看完了List下面应该看一下最经典的也是被问最多的HashMap,相传这是进大厂必问之题目(WTF???)
源码简单分析:
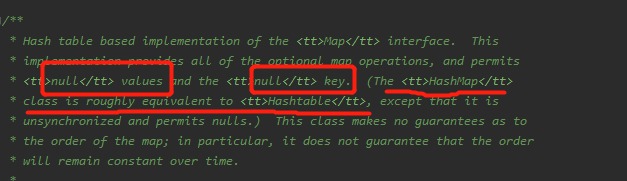
允许value和key为空,和Hashtablt并没有特别大的不同且不保证有序。
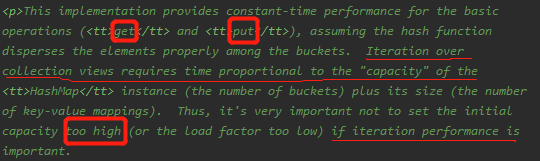
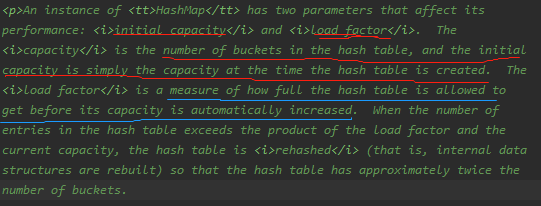
get和put提供了基本的操作,操作时间和量呈正相关。不要将初始容量和装载因子(加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.)设置不合理。
有两个因素会会对性能产生重要的影响,当初始容量*装载因子小于哈希表容量时,会进行散列,桶数会*2
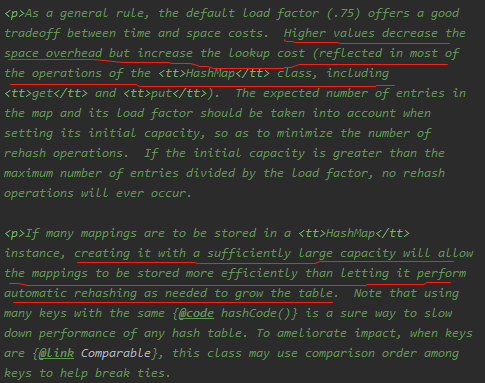
装载因子初始值为0.75,最好是事先考虑到,那么就不需要进行散列。
这边就有个问号了?装载因子,初始容量和哈希表容量之间的关系。
加载因子可以看作是:数量 / 容量
初始容量可以看作是:容器的容量
哈希表容量可以看作是:实际的数量(要放入到容器中的数量)
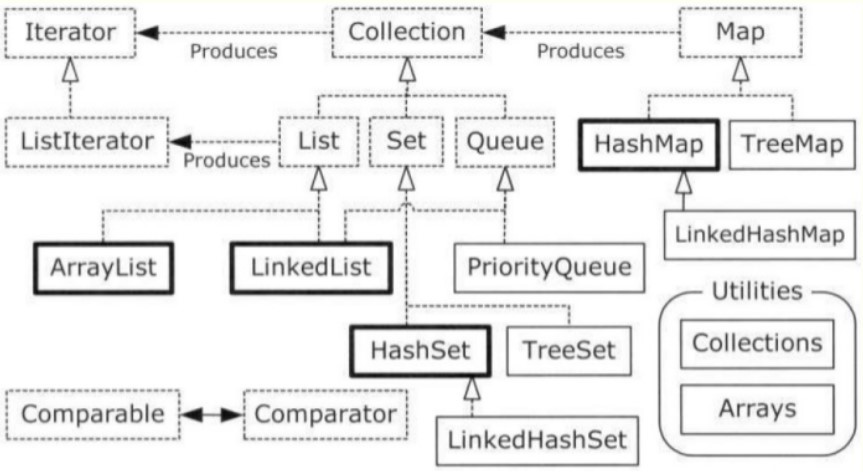
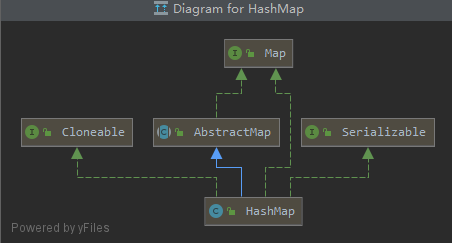
再来看看HashMap的类继承图:
这三个接口太熟悉了,唯一有点陌生的就是Map。
private static final long serialVersionUID = 362498820763181265L;
也很熟悉,反序列化和序列化的标识。
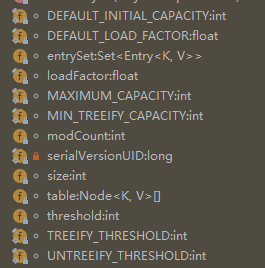
下面看看他的属性:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 初始值大小
static final int MAXIMUM_CAPACITY = 1 << 30;最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;加载因子
static final int TREEIFY_THRESHOLD = 8;当添加时候,元素已经大于8个了则会将链表结构转为树
static final int UNTREEIFY_THRESHOLD = 6;若小于6个则会转为链表
static final int MIN_TREEIFY_CAPACITY = 64;桶可能被转化为链表的最小容量要求
成员变量一共有这些:
HashMap中有一个内部类,我感觉这算是他的精髓之一。
