同样是库文件,嵌入式静态库和动态库差异到底在哪?
0、引言
在嵌入式开发中我们会将相关代码封装成库,核心目的是:复用、解耦、保密、简化维护、加快编译、稳定可靠。库本质是把通用、稳定、独立的代码编译成二进制/静态文件,给多个项目直接调用,不用重复写源码,如相关驱动外设、通信协议栈、算法模块、安全/保密代码及中间件组件等,在跨平台或跨产品业务中将代码封装成库做的好处包括:
- 代码复用:一次编写,N 个项目使用
- 编译更快:库不参与每次编译,大型项目提速明显
- 降低耦合:底层和上层分离,架构更清晰
- 保护源码:核心算法 / 安全代码不泄露
- 稳定可靠:成熟代码封装后不易被破坏
- 团队协作:分工明确,底层开发 vs 业务开发
在代码封装成库时,往往选择将其封装为静态链接库(.a/.lib)或者动态链接库(.so/.dll),为了详细对比分析嵌入式开发中动态库与静态库的差异,接下来将从以下四个核心维度深入展开讨论,将以清晰的对比结构输出结论,重点结合嵌入式资源受限特性,阐述两者在实际开发与系统架构中的性能及维护优势:
1、内存与磁盘资源占用
1.1、内存与磁盘资源占用
静态库:编译时会将库的所有代码完整拷贝到每个可执行文件中。
动态库:只在可执行文件中记录引用地址,实际代码只存一份在系统中。
| 对比项 | 静态库 | 动态库 |
| 链接方式 | 编译时将代码完整复制到可执行文件中 | 运行时按需才加载到内存 |
| 可执行文件大小 | 包含完整库代码,体积大 | 仅包含符号引用,体积小 |
| 磁盘占用 | 每个应用独立加载库代码 | 多个应用共享同一份库文件 |
| 内存占用 | 每个进程独立加载完整代码,N 个进程 = N 份代码副本(线性增长) | 多进程共享同一份内存代码,N 个进程 ≈ 1 份物理代码 + N 个映射表 |
| 运行时内存 | 启动 10 个相同程序 → 代码段占用 10 倍内存 | 启动 10 个相同程序 → 代码段仅占 1 倍内存 |
这里简单举一个例子展示二进制资源的区别,假设有 3 个音频处理任务,都使用同一个音频算法库,IRAM对固件镜像和运行时内存占用都有影响:
| 静态库方案 | 动态库方案 |
|
Task1: [代码+Lib] ≈ 50KB IRAM + 10KB DRAM Task2: [代码+Lib] ≈ 50KB IRAM + 10KB DRAM Task3: [代码+Lib] ≈ 50KB IRAM + 10KB DRAM |
Task1: [代码] + [共享Lib] ≈ 20KB IRAM + 10KB DRAM Task2: [代码] + [共享Lib] ≈ 20KB IRAM + 10KB DRAM Task3: [代码] + [共享Lib] ≈ 20KB IRAM + 10KB DRAM |
