
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程
上述安装教程已实践,可行。(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所以没有在Ubuntu上装,至于如何在Ubuntu上安装Scrapy,网上有挺多教程的)
Scrapy的入门教程见下面链接:Scrapy入门教程
上面的入门教程是很基础的,先跟着作者走一遍,要动起来哟,不要只是阅读上面的那篇入门教程。
下面我简单总结一下Scrapy爬虫过程:
1、在Item中定义自己要抓取的数据:
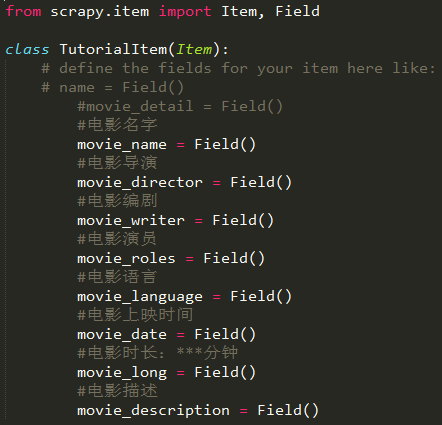
movie_name就像是字典中的“键”,爬到的数据就像似字典中的“值”。在继承了BaseSpider的类中会用到:
 第一行就是上面那个图中的TutorialItem这个类,红框圈出来的就是上图中的movie_name这个变量
第一行就是上面那个图中的TutorialItem这个类,红框圈出来的就是上图中的movie_name这个变量
2、然后在spiders目录下编辑Spider.py那个文件
按上面【入门教程】来写就行了,我这边给个例子,跟我上面的item是匹配的:
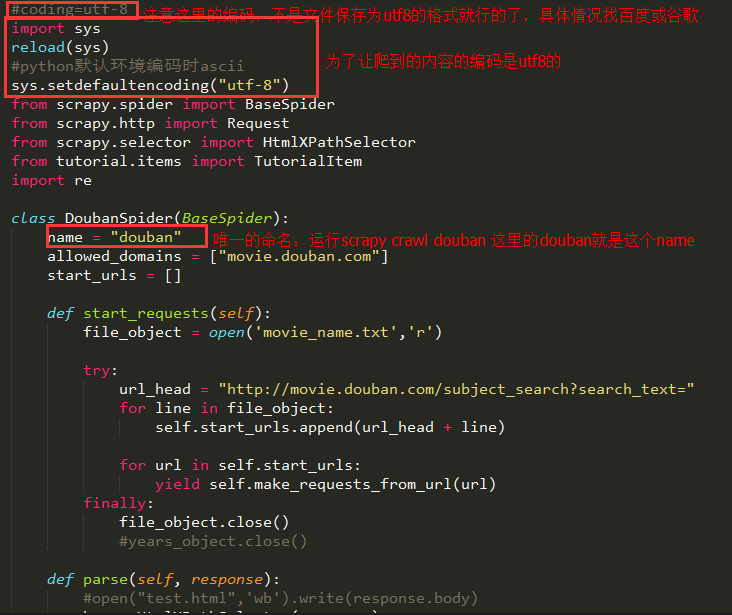
【入门教程】你没有给出start_requests这个方法,稍后我会讲到这个方法。另外这里的代码我都是截图,后面我会用代码面板显示我的代码,有需要的人可以复制下来玩玩。
3、编辑pipelines.py文件,可以通过它将保存在TutorialItem中的内容写入到数据库或者文件中
下面的代码示例是写到文件(如果要写到数据库中去,这里有个示例代码)中去:

对json模块的方法的注释:dump和dumps(从Python生成JSON),load和loads(解析JSON成Python的数据类型);dump和dumps的唯一区别是dump会生成一个类文件对象,dumps会生成字符串,同理load和loads分别解析类文件对象和字符串格式的JSON。(注释来于http://www.jb51.net/article/52224.htm )
4、爬虫开始
上述三个过程后就可以爬虫了,仅需上述三个过程哟,然后在dos中将目录切换到tutorial下输入scrapy crawl douban就可以爬啦:

上面几个过程只是先理清楚用Scrapy爬虫的思路,下面的重点戏是第二个过程,我会对这个过程进行较详细的解释,并提供代码。
douban_spider.py这个文件的代码如下:


1 #coding=utf-8 2 import sys 3 reload(sys) 4 #python默认环境编码时ascii 5 sys.setdefaultencoding("utf-8") 6 from scrapy.spider import BaseSpider 7 from scrapy.http import Request 8 from scrapy.selector import HtmlXPathSelector 9 from tutorial.items import TutorialItem 10 import re 11 12 class DoubanSpider(BaseSpider): 13 name = "douban" 14 allowed_domains = ["movie.douban.com"] 15 start_urls = [] 16 17 def start_requests(self): 18 file_object = open('movie_name.txt','r') 19 20 try: 21 url_head = "http://movie.douban.com/subject_search?search_text=" 22 for line in file_object: 23 self.start_urls.append(url_head + line) 24 25 for url in self.start_urls: 26 yield self.make_requests_from_url(url) 27 finally: 28 file_object.close() 29 #years_object.close() 30 31 def parse(self, response): 32 #open("test.html",'wb').write(response.body) 33 hxs = HtmlXPathSelector(response) 34 #movie_name = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@title').extract() 35 movie_link = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@href').extract() 36 #movie_desc = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[2]/div/p/text()').extract() 37 38 if movie_link: 39 yield