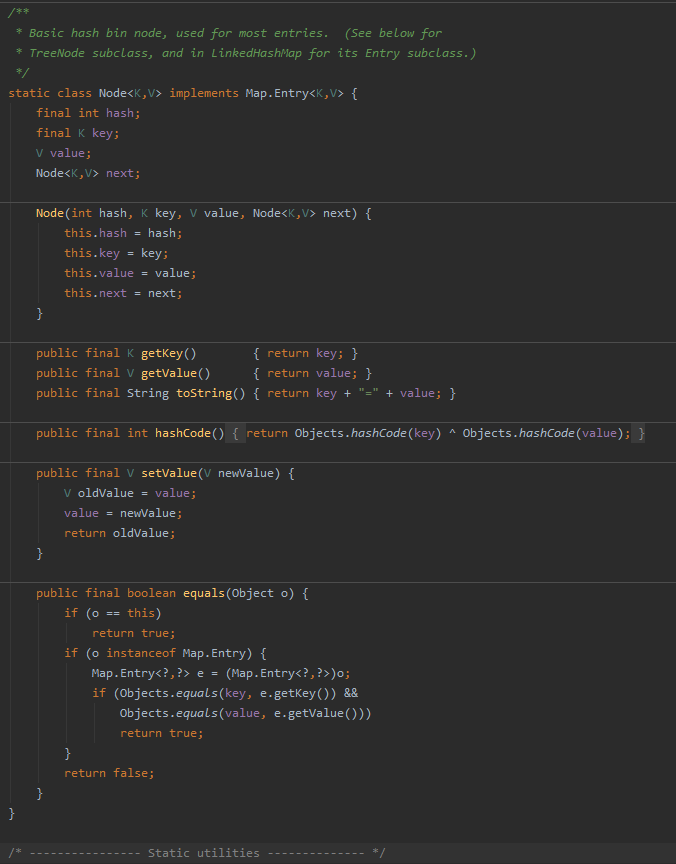
内部类Node<K, V>
首先是这个内部类的声明部分,在声明中内部类Node实现了Map中的内部的接口Entry,因此我们很容易就可以发现,这个内部类是用来实现map内部的entry的,也就是是实际的键值对的储存的数据结构。
在这个内部类中,定义了几个成员变量,分别用来记录当前entry的哈希值、键与值,这里,哈希值与键是final的,即一旦生成了这个entry,则其哈希值与所对应的键是不可以改变的,但是其值是可以改变的,这与我们印象中map的使用方法是相符的。
在这三个用来记录entry中实际数据的成员变量之后,是一个Node类型的成员变量,看到这个属性,熟悉数据结构的同学应该很快就会有所联想,特别是我们这个类的名字叫做Node,所以自然而然地会想到是不是与链表有关,答案是确实是一个链表,在Java中,HashMap中的每个键所对应的所有键值对是以链表的形式储存的,而其中的节点所用的数据结构就是现在所看的这个Node了。
Node的哈希方法,是将键与值的哈希取一次异或,作为自身的哈希值。
最后,是Node类的equals()方法,首先判断参数中的对象o和自身地址是否相同,之后,再判断o是否是Map.Entry接口的实现类,若是的话,判断键与值是否分别相等,若想等,则返回true。
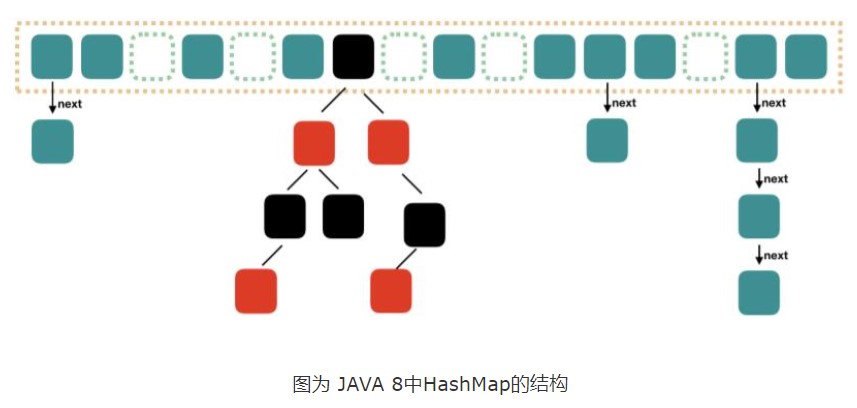
这边要知道HashMap是使用Node来储存键值对。
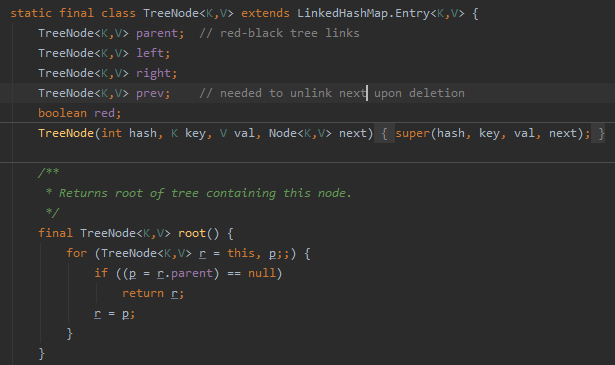
内部类TreeNode
继承LinkedHashMap,其实是一个红黑树,用来解决链表中的查询过慢问题。红黑树目前还没看懂(fk红黑树)
不过目前知道最后其实还是绕回了HashMap中的Node的构造方法。
目前可以看出的特点:
- 无序,允许为null,非同步
- 底层由散列表(哈希表)实现
- 初始容量和装载因子对HashMap影响挺大的,设置小了不好,设置大了也不好
构造方法:
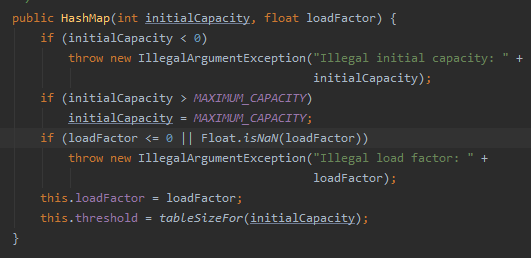
设置初始因子和容量,然后一个tableSizeFor()方法,这个方式是对于给定的目标容量,返回两倍大小的幂。
花里胡哨.........其实是控制散列表再散列。它的值应该是:capacity * load factor才对的。其实这里仅仅是一个初始化,当创建哈希表的时候,它会重新赋值
put方法:
传入key和value,然后把key进行hash转换,最后返回。
这个运算是得到key的hashcode然后做高16位异或运算。
