
MySQL7 种join表连接结果集
总览图
MySQL表之间的关联查询类似高一数学的集合,交集、并集、叉集==如下图所示
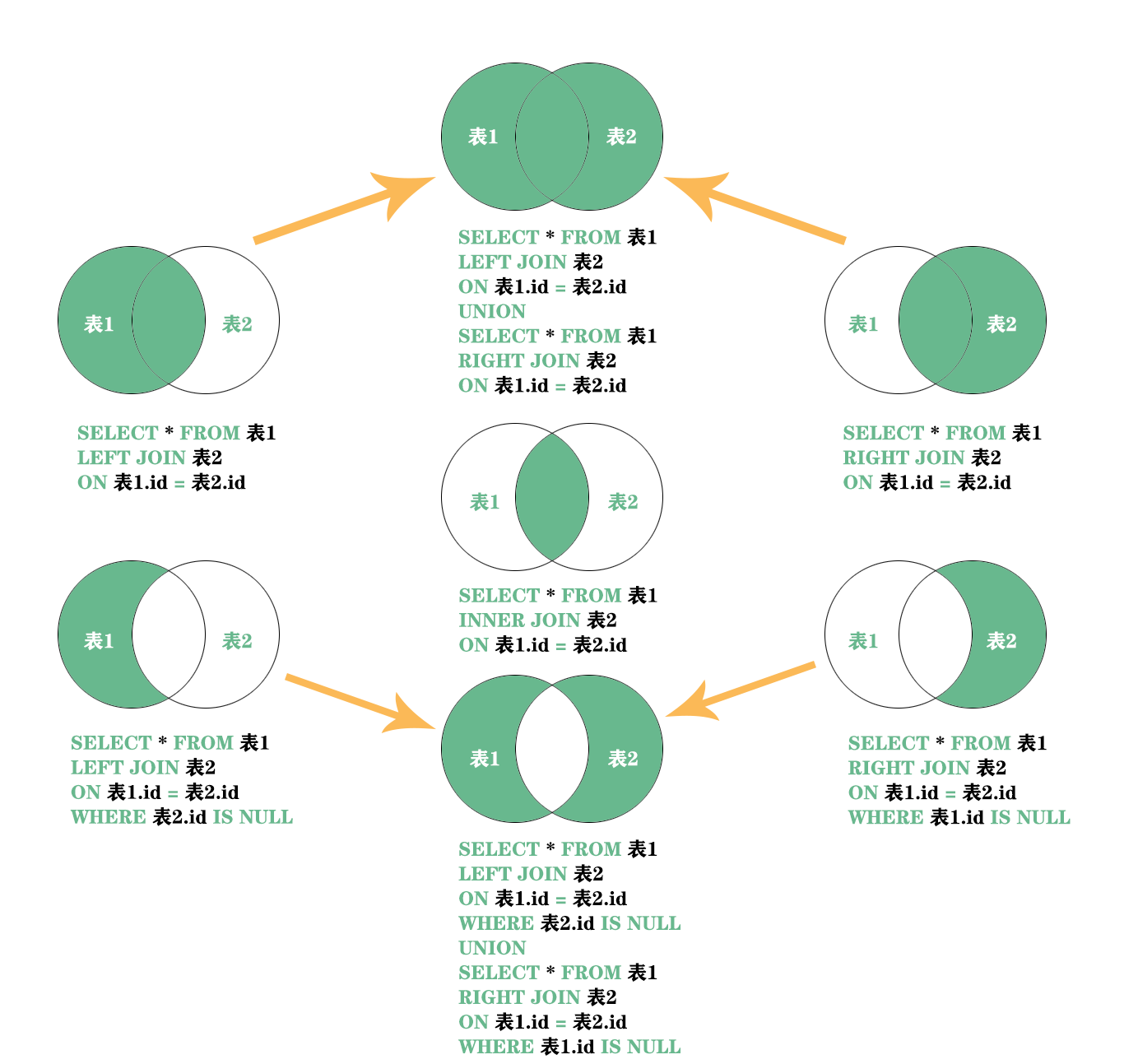
我们先建立表创建一些数据,经典用户表和部门表
用户表
-- 建表
CREATE TABLE `sys_user` (
`user_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`user_name` varchar(30) NOT NULL COMMENT '用户账号',
`nick_name` varchar(30) NOT NULL COMMENT '用户昵称',
`dept_id` bigint(20) DEFAULT NULL COMMENT '部门ID',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='用户信息表';
-- 插入数据
INSERT INTO `yy`.`sys_user`(`user_id`, `user_name`, `nick_name`, `dept_id`) VALUES (1, '管理员', 'admin', 10);
INSERT INTO `yy`.`sys_user`(`user_id`, `user_name`, `nick_name`, `dept_id`) VALUES (2, '张三', 'zs', 10);
INSERT INTO `yy`.`sys_user`(`user_id`, `user_name`, `nick_name`, `dept_id`) VALUES (3, '李四', 'ls', 11);
INSERT INTO `yy`.`sys_user`(`user_id`, `user_name`, `nick_name`, `dept_id`) VALUES (4, '王五', 'ww', 10);
INSERT INTO `yy`.`sys_user`(`user_id`, `user_name`, `nick_name`, `dept_id`) VALUES (5, '老六', 'll', 11);
