MYSQL 刷题笔记(持续更新)
- mysql语句group by
- 使用了group by语句之后的所有函数(max()、avg()、min()等等)都是仅针对组队进行使用!
- Union all / union
- 使用UNION可以实现将多个查询结果集合合并为一个结果集。
- ALL表示在结果集中不去除重复的记录。如果没有指定ALL则去除合并后结果集中的重复记录。
- CASE 函数
- 一种多分支的函数,可以根据条件列表的值返回多个可能的结果表达式中的一个.
- 可用在任何允许使用表达的地方,但不能单独作为一个语句执行。
- 分为:
- 简单case函数
-
1 CASE 测试表达式 2 WHEN 简单表达式1 THEN 结果表达式1 3 WHEN 简单表达式2 THEN 结果表达式2 … 4 WHEN 简单表达式n THEN 结果表达式n 5 [ ELSE 结果表达式n+1 ] 6 END
计算测试表达式,按从上到下的书写顺序将测试表达式的值与每个WHEN子句的简单表达式进行比较。如果某个简单表达式的值与测试表达式的值相等,则返回第一个与之匹配的WHEN子句所对应的结果表达式的值。如果所有简单表达式的值与测试表达式的值都不相等,若指定了ELSE子句,则返回ELSE子句中指定的结果表达式的值;若没有指定ELSE子句,则返回NULL。
-
- 搜索case函数
-
CASE WHEN 布尔表达式1 THEN 结果表达式1 WHEN 布尔表达式2 THEN 结果表达式2 … WHEN 布尔表达式n THEN 结果表达式n [ ELSE 结果表达式n+1 ] END
按从上到下的书写顺序计算每个WHEN子句的布尔表达式。返回第一个取值为TRUE的布尔表达式所对应的结果表达式的值。如果没有取值为TRUE的布尔表达式,则当指定了ELSE子句时,返回ELSE子句中指定的结果;如果没有指定ELSE子句,则返回NULL。
-
- 日期相关函数整理:
- 题目:计算用户的平均次日留存率。题目链接
- 题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请取出相应数据。
- 问题分解:第二天再来。
- 解法1:表里的数据可以看作是全部第一天来刷题了的,那么我们需要构造出第二天来了的字段,因此可以考虑用left join把第二天来了的拼起来,限定第二天来了的可以用
date_add(date1, interval 1 day)=date2筛选,并用device_id限定是同一个用户。 - 解法2:用lead函数将同一用户连续两天的记录拼接起来。先按用户分组
partition by device_id,再按日期升序排序order by date,再两两拼接(最后一个默认和null拼接),即lead(date) over (partition by device_id order by date)
- 解法1:表里的数据可以看作是全部第一天来刷题了的,那么我们需要构造出第二天来了的字段,因此可以考虑用left join把第二天来了的拼起来,限定第二天来了的可以用
- 问题分解:平均概率。
- 解法1:可以count(date1)得到左表全部的date记录数作为分母,count(date2)得到右表关联上了的date记录数作为分子,相除即可得到平均概率。
- 解法2:检查date2和date1的日期差是不是为1,是则为1(次日留存了),否则为0(次日未留存),取avg即可得到平均概率。
- 附:lead用法,date_add用法,datediff用法,date函数。
- SQL中的字符串分割
- 函数1:substring_index(str, delim, count)
- 参数:
- str: 要处理的字符串
- delim:分隔符
- count:计数
- SQL进阶-开窗函数() over (partition by)
- 开窗函数分为排序性开窗和聚合性开窗。
- 具体链接点此
- SQL相关功能函数
- 拼接函数:concat(char 01, char 02, ....)
- 左取字符函数:left(char, num)
- 大小字母变换:upper(), lower()
- 时间差:TIMESTAMPDIFF(interval, time_start, time_end)可计算time_start - time_end的时间差,单位以指定的interval为准
- 常用的interval有:second、minute、hour、day、month、year.
- 函数的时间差结果能够根据单位的选择直接换算为对应单位。
- coalesce是一个函数, coalesce (expression_1, expression_2, ...,expression_n) 依次参考各参数表达式,遇到非null值即停止并返回该值。
- select coalesce(success_cnt,period,1) from tableA 当success_cnt不为null,那么无论period是否为null,都将返回success_cnt的真实值(因为success_cnt是第一个参数),当success_cnt为null,而period不为null的时候,返回period的真实值。只有当success_cnt和period均为null的时候,将返回1。
- 将同一组(group)的查询结果拼接为一行结果:
group_concat(col1 order by col1 separator ',')拼接间隔默认为逗号”,“。
- 插入数据
-
insert into [table] (column 1, column 2, column 3, .....) values (value1, value2, value3, ......)
-
与insert 不同的是:replace会查看插入的数据主键在表中是否重复,如重复会先删除表中的数据再插入数据。
replace into [table] (column 1, column 2, column 3, .....) values (value1, value2, value3, ......)
