第十六届 蓝桥杯 2025 省B C++ 组 题解答案
第十六届 蓝桥杯 2025 省B C++ 组 题解
声明
-
个人题解,若与标算有偏差,以官方题解为主。
-
所有题目可以在 洛谷蓝桥杯同步题 提交。
-
部分题目描述图片来自洛谷。
A. 移动距离
题目描述

解题思路
-
注意到要上升 y轴 坐标只能通过第二种移动方式,在一个以 原点 为圆心的圆上移动到达。所以要到最后的定点(233,666)必然需要增大一个固定的角度(下图中的 \(alpha\) 角)。
-
由于圆周的长度为 \(alpah * r\) ,在角度固定的情况下,我们应选取 到原点 半径最小的圆,沿此圆的圆周移动所经过的距离便是最短的。
-
故我们先以 方式一 走到足以到达定点的位置,再以一次 方式二 到达目标点,此时经过的距离最短。
-
如图:
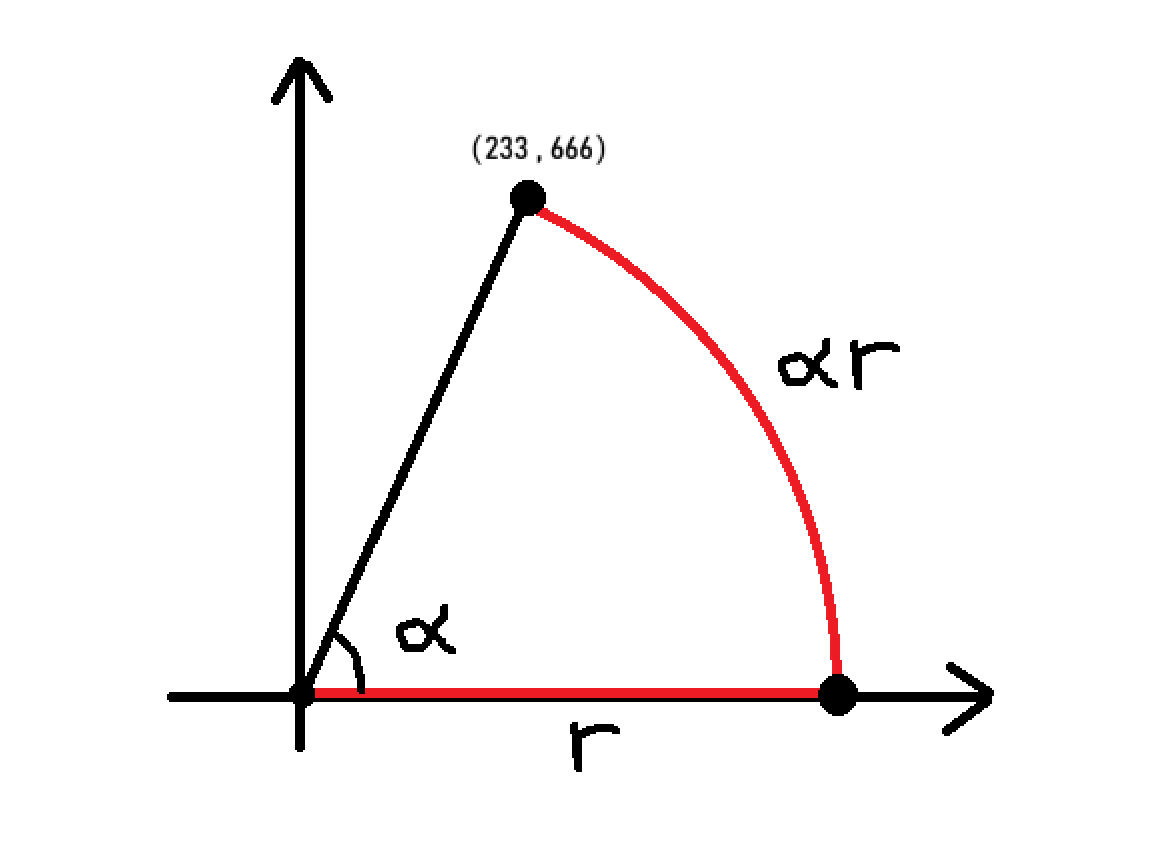
- 所以只需要求出 \(alpha\) 角和半径 \(r\),将两段相加即可。
- 我们可以用
math.h头文件中的atan()函数,即反正切函数求出角的弧度值;也可以用 excel 表格中自带的ATAN()反正切函数求角。 - 最后四舍五入一下即可。
完整代码
#include<iostream>
#include<math.h>
int main(){
double alpha = atan(666.0/233);
double r = sqrt(233*233+666*666);
double res = r + alpha*r;
printf("%.0lf",res);
return 0;
}
B. 客流量上限
题目描述

解题思路
思路一
-
也是赛时的思路。题目要求选取满足条件的排列个数,可以一般化为在: \([1,n]\) 这 n 个数字的所有排列中,满足任意两个数字 \(A_i*A_j\le i*j+n\)(注意这里一般化为 \(+n\))的排列个数。
那么题目的问题就是求当 \(n=2025\) 时的排列个数。
-
我们直接写一个暴力,求出当 n 较小时所有排列中满足条件的解的数量,然后找规律。
即对于 n 较小的情况,枚举出所有可能的排列,一个个检查是否满足题目要求。
暴力 DFS 找规律
#include<iostream>
using namespace std;
const int N = 2026,mod = 1e9+7;
int n,a[N],b[N]; bool vis[N];
inline bool check(){ // 检查当前排列是否合法
for(int i=1;i<=n;i++)
for(int j=1;j<=i;j++)
if(b[i]*b[j]>i*j+n) return false;
return true;
}
inline int dfs(int pos){
if(pos == n+1) return check();
int res = 0;
for(int i=1;i<=n;i++){ // 暴力枚举所有排列
if(!vis[i]){