INSERT INTO `yy`.`sys_user`(`user_id`, `user_name`, `nick_name`, `dept_id`) VALUES (6, '小七', 'xq', NULL);
部门表
-- 建表
CREATE TABLE `sys_dept` (
`dept_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '部门id',
`parent_id` bigint(20) DEFAULT '0' COMMENT '父部门id',
`dept_name` varchar(30) DEFAULT '' COMMENT '部门名称',
PRIMARY KEY (`dept_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=126 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='部门表';
-- 插入数据
INSERT INTO `yy`.`sys_dept`(`dept_id`, `parent_id`, `dept_name`) VALUES (10, 0, '法外狂徒部');
INSERT INTO `yy`.`sys_dept`(`dept_id`, `parent_id`, `dept_name`) VALUES (11, 0, '伏地魔部');
INSERT INTO `yy`.`sys_dept`(`dept_id`, `parent_id`, `dept_name`) VALUES (12, 0, '测试部')
第一种 left join 左关联查询
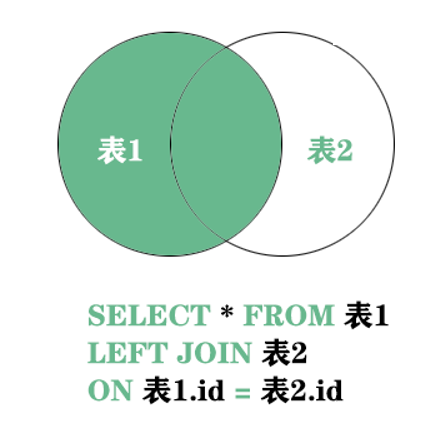
SQL语句
SELECT * FROM sys_user u LEFT JOIN sys_dept d ON u.dept_id = d.dept_id;
结果:

LEFT JOIN是以左表为主,不管有没有匹配到右表的数据都要显示左边的数据,SQL语句中写在LEFT JOIN左边的表是左表,写在右边的那自然就是右表!