Request(movie_link[0],callback=self.parse_item) 40 41 42 def parse_item(self,response): 43 hxs = HtmlXPathSelector(response) 44 movie_name = hxs.select('//*[@id="content"]/h1/span[1]/text()').extract() 45 movie_director = hxs.select('//*[@id="info"]/span[1]/span[2]/a/text()').extract() 46 movie_writer = hxs.select('//*[@id="info"]/span[2]/span[2]/a/text()').extract() 47 #爬取电影详情需要在已有对象中继续爬取 48 movie_description_paths = hxs.select('//*[@id="link-report"]') 49 movie_description = [] 50 for movie_description_path in movie_description_paths: 51 movie_description = movie_description_path.select('.//*[@property="v:summary"]/text()').extract() 52 53 #提取演员需要从已有的xPath对象中继续爬我要的内容 54 movie_roles_paths = hxs.select('//*[@id="info"]/span[3]/span[2]') 55 movie_roles = [] 56 for movie_roles_path in movie_roles_paths: 57 movie_roles = movie_roles_path.select('.//*[@rel="v:starring"]/text()').extract() 58 59 #获取电影详细信息序列 60 movie_detail = hxs.select('//*[@id="info"]').extract() 61 62 item = TutorialItem() 63 item['movie_name'] = ''.join(movie_name).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') 64 #item['movie_link'] = movie_link[0] 65 item['movie_director'] = movie_director[0].strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') if len(movie_director) > 0 else '' 66 #由于逗号是拿来分割电影所有信息的,所以需要处理逗号;引号也要处理,否则插入数据库会有问题 67 item['movie_description'] = movie_description[0].strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') if len(movie_description) > 0 else '' 68 item['movie_writer'] = ';'.join(movie_writer).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') 69 item['movie_roles'] = ';'.join(movie_roles).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') 70 #item['movie_language'] = movie_language[0].strip() if len(movie_language) > 0 else '' 71 #item['movie_date'] = ''.join(movie_date).strip() 72 #item['movie_long'] = ''.join(movie_long).strip() 73 74 #电影详情信息字符串 75 movie_detail_str = ''.join(movie_detail).strip() 76 #print movie_detail_str 77 78 movie_language_str = ".*语言:</span> (.+?)<br><span.*".decode("utf8") 79 movie_date_str = ".*上映日期:</span> <span property=\"v:initialReleaseDate\" content=\"(\S+?)\">(\S+?)</span>.*".decode("utf8") 80 movie_long_str = ".*片长:</span> <span property=\"v:runtime\" content=\"(\d+).