vis[i] = true;
b[pos] = i;
res += dfs(pos+1);
vis[i] = false;
}
}
return res;
}
int main(){
for(int i=1;i<=20;i++){
n = i;
printf("i:%d %d\n",i,dfs(1));
}
return 0;
}
- 比赛时机房的电脑瞬间就跑完了,我们发现规律一目了然:
i:1 1
i:2 1
i:3 2
i:4 2
i:5 4
i:6 4
i:7 8
i:8 8
i:9 16
i:10 16
i:11 32
i:12 32
-
发现存在着 \(res = 2^{(n-1)/2}\)的直观规律,那么当 \(n=2025\) 时,我们只要求 \(2^{1012}\space\%\space mod\) 即可。
一定要记得题目要求取模呀。
完整代码
#include<iostream>
using namespace std;
int main(){
int n = 2025;
int b = (n-1)/2;
int res = 1;
for(int i=1;i<=b;i++) res = res*2%mod;
printf("%d",res);
return 0;
}
思路二
-
本题的正解。我们先看看每个位置在不考虑其他位置的取值的影响下,可能的取值有哪些。
-
由 \(i=j\) 时的限制,计算出取值 上界 \(a_i^2\le i^2+2025\),即对于每个位置 \(a_i^2-i^2\le 2025\) 。
那么我们由 \(1013^2-1012^2=2025\) 不难得出,当 \(i\ge 1013\) 时,若 \(a_i\gt i\),则 \(a_i^2-i^2\gt 2025\) 。
故我们得到了一个 上界 , \(a_i\le \begin{cases}\sqrt[]{i^2+2025}&i\lt1013\\i&i\ge 1013\end{cases}\)
-
再考虑每个位置与其他位置的取值的 最坏影响,即与 2025 相乘且 2025 在最后一个位置,此时该位置的取值的 下界 \(a_i*2025\le2025*i+2025\),即对于每个位置 \(a_i\le i+1\) 。
那么我们综合一下上下界,可以得到每个位置取值要满足的的 必要条件:
\(a_i\le\begin{cases}i+1&i\lt 1013\\i&i\ge 1013\end{cases}\)
-
不难发现 \(1013\) 算是本题的一个分界点,我们接下来分类讨论下 \(i,j\) 的取值,验证一下这个必要条件是否是充要条件,来决定是否还需要在某种情况下继续讨论。
当 \(i,j\lt 1013\) 时,\(a_i*a_j\le (i+1)*(j+1)\le i*j+(i+j)+1\le i*j+2025\),刚好满足限制条件。
当 \(i\lt 1013\),\(j\ge 1013\) 时,\(a_i*a_j\le (i+1)*j\le i*j+j\le i*j+2025\),也满足限制条件。