第二种 left join 左关联查询 过滤右表条件为null的情况
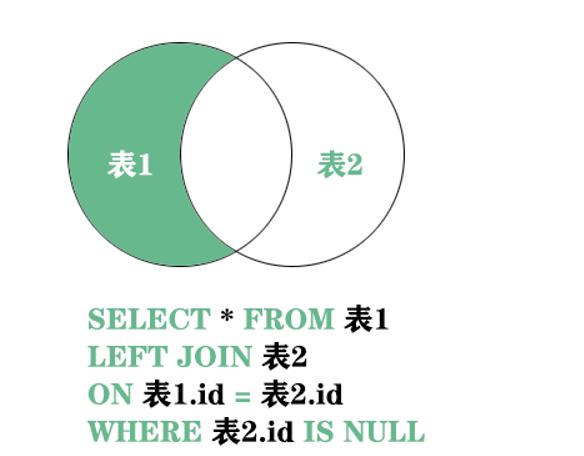
SQL语句
SELECT * FROM sys_user u LEFT JOIN sys_dept d ON u.dept_id = d.dept_id WHERE d.dept_id IS NULL;
结果: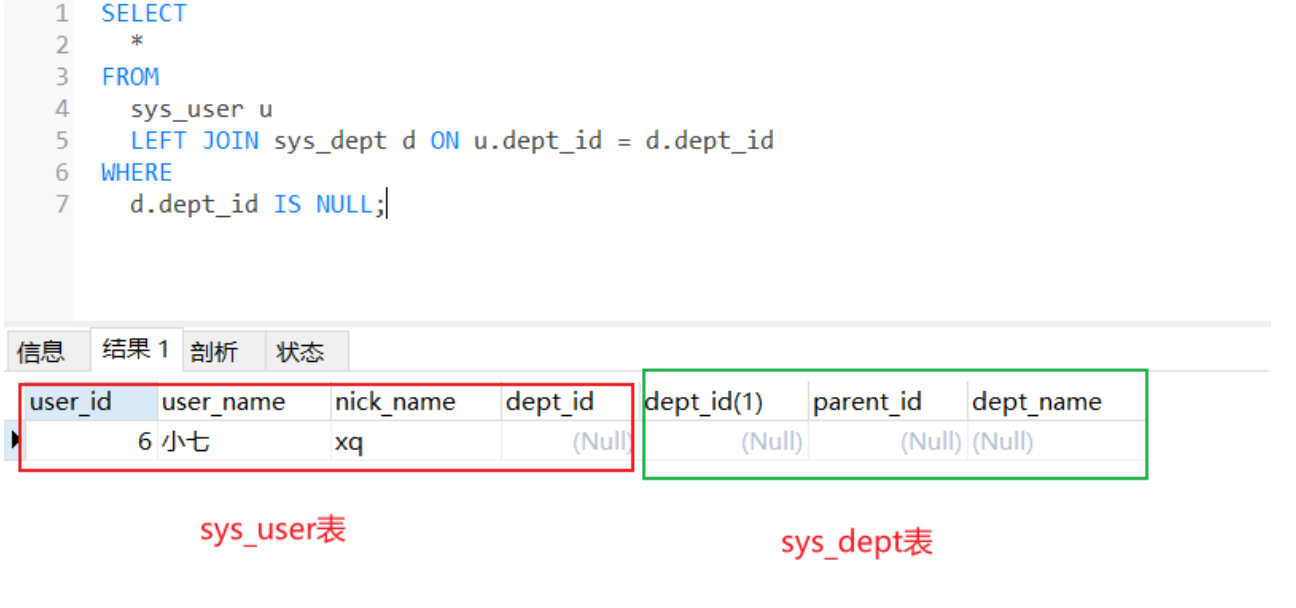
在原先的基础上多加了WHERE d.dept_id IS NULL的条件,这个条件筛选出sys_user表中dept_id字段为空的数据,结果集中不包含和sys_dept表对应的数据
第三种 right join 左关联查询 过滤右表条件为null的情况
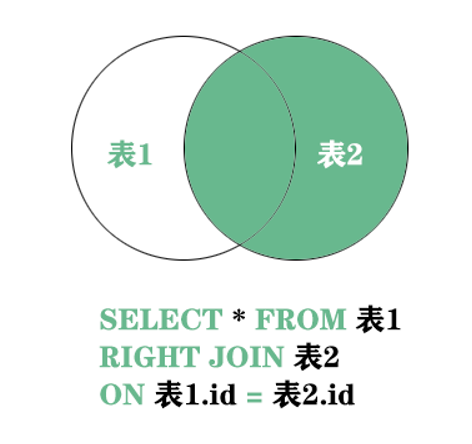
SQL语句