-
- 修改数据
-
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
-
- 创建表
-
CREATE TABLE [IF NOT EXISTS] tb_name -- 不存在才创建,存在就跳过 (column_name1 data_type1 -- 列名和类型必选 [ PRIMARY KEY -- 可选的约束,主键 | FOREIGN KEY -- 外键,引用其他表的键值 | AUTO_INCREMENT -- 自增ID | COMMENT comment -- 列注释(评论) | DEFAULT default_value -- 默认值 | UNIQUE -- 唯一性约束,不允许两条记录该列值相同 | NOT NULL -- 该列非空 ], ... ) [CHARACTER SET charset] -- 字符集编码 [COLLATE collate_value] -- 列排序和比较时的规则(是否区分大小写等)
- 从另一张表复制表结构创建表: CREATE TABLE tb_name LIKE tb_name_old
- 从另一张表的查询结果创建表: CREATE TABLE tb_name AS SELECT * FROM tb_name_old WHERE options
- 修改表:
ALTER TABLE 表名 修改选项。选项集合:-
{ ADD COLUMN <列名> <类型> -- 增加列 | CHANGE COLUMN <旧列名> <新列名> <新列类型> -- 修改列名或类型 | ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT } -- 修改/删除 列的默认值 会重置这个列的所有设置。 | MODIFY COLUMN <列名> <类型> -- 修改列类型 仅仅只是修改类型,别的地方没有动。 | DROP COLUMN <列名> -- 删除列 | RENAME TO <新表名> -- 修改表名 | CHARACTER SET <字符集名> -- 修改字符集 | COLLATE <校对规则名> } -- 修改校对规则(比较和排序时用到)
-
-
-
- 删除表: DROP TABLE [IF EXISTS] 表名1 [ ,表名2]。
- 索引(看该文章)
- 定义:在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
- 数据库的底层索引实现主要有两种存储类型:B树(Btree)和哈希(HASH)索引。
- BTREE:InnoDB、MyISAM、MEMORY
- HASH:MEMORY
索引的作用:
- 可以提高检索数据的速度。
- 创建和维护索引需要耗费时间,耗费时间的数量随着数据量的增加而增加;索引需要占用物理空间,每一个索引要占一定的物理空间;增加、删除和修改数据时,要动态地维护索引,造成数据的维护速度降低了。
- 索引可以提高查询的速度,但是会影响插入记录的速度,因为向有索引的表中插入记录时,数据库系统会按照索引进行排序,这样就降低了插入记录的速度,插入大量记录时的速度影响更加明显。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
-
-- 创建索引的基本语法
CREATE INDEX indexName ON table(column(length));
-- 例子 length默认我们可以忽略
CREATE INDEX idx_name ON user(name); - 主键索引
- 我们知道每张表一般都会有自己的主键,mysql会在主键上建立一个索引,这就是主键索引。主键是具有唯一性并且不允许为NULL,所以他是一种特殊的唯一索引。一般在建立表的时候选定。
- 复合索引
- 复合索引也叫组合索引,指的是我们在建立索引的时候使用多个字段,例如同时使用身份证和手机号建立索引,同样的可以建立为普通索引或者是唯一索引。
- 例子:
-
-- 创建索引的基本语法 CREATE INDEX indexName ON table(column1(length),column2(length)); -- 例子 CREATE INDEX idx_phone_name ON user(phone,name);
-
看下面查询语句: SELECT * FROM user_innodb where name = '程冯冯'; SELECT * FROM user_innodb where phone = '15100046637'; SELECT * FROM user_innodb where phone = '15100046637' and name = '程冯冯'; SELECT * FROM user_innodb where name = '程冯冯' and phone = '15100046637';
- 三条sql只有 2 、 3、4能使用的到索引idx_phone_name,因为条件里面必须包含索引前面的字段才能够进行匹配。而3和4相比where条件的顺序不一样,为什么4可以用到索引呢?是因为mysql本身就有一层sql优化,他会根据sql来识别出来该用哪个索引,我们可以理解为3和4在mysql眼中是等价的。
- 全文索引
-
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。
-
它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。正常情况下我们也不会使用到全文索引,因为这不是mysql的专长。
-
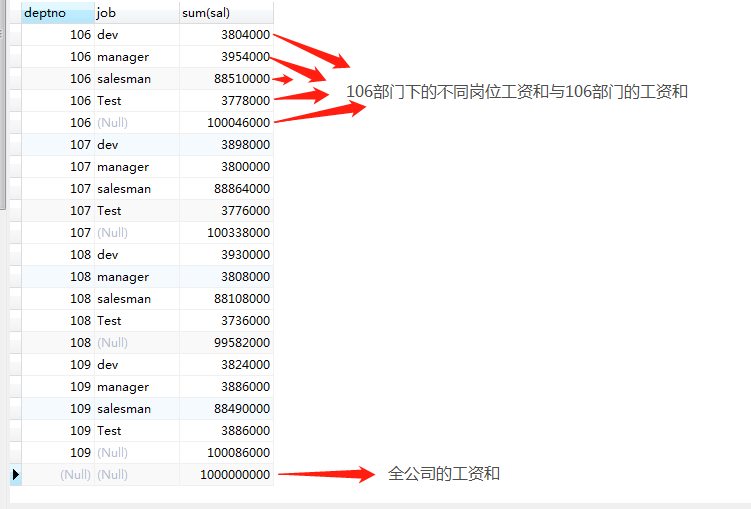
- with rollup
- rollup相对于简单的分组合计增加了小计和合计(适用于统计功能).
-
select deptno,job,sum(sal) from emp group by deptno,job with rollup;![]()
-
能少用表连接则应该尽可能少用表连接!看题目 解答.
-
表不大时做表连接影响不大,当表非常大的时候再做表连接会非常吃力!
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号