grep 、sed、awk被称为linux中的"三剑客"。
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本
awk 更适合格式化文本,对文本进行较复杂格式处理
sed英文全称是stream editor,sed 是一种新型的,非交互式的编辑器。它能执行与编辑器 vi 和 ex 相同的编辑任务。sed 编辑器没有提供交互式使用方式,使用者只能在命令行输入编辑命令、指定文件名,然后在屏幕上查看输出。 sed 编辑器没有破坏性,它不会修改文件,除非使用 shell 重定向来保存输出结果。默认情况下,所有的输出行都被打印到屏幕上。
sed 编辑器逐行处理文件(或输入),并将输出结果发送到屏幕。 sed 的命令就是在 vi和 ed/ex 编辑器中见到的那些。 sed 把当前正在处理的行保存在一个临时缓存区中,这个缓存区称为模式空间或临时缓冲。sed 处理完模式空间中的行后(即在该行上执行 sed 命令后),就把改行发送到屏幕上(除非之前有命令删除这一行或取消打印操作)。 sed 每处理完输入文件的最后一行后, sed 便结束运行。 sed 把每一行都存在临时缓存区中,对这个副本进行编辑,所以不会修改或破坏源文件。
sed 命令行格式为: sed [选项] 'command' 文件
参数说明:
- -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或--help 显示帮助。
- -n或--quiet或--silent 仅显示script处理后的结果。
- -V或--version 显示版本信息。
动作说明:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
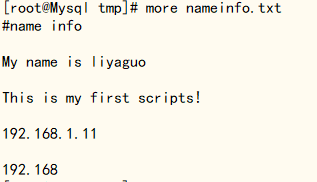
新建一个文件,nameinfo.txt,详细信息如下

1、替换文件中所有的168为134,这个只是预修改,并没有修改原文件;
[root@Mysql tmp]# sed 's/168/134/' nameinfo.txt
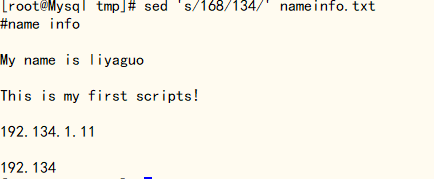
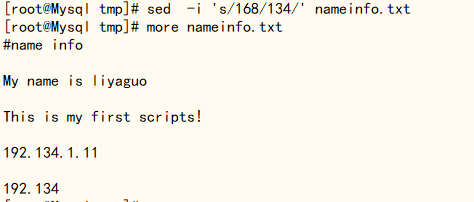
如果想同时修改原文件,可以加 i 参数
[root@Mysql tmp]# sed -i 's/168/134/' nameinfo.txt
此时,不会在输出到屏幕
2、文件每行添加内容,比如添加一个test;
[root@Mysql tmp]# sed 's/^/test /g' nameinfo.txt ,同样原文件不改变,(^头添加,$尾添加)

3、在某行后面添加内容,用a,会新起一行添加,而用i ,则会在上面新起一行添加
[root@Mysql tmp]# sed '/liyaguo/a name' nameinfo.txt
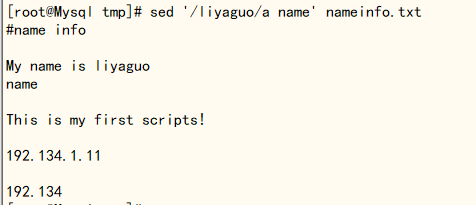
在文件 内容 My name is liyaguo 添加一个 name的内容,可以看到是添加了一个新的行
4、打印 name 所在行
[root@Mysql tmp]# sed -n '/name/p' nameinfo.txt

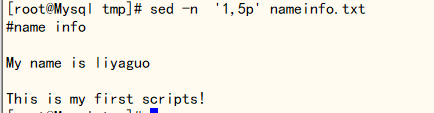
打印 1,5行
[root@Mysql tmp]# sed -n '1,5p' nameinfo.txt
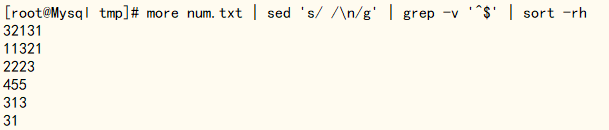
综合案例:给文件(num.txt)中的数字进行排序,获取最大和最小值

[root@Mysql tmp]# more num.txt | sed 's/ /\n/g' | grep -v '^$' | sort -rh
sed 's/ /\n/g' :
用换行更换空格符号
grep -v '^$' :
用^$ 匹配空字符,然后利用grep -v参数排除
sort -h:
排序,如果sort -rh,加上-r 就是倒序排列

sed -n '1p;$p':
获取第一行和最后一行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号