| 总计:150KB IRAM + 30KB DRAM |
实际:60KB IRAM + 30KB DRAM(Lib代码共享) IRAM 节省:约 60% |
1.2、多进程共享机制
| 静态库模式:每个进程会独立加载一份 |
| 进程 A → [app_a + lib_code] → 内存:lib_code × 1 份(进程内) 进程 B → [app_b + lib_code] → 内存:lib_code × 1 份(进程内) 进程 C → [app_c + lib_code] → 内存:lib_code × 1 份(进程内) |
| 总内存 = 3 份 lib_code,占用 3 × Size(lib) |
| 动态库模式:多个进程/应用使用同一个动态库时,操作系统只需将库代码加载到内存一次,所有进程共享这一份代码: |
| 进程 A → [app_a] → 引用共享库 → 内存:PLT/GOT 表 + lib_code × 1 份(全局共享) 进程 B → [app_b] → 引用共享库 → 内存:PLT/GOT 表 + [共享同一份lib_code] 进程 C → [app_c] → 引用共享库 → 内存:PLT/GOT 表 + [共享同一份lib_code] |
| 总内存 ≈ 1 份 lib_code + 3 × 页表开销,节省约 66% 内存占用,(PLT/GOT 表:用于动态链接的跳转表) |
1.3、链接及引用地址
静态库链接方式:可执行文件中直接包含库的机器码,链接器会把静态库里被调用到的目标代码段、数据段完整拷贝,嵌入最终可执行文件内部。 程序运行时不再依赖外部库文件,函数调用写死真实内存地址,在代码中静态库调用情况如下:
|
main(): |
|
lib_porocess():库代码直接嵌入 // 实际处理逻辑 |
- 0x12345678:库函数编译后固定的物理偏移地址
- 链接完成后地址永久固化,运行时无需重定位、无需加载外部文件
动态库链接方式:使用引用地址即可执行文件中只记录符号引用,而不是实际的代码或数据地址,动态库调用不会写死真实地址,是通过PLT/GOT间接跳转,运行时才查找库函数地址,在代码中动态库调用情况如下:
PLT:过程链接表,存放跳转指令
GOT:全局偏移量表,存放实际地址
|
main(): CALL PLT[0] ← 调用 PLT 表中的跳转指令 |
|
|
PLT[0]: jmp *GOT[1] ← 跳转到 GOT 表中的地址 |
|
GOT 表(运行前): GOT[1] = 0x00000000 ← 引用地址(待填充) |
|