当 \(i,j\ge 1013\) 时,\(a_i*a_j\le i*j\le i*j+2025\),明显满足限制条件。
-
故我们讨论得到的就是 充要条件:\(a_i\le\begin{cases}i+1&i\lt 1013\\i&i\ge 1013\end{cases}\)
-
那么用 乘法原理 考虑最后的总排列数,从 1 到 2025 一个个填数。
1 到 1012 每个位置都在 \([1,i+1]\) 中选择,已经被前面选走了 \(i-1\) 个数字,还剩下 \(2\) 个数字共两种选法。
1013 到 2025 每个位置只能在 \([1,i]\) 中选择,已经被前面选走了 \(i-1\) 个数字,只剩下 \(1\) 个数字唯一选法。
-
故最后的排列总数为 \(2^{1012}*1^{1013}=2^{1012}\space %%\space mod\) 。
一定要记得题目要求取模呀。
C. 可分解的正整数
题目描述

输入格式
共两行。
-
第一行包含一个正整数 \(N\),表示数据的个数。
-
第二行包含 \(N\) 个正整数 \(A_1,A_2,…,A_N\),表示需要判断是否可分解的正整数序列。
输出格式
- 输出一行一个整数,表示给定数据中可分解的正整数的数量。
样例输入
3
3 6 15
样例输出
3
数据规模
- \(1\le N\le 10^5\),\(1\le A_i\le 10^9\)。
解题思路
思路一
-
打表找规律。题目问一个正整数是否可以被分解成 \(长度\ge 3\) 的连续 整数 之和,我们可以暴力枚举所有可能的 序列长度 和 序列结尾位置,判断一个数字是否可以被分解。
-
对于任意数字 \(x\) 分解出的序列 \([l,r]\) ,必有 \(l\ge -x\) 且 \(r\le x\),那么我们枚举这之间的所有序列即可。
-
注意枚举时区间长度需要大于等于 \(3\) 。
暴力找规律
#include<iostream>
using namespace std;
int n;
inline bool check(){
for(int r=n;r>=-n;r--){ // 区间右端点
for(int l = r;l>=-n;l--){ // 区间左端点
if(r-l+1 < 3) continue; // 长度需大于等于 3
int sum = 0;
for(int i=l;i<=r;i++) sum += i;
if(sum == n) return true;
}
}
return false;
}
int main(){
for(int i=1;i<=100;i++){
n = i;
printf("i:%d %s\n",i,check()?"Ture":"False");
}
return 0;
}
- 输出结果:
i:1 False
i:2 Ture
i:3 Ture
i:4 Ture
i:5 Ture
i:6 Ture
i:7 Ture
i:8 Ture
i:9 Ture
i:10 Ture
i:11 Ture
i:12 Ture
......