SELECT * FROM sys_user u RIGHT JOIN sys_dept d ON u.dept_id = d.dept_id;
结果: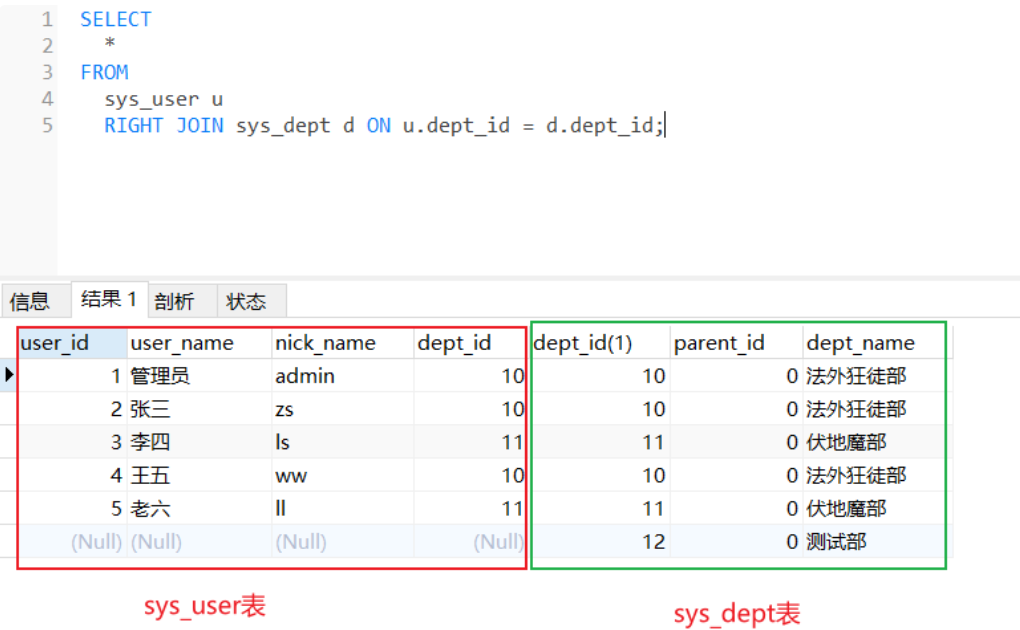
这个结果集和LEFT JOIN的恰恰相反,只是主体换了而已
第4种 right join 左关联查询 过滤右表条件为null的情况

SQL语句
SELECT * FROM sys_user u RIGHT JOIN sys_dept d ON u.dept_id = d.dept_id WHERE u.dept_id IS NULL;
结果: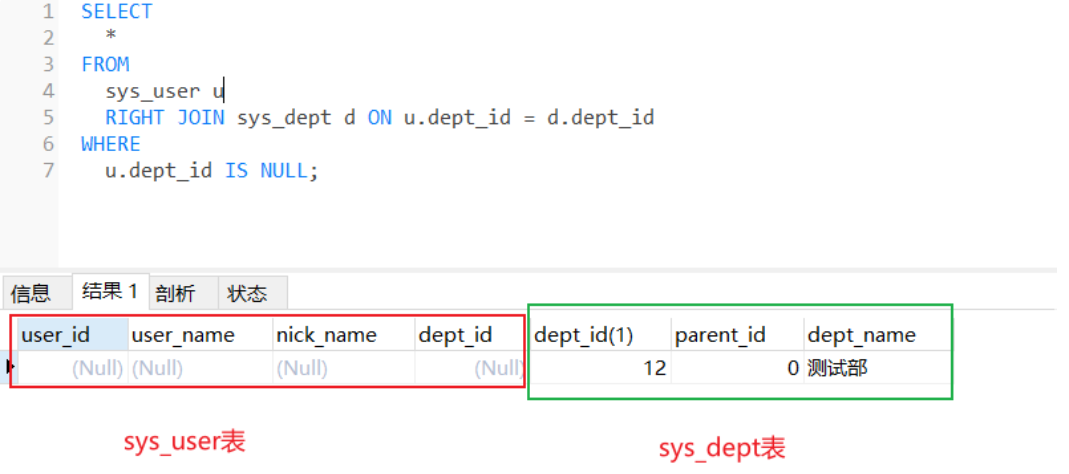
这个结果集和LEFT JOIN的恰恰相反,只是主体换了
第5种 全集
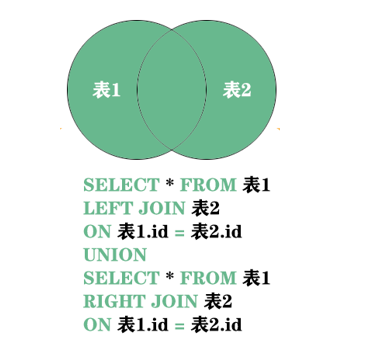
SQL语句