GOT 表(运行后): GOT[1] = 0x12345678 ← 实际地址(库lib_porocess加载后) |
静态库被调用的实际地址和动态库被调用的引用地址对比如下:
| 对比项 | 实际地址 | 引用地址 |
| 存储位置 | 运行时确定 | 可执行文件中 |
| 值 | 库函数的真实内存地址 | 初始为0或占位符 |
| 确定时机 | 程序启动时 | 编译/链接时 |
| 作用 | 实际执行时的跳转目标 | 标记需要解析的符号 |
虽然引用地址可以减少可执行文件的体积,但是动态库会引入一些额外开销:
| 开销类型 | 说明 |
| PLT/GOT 表 | 用于动态链接的跳转表,占用少量DRAM |
| 运行时链接 | 启动时解析符号的时间开销 |
| 库句柄 | 每个加载的库需要维护句柄信息 |
2、程序编译与更新灵活性
2.1、编译流程对比
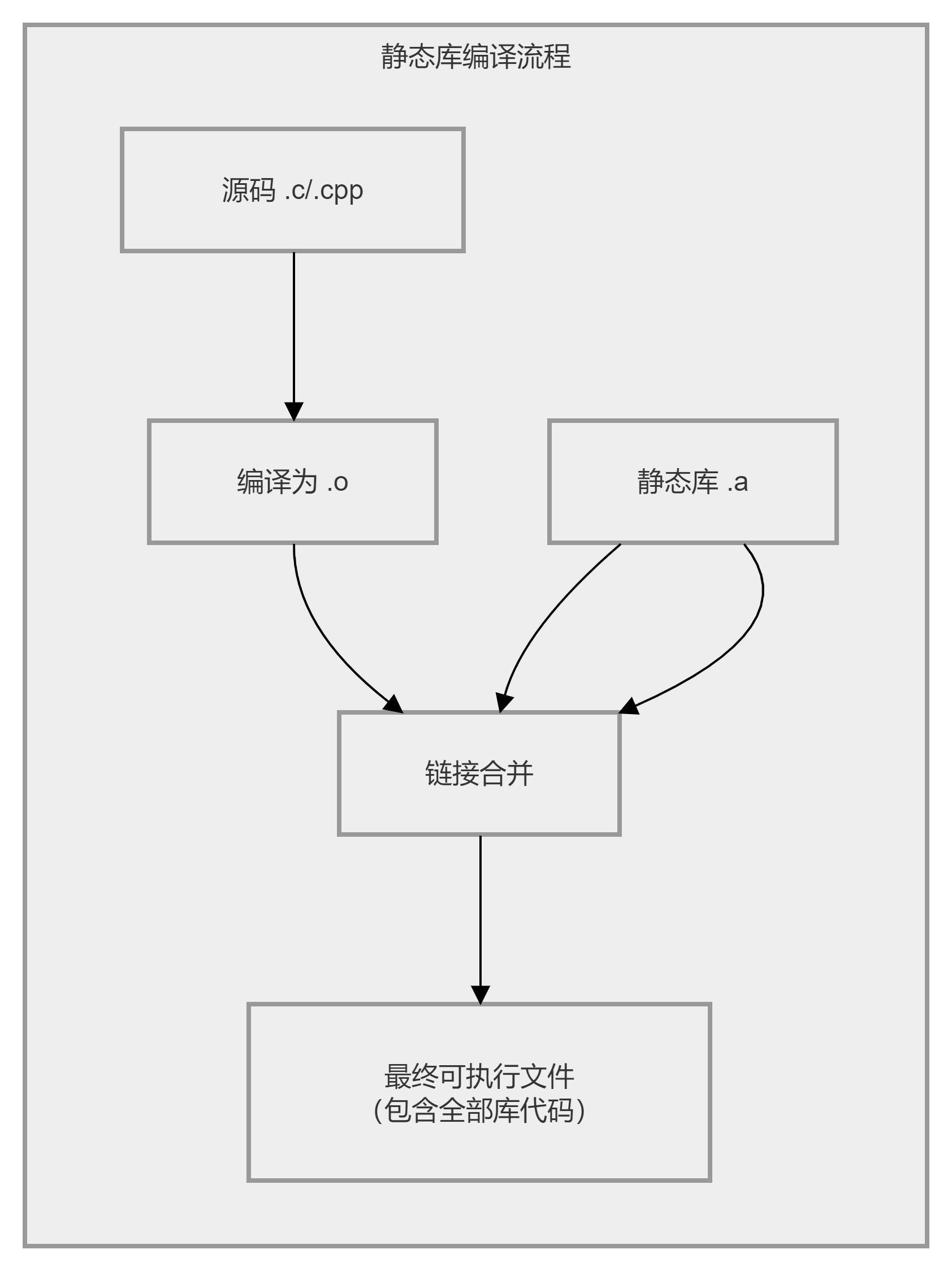
静态库编译流程:
源码修改 → 重新编译库 → 重新编译所有使用该库的应用 → 重新链接 → 发布
↑ ↑
└──────────── 牵一发而动全身 ───────────────────┘
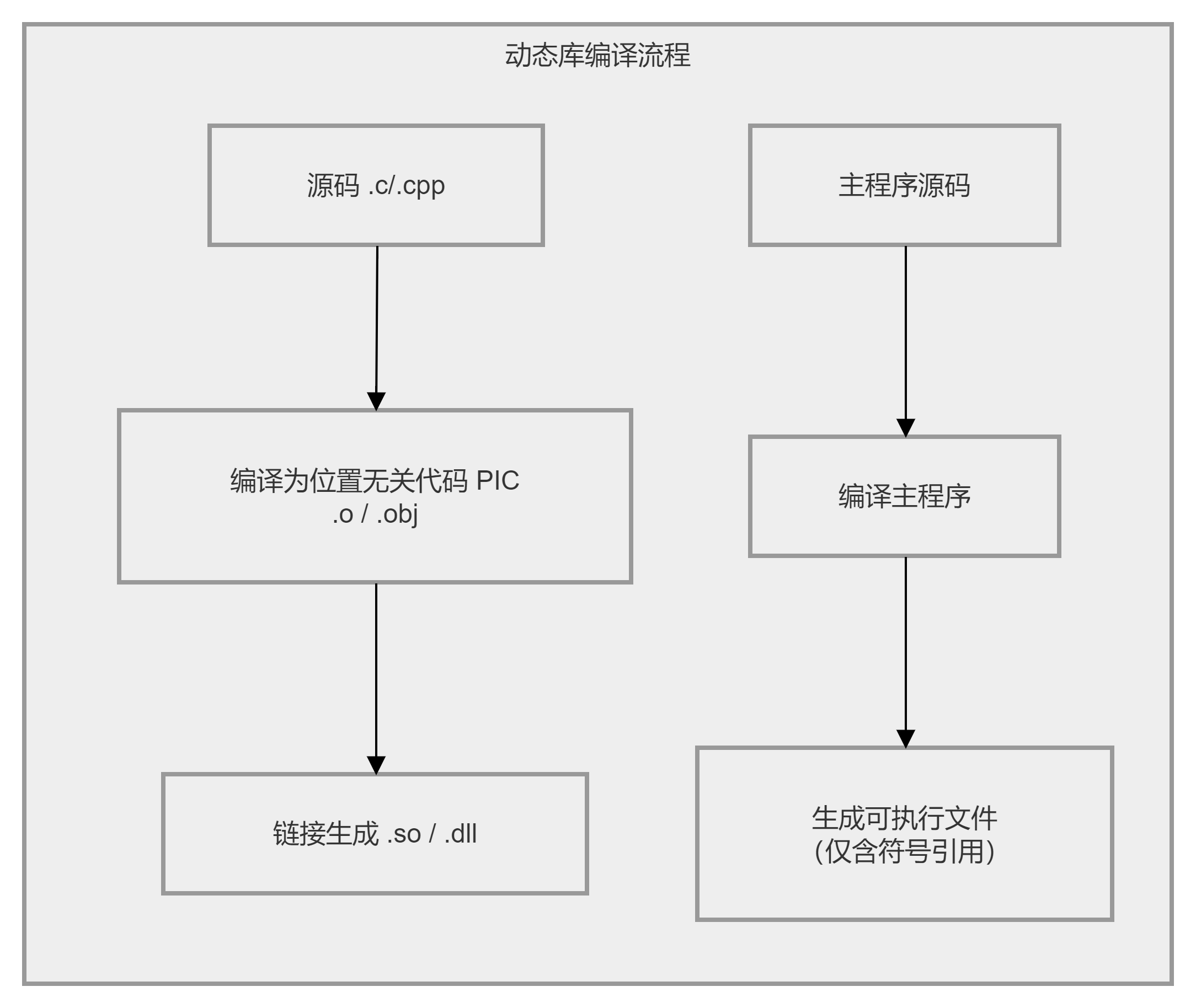
动态库编译流程:
库源码修改 → 单独编译库 → 发布新库文件 → 无需重新编译/链接应用
↑
主程序应用完全不受影响
2.2、更新机制对比
| 场景 | 静态库更新 | 动态库更新 |
| ABI兼容性 | 需维护 ABI 稳定,否则调用方需重新编译 | 无 ABI 约束(直接嵌入二进制) |
| 修复 Bug | 必须重新编译整个主程序并重新分发 | 只需替换 .so/.dll 文件,主程序零改动 |
| 功能增强 | 全量重新编译、测试、部署,影响所有依赖方 | 独立发布新版动态库,即插即用,模块独立演进 |
| 修复/HOTFIX | 用户需下载完整安装包 | 推送一个小补丁文件即可 |
| 版本管理难度 | 高(每次变更都产生新的二进制) | 低(语义化版本控制:major.minor.patch) |
| 回滚成本 | 需重新打包旧版本 | 替换回旧版 .so 即可 |
| 多 SKU 维护 | 每个 SKU 独立构建流水线,重复工作多 | 基础库只维护一份,差异模块独立构建发布 |
2.3、OTA应用场景
假设需要修复一款音频产品中的libaudio库中的一个音频bug:
| 静态库方案 | 动态库方案 |
|
1. 修改 audio.c 源码 5.全量回归测试 (因为二进制全变了) 7.用户端下载完整包并刷机 |
1. 修改 audio.c 源码 3.针对性测试 库修改功能即可 |