i:88 Ture
i:89 Ture
i:90 Ture
i:91 Ture
i:92 Ture
i:93 Ture
i:94 Ture
i:95 Ture
i:96 Ture
i:97 Ture
i:98 Ture
i:99 Ture
i:100 Ture
- 很容易发现,除了 \(1\) 以外的所有正整数都可以被分解。
- 所以我们只需要判断读入多少个非 \(1\) 的数字即可。
完整代码
#include<iostream>
using namespace std;
int main(){
int n; scanf("%d",&n);
int res = 0;
for(int i=1,x;i<=n;i++){
scanf("%d",&x);
if(x != 1) res ++;
}
printf("%d",res);
return 0;
}
思路二
-
本题的正解。由于序列中可以有负数,那么我们不难发现,对于每一个数字 x,都可以分解为以下序列:
\(x = x+(x-1)+(x-2)+...+2+1+0-1-2-...-(x-2)-(x-1)\)
这是显然正确的,所有的相反数相加和为 \(0\) 。
-
我们计算下这个序列的长度为 \((x-1)*2+1=2*x-1\),那么对于任意一个数字 \(x\ge 2\),分解为该序列就可以得到满足题目要求的 \(长度\ge 3\) 的连续整数序列了。
-
对于正整数 \(1\) 而言,只能被分解为 \(1+0\),长度只有 \(2\),所以除了 \(1\) 其他所有正整数都可以被分解。
D. 产值调整
题目描述

输入格式
输入的第一行包含一个整数 \(T\),表示测试用例的数量。
接下来的 \(T\) 行,每行包含四个整数 \(A,B,C,K\),分别表示金矿、银矿和铜矿的初始产值,以及需要执行的调整次数。
输出格式
对于每个测试用例,输出一行,包含三个整数,表示经过 \(K\) 次调整后金矿、银矿和铜矿的产值,用空格分隔。
样例输入
2
10 20 30 1
5 5 5 3
样例输出
25 20 15
5 5 5
数据规模
- \(1\le T\le 10^5\),\(1\le A,B,C,K\le 10^9\)。
解题思路
-
朴素想法直接模拟 \(K\) 次,发现数据量太大必然超时。
接着考虑用 矩阵快速幂 优化,发现每次迭代后都需要向下取整不是很好处理(
蓝桥杯考不到)。 -
那么我们尝试模拟几个数据,观察下迭代的过程中有没有规律:
0: 10 20 30
1: 25 20 15
2: 17 20 22
3: 21 19 19
4: 19 20 20
5: 20 19 19
6: 19 19 19
- 再模拟一组:
0: 3 30 300
1: 165 151 16
2: 83 90 158
3: 124 120 86
4: 103 105 122
5: 113 112 104
6: 108 108 112
7: 110 110 108
8: 109 109 110
9: 109 109 109
- 我们发现其实并不需要迭代很多次,最后三个数字都会相等,从而使剩余的 \(K\) 不需要继续模拟了。
- 赛时可以写一段代码算一下平均迭代次数,验证我们的猜想:
#include<iostream>
using namespace std;
int a,b,c,k;
inline int total(){
int sum = 0;
while(true){
int na = (b+c)/2, nb = (a+c)/2, nc = (a+b)/2;
if(na == a && nb == b && nc == c) break;
a = na, b = nb, c = nc;
sum += 1;
}
return sum;
}
int main(){
const int up = 1e9;
for(int T=1;T<=10;T++){
long long sum = 0;
for(int i=1;i<=1000;i++){
a = rand()%up+1,b = rand()%up+1,c = rand()%up+1,k = rand()%up+1;
sum += total();
}
printf("%lf\n",sum/1000.0);
}
return 0;
}
- 输出结果:
15.390000
15.409000
15.395000
15.421000
15.462000
15.377000
15.319000
15.454000
15.457000
15.385000
- 不难发现,测试了大量数据,平均每次只要迭代 \(15\) 次就可以使 \(3\) 个数字相等,所以我们只需要在暴力模拟的过程中,当 \(3\) 个数字相等的时候直接停止模拟即可。
完整代码
#include<iostream>
#define ll long long
using namespace std;
inline void solve(){
ll a,b,c,k; scanf("%lld%lld%lld%lld",&a,&b,&c,&k);
for(int i=1;i<=k;i++){