*".decode("utf8") 81 82 pattern_language =re.compile(movie_language_str,re.S) 83 pattern_date = re.compile(movie_date_str,re.S) 84 pattern_long = re.compile(movie_long_str,re.S) 85 86 87 movie_language = re.search(pattern_language,movie_detail_str) 88 movie_date = re.search(pattern_date,movie_detail_str) 89 movie_long = re.search(pattern_long,movie_detail_str) 90 91 item['movie_language'] = "" 92 if movie_language: 93 item['movie_language'] = movie_language.group(1).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') 94 #item['movie_detail'] = ''.join(movie_detail).strip() 95 96 item['movie_date'] = "" 97 if movie_date: 98 item['movie_date'] = movie_date.group(1).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') 99 100 item['movie_long'] = "" 101 if movie_long: 102 item['movie_long'] = movie_long.group(1) 103 104 yield item
代码有了,我来一步步讲解哈。
前言:我要爬的是豆瓣的数据,我有了很多电影的名字,但是我需要电影的详情,我用了一下豆瓣电影的网站,发现当我在搜索框里输入“Last Days in Vietnam”时url会变成http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam&cat=1002 然后我就试着直接输入http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam这个url,搜索结果是一样的,很显然这就是get方式,这样我们就找到了规律:http://movie.douban.com/subject_search?search_text=后面加上我们的电影名字并用加号分割就行了。
我们的电影名字(大量的电影名字)是存在movie_name.txt这个文件中里面的(一行一个电影名字):
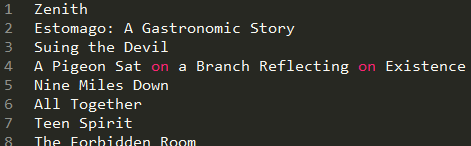
我们可以先用python脚本(shell脚本也行)将电影名之间的空格处理为+,也可以在爬虫中读取电影名后进行一次replace处理(我是先处理成+的)。爬虫读取电影名字文件,然后构建url,然后就根据得到的网页找到搜索到的第一个电影的url(其实第一个电影未必一定是我们要的,但是这种情况是少数,我们暂时不理会它),得到第一个电影的url后,再继续爬,这次爬到的页面就含有我们想要的电影信息,需要使用XPath来获得html文件中元素节点,最后将获得的信息存到TutorialItem中,通过pipelines写入到data.dat文件中。
XPath的教程在这里:w3school的基础教程和scrapy官网上的Xpath 这些东西【入门教程】中都有说。
1、start_requests方法:
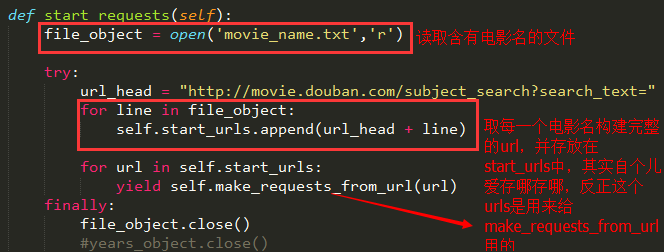
在【入门教程】那篇文章中没有用到这个方法,而是直接在start_urls中存入我们要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写这个方法了,首先我们看看start_requests这个方法是干嘛的:
 可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
start_requests官方解释在这里
那么这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入我们自定义的规律的链接:
2、parse方法:
生成了请求后,scrapy会帮我们处理Request请求,然后获得请求的url的网站的响应response,parse就可以用来处理response的内容。在我们继承的类中重写parse方法:

parse_item是我们自定义的方法,用来处理新连接的request后获得的response:
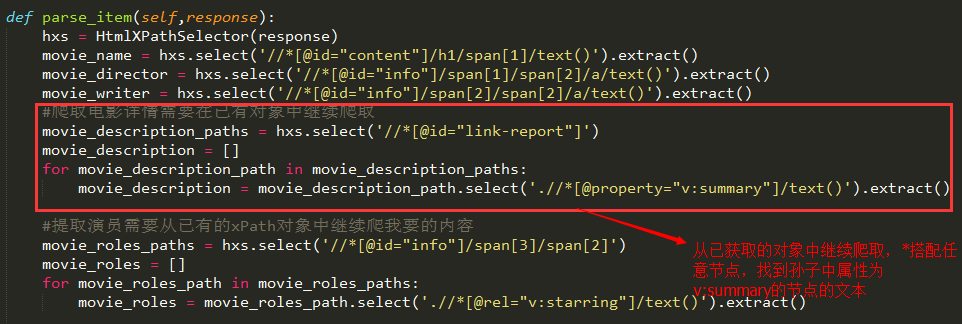
HtmlXPathSelector的解释在这里
为了获得我想要的数据我也是蛮拼的,由于豆瓣电影详情的节点是没太大规律了,我后面还用了正则表达式去获取我要的内容,具体看上面的代码中parse_item这个方法吧:
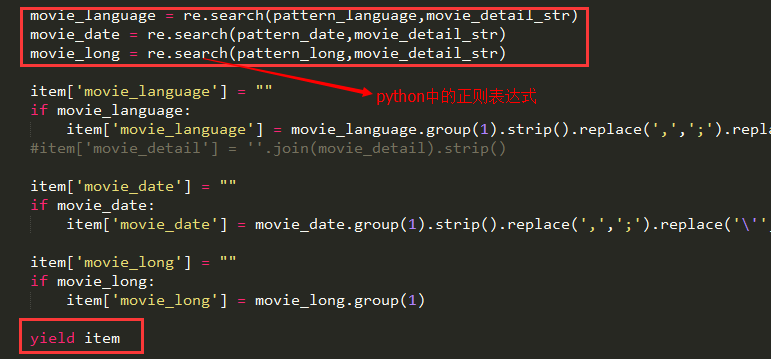
好了,结束了,这里还有一篇Scrapy的提高篇,有兴趣的去看看吧。
写写博客是为了记录一下自己实践的过程,也希望能对需要者有用吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号