| 时间成本高,用户带宽成本高 | 时间成本低,用户带宽成本低 |
3、模块化与按需加载机制
3.1、加载机制对比
| 静态库加载模型 | 动态库加载模型 | |
| 编译链接阶段 |
ld -o app.elf app.o libaudio.a → 代码直接拷贝到 app.elf libcodec.a → 代码直接拷贝到 app.elf libnet.a → 代码直接拷贝到 app.elf |
app.elf 只包含符号引用和 PLT/GOT 表 libaudio.so 独立编译,符号未解析 |
| 程序启动阶段 |
加载 app.elf 到内存 [主程序 + audio + codec + net] 全部代码已存在 无论是否需要,全部占用内存 |
加载 app.elf 到内存(快速) libaudio.so 不加载 libcodec.so 不加载 libnet.so 不加载 运行时首次调用: 调用 audio_process() PLT 触发动态链接器 加载 libaudio.so 解析符号 执行函数 |
| 特点 |
启动时即完整可用 无论用不用,所有模块都加载 无法在运行时卸载不需要的模块 |
启动快速 按需加载 可卸载不需要的模块 内存峰值低 |
3.2、内存峰值
以支持多种音频场景模式的TWS耳机典型使用场景为例:
| 静态库方案 | 动态库方案 |
|
全部常驻: [主程序代码] 200KB [音频通话模块] 150KB ← 即使不用也占用 [音乐播放模块] 150KB ← 即使不用也占用 [语音识别模块] 150KB ← 即使不用也占用 [音效处理模块] 100KB ← 即使不用也占用 [通信传输模块] 100KB ← 即使不用也占用 |
场景:语音通话模式,按需加载: [主程序代码] 200KB [音频通话模块] 150KB ← 通话需要 [音乐播放模块] 卸载 ↓ ← 释放 150KB [语音识别模块] 卸载 ↓ ← 释放 150KB [音效处理模块] 100KB ← 通话需要 [通信传输模块] 100KB ← 通话需要 |
|
总占用:850KB 内存峰值:高 |
总占用:550KB ← 节省 35%! 内存峰值:低 |
3.3、系统启动速度
静态链接模式下,所有功能代码在系统启动时全部就位,动态库模式下采用 Lazy Loading,系统启动时只初始化核心模块。
启动时序对比:
静态库: [全部代码 XIP 映射] → [全部模块初始化] → 就绪 (T=500ms)
动态库: [核心框架 XIP 映射] → [核心模块初始化] → 就绪 (T=150ms)
↓ 用户切 ANC 时
[dl_open libanc.so] → 加载完成 (T=+20ms)