ll na = (b+c)/2, nb = (a+c)/2, nc = (a+b)/2;
if(na == a && nb == b && nc == c) break;
a = na, b = nb, c = nc;
}
printf("%lld %lld %lld\n",a,b,c);
}
int main(){
int T; scanf("%d",&T);
while(T--) solve();
return 0;
}
E. 画展布置
题目描述

输入格式
共两行。
- 第一行包含两个正整数 \(N\) 和 \(M\),分别表示画作的总数和需要挑选的画作数量。
- 第二行包含 \(N\) 个正整数 \(A_1,A_2,…,A_N\),表示每幅画作的艺术价值。
输出格式
输出一个整数,表示 \(L\) 的最小值。
数据规模
- \(2\le M\le N\le 10^5\),\(1\le A_i\le 10^5\)。
解题思路
-
由于数值 \(L\) 为相邻两个数字的平方之差的总和,那么对于某次取出的 \(M\) 个数,这 \(M\) 个数字的最小 \(L\) 值显然是在其有序时(从小到大 或 从大到小均可)取得。
从小到大排序时 \(L=\sum_{i=2}^{M}a_i^2-a_{i-1}^2=a_M^2-a_{M-1}^2+a_{M-1}^2-a_{M-2}^2+...+a_2^2-a_1^2=a_M^2-a_1^2\) 。
-
所以我们只需要先将 \(A_1,A_2,…,A_N\) 从小到大排序,随后找到 \(L\) 值最小的连续 \(M\) 个数。
-
只需要枚举每一个可能的连续 \(M\) 个数的起始下标 \(i\),此时 \(L\) 值即为 \(a_{i+M-1}^2-a_i^2\),取最小的 \(L\) 即可。
完整代码
#include<iostream>
#include<algorithm>
#define ll long long
using namespace std;
const int N = 1e5+5;
ll n,m,a[N];
int main(){
scanf("%lld%lld",&n,&m);
for(int i=1;i<=n;i++) scanf("%lld",&a[i]);
sort(a+1,a+1+n);
ll res = 0x7fffffffffffffff;
for(int i=1;i+m-1<=n;i++){
ll L = a[i+m-1]*a[i+m-1] - a[i]*a[i];
res = min(res,L);
}
printf("%lld",res);
return 0;
}
F. 水质检测
题目描述

输入格式
输入共两行,表示一个 \(2*n\) 的河床。
每行一个长度为 \(n\) 的字符串,仅包含 # 和 .,其中 # 表示已经存在的检测器,. 表示空白。
输出格式
输出共 \(1\) 行,一个整数表示答案。
样例输入
.##.....#
.#.#.#...
样例输出
5
数据规模
- \(n\le 10^6\)。
解题思路
-
我们从左往右一列一列地观察数据。先删去所有空列,发现某列是否需要补检测器只和上一列有关。
只有当上一列和本列都只有一个,且两列错开时才要补充。若上一列有 \(2\) 个则本列一定不要补充。
##..#
#.##.
-
那么如果需要补充,肯定是补充在本列,使本列变成有 \(2\) 个的情况,显然比补充在前一列更优。
-
根据这个贪心思想,我们可以补充完这张图使其连通:
###.#
#.###
- 再考虑之前删掉的空列:
.###.#..#
.#.#.#..#
-
不难发现,除了开头和结尾的空列,中间空了几列就要补充几个检测器,至此解决问题。
-
那么我们可以将两步合在一起做:记录下上一次非空列的状态,比如 \(0\) 表示
##,\(1\) 表示#.,\(2\) 表示.#。从左往右扫描,统计两列间空了多少列,直接计入答案需要补充。
对于两个非空列,只有当他们错开了,本列需要补充一个,变成
##。 -
这样从左往右贪心一遍,即为答案。
完整代码
#include<iostream>
using namespace std;
string str[2];
int main(){
cin >> str[0] >> str[1];
int n = str[0].size(),p = 0;
// 找到第一个非空列
while(p < n && str[0][p] == '.' && str[1][p] == '.') p++;
// 0: ## 1: #. 2: .#
int last = (str[0][p] == '.') ? 2 : ((str[1][p] == '.') ? 1 : 0);
int res = 0;
for(p++;p < n;p++){
int cnt = 0; // 统计空列个数
// 找到下一个非空列
while(p < n && str[0][p] == '.' && str[1][p] == '.') p++,cnt++;
if(p == n) break;
res += cnt;