SELECT * FROM sys_user u LEFT JOIN sys_dept d ON u.dept_id = d.dept_id
UNION
SELECT * FROM sys_user u RIGHT JOIN sys_dept d ON u.dept_id = d.dept_id;```
结果:
该结果集只是使用UNION关键字将上述第一种和第三种的结果集进行了拼接,union 会剔除重复的交叉数据,如果你想看重复的数据就要使用UNION ALL关键字(笛卡尔积),如下
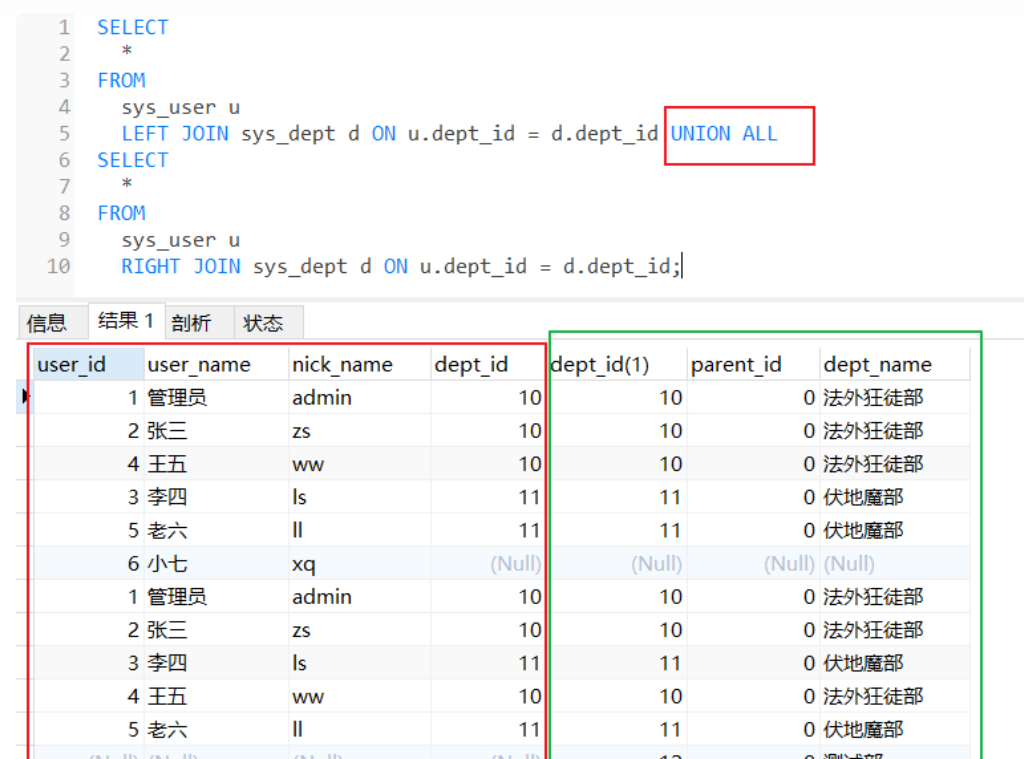
效果与
```sql
SELECT * FROM sys_user u , sys_dept d
效果完全一致
第6种 取差集

SQL语句
SELECT * FROM sys_user u
LEFT JOIN sys_dept d ON u.dept_id = d.dept_id
WHERE d.dept_id IS NULL