例如对于 TWS 耳机“开盖即听”的体验要求,启动时间从 500ms 缩短到 150ms 是质变。
3.4、对比总结
| 静态库 | 动态库 | |
| 模块独立性 | 编译时绑定,所有符号暴露在同一个链接命名空间,容易冲突 | 运行时绑定,各 .so 独立编译,符号可限制可见性,避免命名冲突 |
| 加载时机 | 程序启动时一次性全量加载 | 可选择启动时加载或运行时按需加载 (dlopen) |
| 延迟加载支持 | 不支持 | 支持 |
| 内存效率 | 低(全量常驻) | 高(按需分配) |
| 启动速度 | 慢(全量) | 快(按需) |
| 插件扩展 | 困难(需重新编译) | 容易(dlopen/dlclose) |
| 条件编译 | 大量 #ifdef 导致代码可读性差,测试覆盖不全 | 通过运行时配置决定加载哪些模块,减少 #ifdef 爆炸 |
4、部署与维护便捷性
从以下各个维度对比可以大致了解到静态库和动态库各自的部署和维护层面的优势:
| 维度 | 静态库 | 动态库 | 分析 |
| 部署文件数 | 1 (单文件部署) | N+1 (应用+库,需确保依赖链完整), | 静态库简单 |
| 依赖部署 | 无 | 需要部署库文件 | 动态库复杂 |
| 路径配置 | 无 | 需配置 LD_LIBRARY_PATH | 动态库需配置 |
| 升级粒度 | 全量 | 增量 | 动态库优势 |
| 回滚风险 | 全量回滚 | 可单独回滚库 | 动态库优势 |
| 环境一致性 | 依赖编译环境 | 依赖运行时环境 | 视场景而定 |
| 兼容性管理 | 无运行时依赖冲突,部署简单,但仍存在工具链导致的ABI不兼容,全局符号被不同的.a覆盖 | 需处理 DLL Hell / 版本冲突问题,ABI要求严格,接口不可随意变动 | 视场景而定 |
| CI/CD 效率 | 单固件二进制版本管理,流水线串行化 | 各模块独立版本号,独立流水线 | 动态库优势 |
| 安全性(逆向) | 较难分析 | 库文件可被独立分析 | 静态库优势 |
| 跨语言调用便利性 | 需重新编译 | 可直接供不同语言调用 | 动态库优势 |
| 产品合规认证 | 每次固件变更需全套重新认证 | 基础库不变时,只认证变更模块,节省认证成本 | 动态库优势 |
| 功能安全认证 | 执行路径完全固定,堆栈/内存布局可预测,符号表完整静态 | 延迟绑定导致执行路径在运行时才确定,符号解析失败、版本不匹配等错误在运行时才暴露 | 静态库优势 |
5、总结:嵌入式场景如何选型
可以根据不同的嵌入式设备类型灵活选择不同的库部署方案:
| 设备类型 | Flash/RAM资源 | OTA频率 | 推荐方案 | 核心理由 |