我们是根据key的哈希值来保存在散列表中的,我们表默认的初始容量是16,要放到散列表中,就是0-15的位置上。也就是tab[i = (n - 1) & hash]。可以发现的是:在做&运算的时候,仅仅是后4位有效~那如果我们key的哈希值高位变化很大,低位变化很小。直接拿过去做&运算,这就会导致计算出来的Hash值相同的很多。
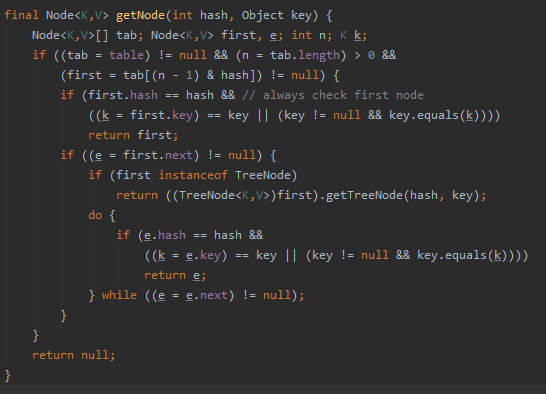
get方法:
其实也是通过节点来进行查询。
getNode具体是通过链表或者树进行查找。
看到这边其实已经知道了,增和删也是一样的思维想法。
HashMap主要其实就是一个Node,散列,红黑树(fk红黑树)三个知识点需要掌握。
总结:
在JDK8中HashMap的底层是:数组+链表(散列表)+红黑树
在散列表中有装载因子这么一个属性,当装载因子*初始容量小于散列表元素时,该散列表会再散列,扩容2倍!
装载因子的默认值是0.75,无论是初始大了还是初始小了对我们HashMap的性能都不好
- 装载因子初始值大了,可以减少散列表再散列(扩容的次数),但同时会导致散列冲突的可能性变大(散列冲突也是耗性能的一个操作,要得操作链表(红黑树)!
- 装载因子初始值小了,可以减小散列冲突的可能性,但同时扩容的次数可能就会变多!
初始容量的默认值是16,它也一样,无论初始大了还是小了,对我们的HashMap都是有影响的:
- 初始容量过大,那么遍历时我们的速度就会受影响~
- 初始容量过小,散列表再散列(扩容的次数)可能就变得多,扩容也是一件非常耗费性能的一件事~
从源码上我们可以发现:HashMap并不是直接拿key的哈希值来用的,它会将key的哈希值的高16位进行异或操作,使得我们将元素放入哈希表的时候增加了一定的随机性。
还要值得注意的是:并不是桶子上有8位元素的时候它就能变成红黑树,它得同时满足我们的散列表容量大于64才行的~
参考:
https://mp.weixin.qq.com/s?__biz=MzI4Njg5MDA5NA==&mid=2247484139&idx=1&sn=bb73ac07081edabeaa199d973c3cc2b0&chksm=ebd743eadca0cafc532f298b6ab98b08205e87e37af6a6a2d33f5f2acaae245057fa01bd93f4&scene=21###wechat_redirect
https://www.cnblogs.com/liulaolaiu/p/11744380.html
https://www.jianshu.com/p/8a01b011e238
面试题:https://www.cnblogs.com/zengcongcong/p/11295349.html





 浙公网安备 33010602011771号
浙公网安备 33010602011771号