UNION
SELECT * FROM sys_user u
RIGHT JOIN sys_dept d ON u.dept_id = d.dept_id
WHERE u.dept_id IS NULL;```
结果:
就是剔除了两张表共同的数据部分
#### 第7种 取交集
SQL语句
```sql
SELECT * FROM sys_user u INNER JOIN sys_dept d ON u.dept_id = d.dept_id;
或者
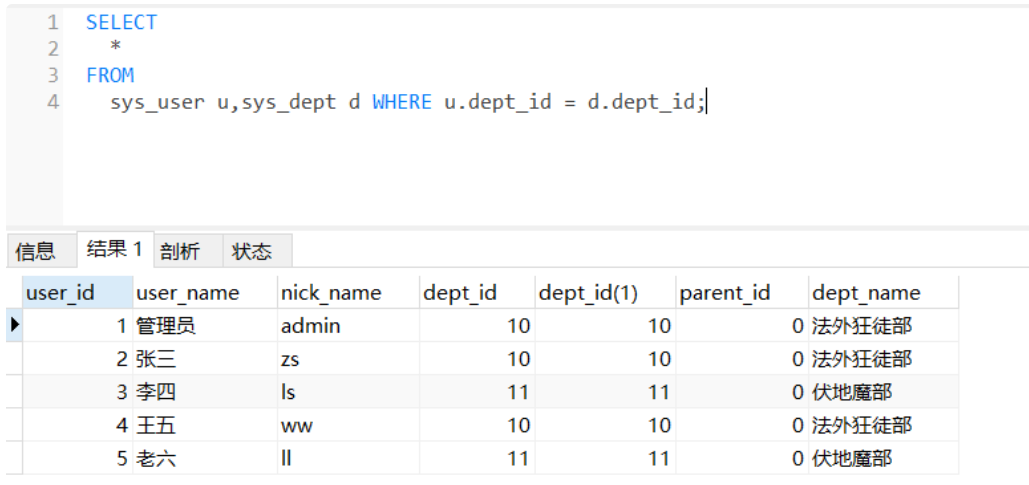
SELECT * FROM sys_user u ,sys_dept d where u.dept_id = d.dept_id;
结果: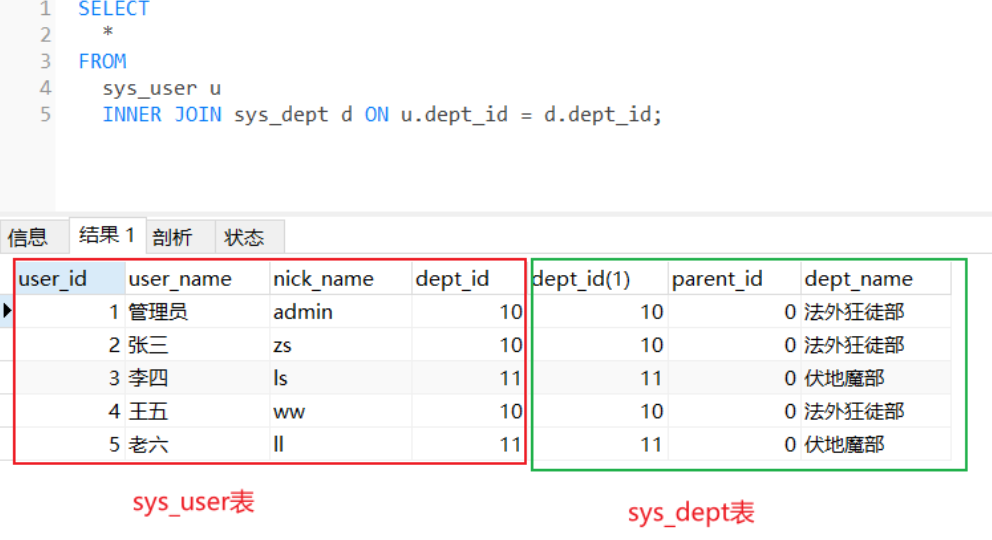

 浙公网安备 33010602011771号
浙公网安备 33010602011771号