re模块 - 正则表达式 疏理(一)
在网上总是很难找到令自己比较满意的,关于正则表达式的文章。所以决定自己来总结一波,并配上相应的示例。
正则表达式:定义了规则,用来字符串处理。
用途:
1、匹配 - 符合规则的字符串,则认为匹配了。
2、提取 - 提取出符合规则的字符串。
python中通过re模块来处理正则表达式。re模块的常用方法如下:
re.match(re规则,字符串):从头开始匹配。从字符串的第一个字符开始匹配,如果第一个字符不匹配规则,那么匹配失败。
re.search(re规则,字符串):匹配包含。不要求从字符串的第一个字符就匹配。只要字符串当中有匹配该规则的,则就匹配成功。
re.findall(re规则,字符串):把所有匹配的字符放在列表中并返回。
re.sub(re规则,替换串,被替换串):匹配字符并替换。
正则表达式常用的规则如下:
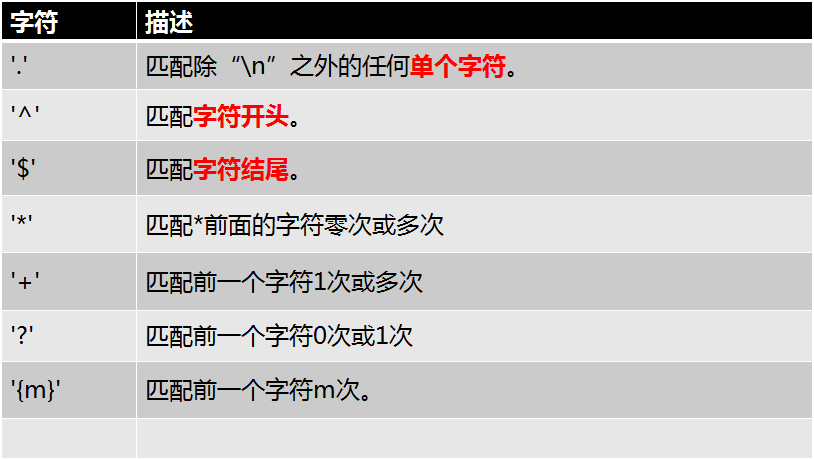
下面一一示例来说明:
'.' : 是只匹配一个字符(除了\n)
如字符串a="hello123world!!" , 那么'.'匹配到的结果为:"h" .从字符串a中搜索,搜索什么呢,符合规则'.'的数据。
1 >>> import re #导入正则模块
2 >>> re.search('.','hello123world!!') #使用search方法
3 <_sre.SRE_Match object; span=(0, 1), match='h'> #匹配成功,返回了一个匹配对象。匹配的结果为:h match=表示匹配到的结果
'^' : 匹配字符串的开头。指定字符串必须以什么开头,如果不一样,则匹配失败。
如字符串a="hello123world!!" , 那么'^h'匹配到的结果为:"h" .如果是'^F'则匹配失败
1 >>> re.search('^h','hello123world!!')
2 <_sre.SRE_Match object; span=(0, 1), match='h'> #匹配以h开头的字符串,匹配成功,匹配结果为:h
3 >>> re.search('^F','hello123world!!')
4 >>> #匹配失败,为None
re.match方法也是从字符串开头匹配。所以与^效果一样:
1 1 >>> re.match('h','hello123world!!')
2 2 <_sre.SRE_Match object; span=(0, 1), match='h'> #匹配以h开头的字符串,匹配成功,匹配结果为:h
3 3 >>> re.match('F','hello123world!!')
4 4 >>> #匹配失败,没有输出
'$':指定字符串以$前的字符结尾 。
1 >>> re.search('!$','hello123world!!')
2 <_sre.SRE_Match object; span=(14, 15), match='!'> #匹配以!结尾的字符串,匹配成功,匹配结果为:!
4 >>> re.search('D$','hello123world!!')
5 >>> #匹配以D结尾的字符串,失败
'*':表示匹配前面的字符 0次 或者 多次
'+':表示匹配前面的字符 1次 或者 多次
以上的所有匹配都只是匹配到了一个字符。那这两个匹配符则可以匹配多次。
1 >>> re.search('lll*','hello123world!!')
2 <_sre.SRE_Match object; span=(2, 4), match='ll'> #*可以匹配到至于2个l
3
4 >>> re.search('lll+','hello123world!!')
5 >>> # +至少要匹配三个l 所以匹配失败
如果我想要指定匹配次数呢? -----
'{m} ':指定匹配前面字符的次数。
1 >>> re.search('el{2}','hello123world!!')
2 <_sre.SRE_Match object; span=(1, 4), match='ell'> #匹配l两次
3 >>>
4 >>> re.search('el{3}','hello123world!!') #匹配l三次 ,匹配失败
5 >>>
6 >>> re.search('el{1}','hello123world!!')
7 <_sre.SRE_Match object; span=(1, 3), match='el'> #匹配l一次
如果只考虑匹配 0次 或者 1次呢 ---
'?':表示匹配前面的字符 0次 或者 1次
1 >>> re.search('el?','hello123world!!')
2 <_sre.SRE_Match object; span=(1, 3), match='el'> #?匹配l 0次或者 1次
3 >>>
4 >>> re.search('ello7?','hello123world!!')
5 <_sre.SRE_Match object; span=(1, 5), match='ello'> #? 匹配7 0次或者1次
第一波总结到这里打止。。欢迎留言和交流。
*******有任何疑问,欢迎加微:qd20150815 (加时请备注:博客园-简)*******

 浙公网安备 33010602011771号
浙公网安备 33010602011771号