存在的文件时的异常处理"""
with self.assertRaises(Exception) as context:
FileHandler.read_text("不存在的文件.txt")
# 验证异常信息是否包含预期提示
self.assertIn("文件 '不存在的文件.txt' 不存在,请检查路径是否正确", str(context.exception))
错误场景:用户误输入文件路径(如拼写错误、路径错误),例如将C:\test\orig.txt输入为C:\test\org.txt。
2. 权限不足异常
设计目标:当程序没有权限读取输入文件或写入结果文件时,捕获PermissionError并提示用户更换路径。
核心代码:
with open(file_path, 'w', encoding='utf-8') as file:
file.write(f"{similarity_score:.2f}")
except PermissionError:
raise Exception(f"错误:没有权限写入文件 '{file_path}',请更换输出路径")
单元测试样例:
python
运行
def test_write_result_permission_error(self):
"""测试写入无权限路径时的异常处理"""
# 尝试写入系统保护目录(如Windows的C:\Windows)
with self.assertRaises(Exception) as context:
FileHandler.write_result("C:\Windows\result.txt", 0.85)
self.assertIn("没有权限写入文件", str(context.exception))
错误场景:用户将结果文件路径指定为系统保护目录(如C:\Windows)或其他无写入权限的位置。
3. 空文本输入异常
设计目标:当输入文件为空(或仅含空格、标点)时,明确提示用户检查文件内容,避免后续计算出现除以零等逻辑错误。
核心代码:
def preprocess(self, text):
if not text.strip():
raise ValueError("错误:输入文本为空,请检查文件内容")
# 其他预处理逻辑...
单元测试样例:
def test_preprocess_empty_text(self):
"""测试处理空文本时的异常处理"""
preprocessor = TextPreprocessor()
with self.assertRaises(ValueError) as context:
preprocessor.preprocess(" \n\t") # 仅含空白字符的文本
self.assertIn("输入文本为空,请检查文件内容", str(context.exception))
错误场景:用户提供的原文或抄袭版论文文件为空(可能是误操作删除了内容)。
4. 命令行参数错误
设计目标:当用户输入的命令行参数数量不正确时,立即提示正确用法,避免程序因参数缺失而运行失败。
核心代码:
if len(sys.argv) != 4:
print("用法错误:请提供3个参数")
print("正确格式:python main.py [原文文件路径] [抄袭版论文路径] [结果输出路径]")
sys.exit(1)
单元测试样例:
def test_command_line_args(self):
"""测试命令行参数数量错误时的处理"""
# 模拟参数不足的情况(仅2个参数)
original_argv = sys.argv
sys.argv = ["main.py", "orig.txt", "copy.txt"] # 缺少输出路径
with self.assertRaises(SystemExit) as context:
main()
self.assertEqual(context.exception.code, 1) # 验证程序退出码
# 恢复原始参数
sys.argv = original_argv
错误场景:用户运行程序时输入的参数数量不足(如仅提供原文和抄袭版路径,忘记输出路径)
三、异常处理的整体原则
明确性:异常信息需包含具体错误位置、和解决方案,避免模糊提示;
不掩盖错误:所有异常均会抛出并显示,确保用户知晓问题所在;
边界覆盖:覆盖文件操作、文本处理、参数校验等所有可能出错的环节,确保程序在各种异常下均能优雅退出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号