int cur = (str[0][p] == '.') ? 2 : ((str[1][p] == '.') ? 1 : 0);
if(cur && last && cur+last==3){ // 两个非空列错开了
res ++;
last = 0; // 补充成 ##
}else last = cur;
}
printf("%d",res);
return 0;
}
G. 生产车间
题目描述

输入格式
输入共 \(n+1\) 行。
-
第一行为一个正整数 \(n\)。
-
第二行为 \(n\) 个由空格分开的正整数 \(w_1,w_2,…,w_n\)。
-
后面 \(n−1\) 行,每行两个整数表示树上的一条边连接的两个结点。
输出格式
输出共一行,一个整数代表答案。
输入样例
9
9 7 3 7 1 6 2 2 7
1 2
1 3
2 4
2 5
2 6
6 7
6 8
6 9
输出样例
8
数据规模
- \(2\le n,w_i\le 10^3\)
解题思路
-
我们发现数据量很小,对于每个节点可以直接用一个
bool数组could[]记录:该节点及其子树中,哪些 \(\le w_i\) 的单位的成品可以被拼凑出来。比如叶节点 \(u\) 的 \(w_u=2\),则
could[u][0] = could[u][2] = true表示该节点可以凑出单位为 \(0\) 的成品或单位为2的成品。即删了该叶节点和不删该叶节点。比如某个结点连着 \(3\) 个叶节点,\(w_i\) 分别为 \(1,3,5\),本节点 \(w_u=7\),则本节点的
could[u]数组应为:could[u][0] = true could[u][1] = true could[u][3] = true could[u][5] = true could[u][4] = true could[u][6] = true could[u][2] = false could[u][7] = false因为该节点 \(3\) 个孩子都删了单位为 \(0\),也可以删其中某一个,或某两个,或者都不删。
需要注意的是,若三个孩子都不删或者只删 \(w=1\) 的孩子时,拼凑出的单位分别为 \(9\) 和 \(8\),大于本节点的 \(w_u=7\),根据题目所述是应该被舍弃的情况,我们需要直接忽略不改为
true。 -
那么思路就很清晰了,首先初始化每个节点都可以拼出
0单位的成品 -
然后我们沿着树的结构从根节点开始往叶节点 \(DFS\),
叶节点直接设置
could[u][0] = could[u][w_u] = true对于某个非叶节点,每处理完一个孩子,就用该孩子的所有可拼凑出的单位的信息,来更新本节点可以拼凑出的所有单位的成品信息。
-
需要注意的是,这里对于父节点
could[]数组中的每一项,我们都需要遍历一遍孩子的could[]数组,时间复杂度为 \(O(w^2)\),其中 \(w\) 为节点的权值大小。那么一整棵树共 \(n\) 各节点复杂度为 \(O(nw^2)\)。题目的数据 \(n\) 和 \(w\) 都是 \(10^3\),总复杂度为 \(10^9\) 很危险,我们遍历的时候建议稍稍优化一下,对于子节点当前取值
could[v][i] = true时,父节点只需要遍历 \([0,w[u]-i]\) 即可,总复杂度为 \(O(\frac{1}{2}nw^2)\)。 -
最后只需要在根节点的
could[]数组内,从高到低找到最大的可以被拼凑出来的单位的成品即可。 -
本质就是暴力对每个节点跑一遍 01背包。
完整代码
#include<iostream>
using namespace std;
const int N = 1e3+5,M = N<<1;
int n,ha[N],idx,val[N],out[N];
struct Edge{int from,to,ne;}edge[M]; // 链式前向星建图
inline void ins(int u,int v){
edge[++idx].from = u, edge[idx].to = v;
out[u]++; // 每个节点的出度
edge[idx].ne = ha[u],ha[u] = idx;
}
bool could[N][N],tmp[N][N];
void dfs(int u,int par){
if(out[u] == 1 && par){ // 叶节点
could[u][val[u]] = true;
return ;
}
for(int i=ha[u];i;i=edge[i].ne){
int v = edge[i].to;
if(v == par) continue;
dfs(v,u);
for(int ii=1;ii<=val[u];ii++) tmp[u][ii] = false; // 记录该孩子带来的影响
for(int ii=1;ii<=val[u];ii++) // 孩子 ii 单位,父节点 jj 单位,拼出 ii+jj 单位
for(int jj=0,up = val[u]-ii;jj<=up;jj++)
if(could[v][ii] && could[u][jj]) tmp[u][ii+jj] = true;
