
P10996 【MX-J3-T3】Tuple 题解
好久没写题解了
思路
注意到合法的四元组 \((a, b, c, d)\) 形如:
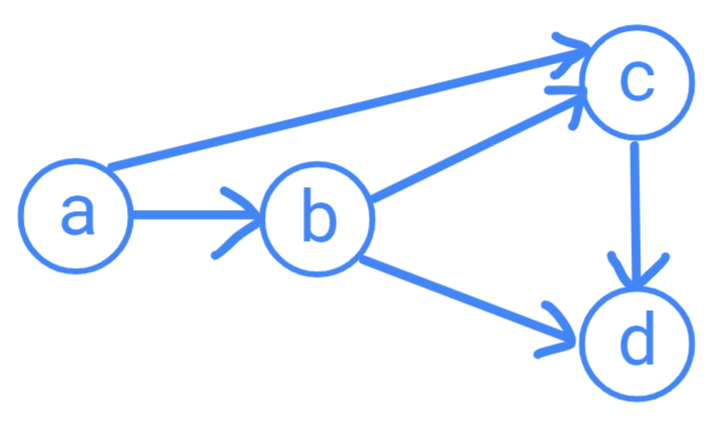
(如果 \(u\) 有一个箭头连出到 \(v\),则表示在输入的三元组中存在一组三元组使得 \(v\) 是 \(u\) 的后继(即形如 \((u, v, *)\) 或 \((*, u, v)\),\(*\) 则表示我们不关心这个元素))
观察这张图,我们可以得出一些关系:
- \(b\) 是 \(a\) 的后继
- \(c\) 同时是 \(a\) 和 \((a, b)\) 的后继(二元组 \((u, v)\) 的后继定义为所有的 \(w\) 使得存在一组三元组 \((u, v, w)\))
- \(d\) 同时是 \((a, b)\)、 \((a, c)\) 和 \((b, c)\) 的后继
所以我们可以使用以下算法解决此问题:
- 枚举 \(a\)
- 枚举 \(a\) 作为三元组的第一个元素时的所有后继,即 \(a\) 固定时所有合法的 \(b\)(即形如 \((a, b, *)\))
- 在 \(a\) 的后继与 \((a, b)\) 的后继的交中枚举,即 \((a, b)\) 固定时所有合法的 \(c\)
- 将 \((a, b)\) 的后继、 \((a, c)\) 的后继与 \((b, c)\) 的后继的交的大小计入答案,即 \((a, b, c)\) 固定时所有合法的 \(d\) 的数量
实现细节与复杂度
如何实现上述算法?我们可以使用 bool 数组来储存一个元素或一个二元组的所有后继,即如果 \(x\) 是对应元素或元组的后继,则在对应的 bool 数组的 \(x\) 下标位置赋值为 true,那么遍历后继即遍历数组里所有为 true 的下标,两个后继的交即为两个后继 bool 数组相同的下标同时为 true的所有下标,交的数量就只要数一数有多少个都为 true 的下标即可
但储存上会有一个小问题,储存所有 \(O(n^2)\) 个二元组的 \(O(n)\) 个后继时会用到 \(O(n^3)\) 空间,这是不能接受的。但是我们注意到所有的三元组最多只有 \(O(m)\) 个,那么二元组也只有 \(O(m)\) 个。我们可以只开 \(O(m)\) 个后继数组,将每个出现过的二元组用 \(1 \sim m\) 编号,并存储在对应编号的后继数组中,这样就只需要 \(O(n^2+nm)\) 空间。
还有时间复杂度没有讨论:
- 枚举三元组 \((a, b, c)\) 一共需要 \(O(n^2+nm)\) 代价,因为:
-
枚举每个 \(a\) 再枚举 \(b\) 判断是否是后继总共需要 \(O(n^2)\) 代价,而 \((a, b)\) 最多只有 \(O(m)\) 对。
-
对于每个 \((a, b)\) 求出 \(a\) 后继与 \((a, b)\) 后继的交需要 \(O(n)\) 代价,在交中枚举总共需要 \(O(m)\) 代价,因为所有的三元组 \((a, b, c)\) 最多只有 \(O(m)\) 对
- 对于 \(O(m)\) 个三元组 \((a, b, c)\) 计算 \((a, b)\) 的后继、 \((a, c)\) 的后继与 \((b, c)\) 的后继的交的大小需要 \(O(n)\) 时间,所以总共需要 \(O(nm)\) 代价
故此算法时间复杂度为 \(O(n^2+nm)\)
代码
赛时我使用了 bitset 代替 bool 数组,bitset 是个标准库中的容器,在 \(64\) 位操作系统上将一个 \(64\) 位整数的每一位当作一个 bool 变量,所以储存空间拥有 \(\frac{1}{8}\) 的常数,做很多常见操作,如给两个 bool 数组的相同的下标上的元素求 & 时拥有 \(\frac{1}{64}\) 的常数。为了用 \(O\) 标记体现 bitset 带来的优化,同时也为了体现操作系统位数对优化的差异,我们设 \(w\) 为操作系统位数,若使用 bitset 优化本算法,时间复杂度则为 \(O(\frac{n^2+nm}{w})\)。
我会在本题的代码的注释中解释 bitset 对应的操作的作用,若对 bitset 支持的更多操作感兴趣可以前往 OI-Wiki 学习更多用法。
#include <iostream>
#include <bitset>
using namespace std;
using ll = long long;
constexpr int N = 2000 + 1, M = 50000 + 1;
int mid[N][N];
bitset<N> um[N], uvm[M];
int main() {
int n, m;
cin >> n >> m;
int tot = 0;
for (int i = 1; i <= m; ++i) {
int u, v, w;
cin >> u >> v >> w;
int &nid = mid[u][v];//(u, v) 二元组对应的编号
if (!nid) {//如果之前没有编号过
nid = ++tot;//新建编号
}
um[u][v] = true; uvm[nid][w] = true;
}
ll ans = 0;
for (int a = 1; a < n; ++a) {
auto &uma = um[a];
for (int b = uma._Find_next(a)/*_Find_next(x)函数:找到 bitset 中 x 下标后的第一个 true 的位置*/; b <= n; b = uma._Find_next(b)) {//实现了 b 不重不漏地遍历了 a 的所有后继
auto &uvmab = uvm[mid[a][b]];
auto cs = uma & uvmab;//& 运算符:求两个 bitset 每个相同下标对应的元素的 & 的结果,cs 即为 a 的后继与 (a, b) 的后继求交后的 bitset
for (int c = cs._Find_next(b); c <= n; c = cs._Find_next(c)) {//同理,访问所有合法的 c
ans += (uvmab & uvm[mid[b][c]] & uvm[mid[a][c]]).count();//count函数:数一个 bitset 中有多少个下标为 true,将 $(a, b)$ 的后继、 $(a, c)$ 的后继与 $(b, c)$ 的后继的交的大小计入答案
}
}
}
cout << ans << '\n';
return 0;
}
评价与总结
此题很好地考察了均摊枚举的基本技巧,是一道很合适的普及组赛题。均摊枚举的关键就是尽量保证每次枚举到的元素都是对计入答案有贡献的。
同时题目也需要对分析均摊复杂度有一定理解,复杂度并不是简单的嵌套起来的代价相乘,有时也要注意到代价有总和保证。
希望写得这么详细可以让一个刚学会 bool 数组的萌新也可以看懂,也是让普及组选手更好地感受均摊枚举的魅力。如任何人有任何不理解的地方或者异议欢迎私信!
posted on 2024-08-26 14:25 SkyWave2022 阅读(70) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号