| TWS耳机/可穿戴 | 极紧张(MB级Flash) | 高(持续迭代功能) | 动态静态混合:核心协议栈静态链接,功能算法模块动态加载 |
模块级差分 OTA 包可缩小到 KB 级(vs 全量 MB 级),BLE 传输时间大大降低;按需加载可缩短关键启动路径 30-50% |
| 智能音箱/IoT网关 | 中等 | 中高 | 首选动态库 | 资源充裕可承担加载器开销;多进程/多服务天然受益代码共享;插件式技能/算法更新是刚需 |
| 车规MCU | 紧张但安全优先 | 极低(年/次) | 静态库(确定性 + 安全认证便利性) | 确定性执行、无动态加载器故障面;功能安全认证(对动态加载的验证成本极高) |
| 工业控制 | 紧张 | 极低 | 静态库 | 硬实时约束下 PIC 间接跳转和加载延迟不可接受;单次部署后很少变更 |
| 传感器节点/电池供电 | 极紧张 | 低 | 静态库(禁止动态加载器开销) | 加载器的开销占比过大;无 OTA 需求则动态库无优势 |
| Linux嵌入式 | 充裕 | 高 | 动态库全面采用 | MMU 提供天然进程隔离;动态库生态成熟;插件式功能扩展是产品核心架构 |
例如本博主参与开发的音频产品(智能耳机/音箱)恰好是动态库模式的最佳受益者:
- 功能模块明确:ANC、EQ、语音唤醒、本地音乐、空间音频——天然模块化边界;
- OTA 要求高:消费音频产品功能迭代频繁,差分 OTA 显著改善用户体验和升级成功率;
- 多 SKU 共存:同一 SDK 产出降噪款/基础款/游戏款等不同固件;
- 第三方算法集成:ANC 和音效算法通常由外部供应商提供,so动态库是必要前提;
- 多核架构适配:MCU + DSP共享代码段,动态链接直接解决多核代码冗余问题。
结论:在资源受限的嵌入式环境中,动态库直接对应现代软件架构对资源效率、模块解耦、热更新的三大核心诉求,其对于需要持续演进的中大型项目是一个效率较高的方案。而静态库则在安全敏感、极致性能场景中保持其不可替代性,更适合作为特定约束条件下的补充方案(如极简部署、安全隔离场景),因此在软件架构设计上可以考虑静态+动态混合部署:核心框架用动态库保证灵活性,第三方闭源库或极小工具可用静态库简化部署。
| 混合架构部署模型 | |
|
使用静态库:
|
使用动态库:
|
|
混合架构优势:
|
|
↓↓↓更多技术内容和书籍资料获取,入群技术交流敬请关注“明解嵌入式”↓↓↓

本文来自博客园,作者:Sharemaker,转载请注明原文链接:https://www.cnblogs.com/Sharemaker/p/20588393

 浙公网安备 33010602011771号
浙公网安备 33010602011771号