for(int ii=1;ii<=val[u];ii++) could[u][ii] |= tmp[u][ii]; // 合并该影响
}
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++) could[i][0] = true;
for(int i=1;i<=n;i++) scanf("%d",&val[i]);
for(int i=1,u,v;i<n;i++) scanf("%d%d",&u,&v),ins(u,v),ins(v,u);
dfs(1,0);
for(int i=val[1];~i;i--) // 最后输出根节点的最大可能值
if(could[1][i]){
printf("%d",i);
break;
}
return 0;
}
H. 装修报价
题目描述

输入格式
- 第一行输入一个整数 \(N\),表示装修相关费用的项数。
- 第二行输入 个非负整数 ,表示各项费用。
输出格式
输出一个整数,表示所有可能的总和对 \(10^9+7\) 取余后的结果。
输入样例
3
0 2 5
输出样例
11
样例说明

数据规模
- \(1\le N\le 10^5\),\(0\le A_i\le 10^9\)。
解题思路
-
数据规模很大,需要要计算所有可能的结果的总和,肯定不能暴力枚举统计。
我们需要弄明白每个数字对于最后的结果会贡献多少答案,这样对每个数字只需要算一次即可。
-
除了最后一个数字,每个数字后方都可以放三种操作符,由于题目明确了 异或 运算的优先级比 加法和减法 都高。所以如果该数字后放的是 加法或减法 操作符,可以将后面的所有操作用一个括号括起来,那么一加一减抵消了,只剩下该数字及前面的操作。
\(x\space⊕\space\space...\)
\(x\space+\space(\space□\space)\)
\(x\space-\space(\space□\space)\)
-
关键的是,该数字前面的操作只需要考虑 异或,因为如果前面的操作有 加法或减法,就会存在另外相反的操作抵消了,并不需要考虑。
\(...\space ⊕\space x\space ⊕\space\space...\)
\(...\space + (\space x\space+\space(\space□\space )\space )\)
\(...\space + (\space x\space-\space(\space□\space)\space )\)
\(...\space - (\space x\space+\space(\space□\space)\space )\)
\(...\space - (\space x\space-\space(\space□\space)\space )\)
-
所以总共 \(n\) 个数共 \(n-1\) 个操作符,第 \(1\) 个数字根据乘法原理,身后的 加和减 共两种可能,剩下的所有 \(n-2\) 个操作符可以任取各 \(3\) 种可能,\(a_1\) 总共需要被统计 \(2*3^{n-2}\) 次。
第 \(2\) 个数字时,身后的 加和减 \(2\) 种可能,剩下 \(n-1\) 个操作符任取各 \(3\) 种可能,则 \(a_1⊕a_2\) 总共需要被统计 \(2*3^{n-3}\) 次。
-
则除了最后一个数字,第 \(i\lt n\) 个数字,\(a_1⊕a_2⊕\space...\space⊕a_i\) 需要被统计 \(2*3^{n-i-1}\) 次。
-
对于最后一个数字,身后不能放任何运算符了,他唯一需要考虑的情况是:前方所有操作符都是异或。
额外加上 \(a_1⊕a_2⊕\space ...\space⊕a_{n-1}⊕a_n\) 即可。
-
我们可以预处理算出所有 \(3\) 的次幂,然后
for一遍即可算出所有贡献。 -
记得每一步都要取模。
完整代码
#include<iostream>
#define ll long long
using namespace std;
const int N = 1e5+5,mod = 1e9+7;
ll n,a[N],pow3[N];
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
pow3[0] = 1; // 预处理 3 的次幂
for(int i=1;i<=n;i++) pow3[i] = pow3[i-1]*3%mod;
ll eor = 0, res = 0; // eor 记录从 a[1] 一直异或到 a[i]
for(int i=1;i<=n-1;i++){
eor ^= a[i];
res = (res + (2*pow3[n-i-1]%mod)*eor%mod)%mod; // 每步都要取模
}
res = (res + (eor^a[n]))%mod; // 最后一个数字
printf("%lld",res);
return 0;
}
完结撒花
- 还是比较套路化的,暴力打表找规律使得思考量并不大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号