2020.6.7 编码 字符串 python前两行注释 格式化输出%与format
1、编码
ascii编码可以视为utf-8编码的一部分,utf-8对英文和一些字符的编码跟ascii相同,因此使用utf-8的可以兼容ascii,unicode编码都是两字节
计算机内存中,统一使用unicode编码;在需要保存到硬盘或者需要传输时,才转换为utf-8编码
用记事本编辑时,从文件读取的utf-8字符被转换为unicode编码到内存;完成后,保存的时候把unicode转换为utf-8保存到文件
浏览网页时,服务器把动态生成的unicode内容转换为utf-8再传输到浏览器,所以很多网页的源码上有
<meta charset="utf-8" />
表示该网页用utf-8编码
2、字符串
字符串类型为str,类比整数类型为int,可以用str进行强制类型转换将一个其他类型的数据转化为字符串
str(True) 'True' str(123) '123'
Python3中,字符串以unicode编码
可以用ord与chr分别将字符转化为对应的编码或者将编码转化为字符串
ord('中') 20013 chr(20013) '中'
注意:1、ord不是将字符整数化,而是求出该字符对应的unicode码
2、python2中ord对非ascii字符使用时,该字符要用u''表示,chr要用unichr
unicode转utf-8,从内存到网页或者硬盘 encode
回到我们在1、编码中提到的,字符串在内存中的编码为unicode,对应为python的str类型;而在网络上传输,或者保存在硬盘中,要转换为utf-8编码,对应的python类型为bytes
python对bytes类型的数据用带b前缀的单引号或者双引号表示b''或b""
unicode可以通过encode方法编码为utf-8
'中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' 'ABC'.encode('ascii') b'ABC'
纯英文的str可以用ascii转换为bytes(用utf-8效果相同,因为utf-8对英文字符的编码与ascii相同),含有中文字符的str只能用utf-8转化为bytes
bytes中,无法显示为ascii的字符,用/x##格式显示
utf-8转unicode,从网页/硬盘到内存 decode
如果我们从网页/硬盘上读取数据流,那么这些数据流是用utf-8表示的,属于bytes类型,用decode方法转化为str类型
方法中的参数是原类型utf-8或ascii,而不是需要转化到的类型unicode
b'ABC'.decode('ascii') 'ABC' b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') '中文'
如果bytes中包含无法解码的字节,decode方法会报错
b'\xe4\xb8\xad\xff'.decode('utf-8') Traceback (most recent call last): File "<input>", line 1, in <module> UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
如果只有一小部分字节错误,可以在decode中添加参数errors='ignore'忽视该错误字节,只转化可以转化的部分
b'\xe4\xb8\xad\xff'.decode('utf-8',errors='ignore') '中'
统计字符个数:len方法
len方法可以用来统计str(unicode)中的字符数,如果用在bytes中(UTF-8),就是统计字节数
len('ABC') 3
len('中文')
2
'中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' len('中文'.encode('utf-8')) 6
对于上述代码的解释,unicode中,一个中文字符即对应一个字符,而utf-8中,一个中文字符对应3个字节
由于python源文件是文本文件,所以当代码中存在中文,保存的时候要指明保存为utf-8。当python解释器读取源代码时,为了让其按照utf-8编码,通常在文件开头写上两行
#!/usr/bin/env python3 #coding:utf-8
第一行是为了告诉Linux/OS X系统,这是一个python可执行程序,windows会自动忽略该注释
第二行是为了告诉python解释器,要按照utf-8编码方式读取代码,否则代码中的中文输出可能会出现乱码
下图是测试结果,第一行出现了乱码,原因是我用的是
print '中文'#乱码 print u'中文' #正确
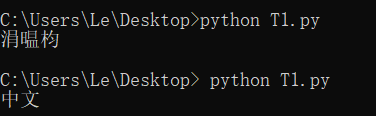
个人认为,启动方式为python3,则不会出现这种情况,因为python默认启动的是python2

3、格式化
①格式化输出字符串,用格式化符号%
需要输出的数据处加百分号%,一段字符串结束后再用一个%加实际数据
有多个数据需要格式化时,在最后的百分号后用括号将所有数据写出
'床前明月光,%s'%'疑是地上霜' '床前明月光,疑是地上霜' '今天是%d年,速度是%.2fkm,这里是%s市'%(2020,45.4096,'北京') '今天是2020年,速度是45.41km,这里是北京市'
%.2f表示保留两位小数,最后一位四舍五入,小数点前加数字类似%2.2f不论加几,效果都和不加(即%.2f)相同
但是用%2f,则会在小数最后补两个0
如果不确定该用什么,就用%s,不论后边输入的是不是str类型,都会转化为str类型
%2s不会对数据有任何影响
%.2s会只保留前两位,比如
'%.2s'%70.45 '70' '%.2s'%7.45 '7.'
如果字符串中存在一个%普通字符,可以用两个%%表示一个普通的%,前一个%是转义字符
'增长率为%d%%'%7 '增长率为7%'
②format
format将字符串中的占位符{0},{1}依次替换为format内的参数,如果要指定格式,占位符应写为类似形式
{1:.2f},表示取小数点后两位的浮点数
'今年是{0},经济增速{1:.2f}%'.format('2020年',7.4536) '今年是2020年,经济增速7.45%'
此时%没有别的含义,不需要转义
实际上,format使用的是字符串的format方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号