MySql基础笔记(一)Mysql快速入门
Mysql快速入门
一)基本概念
1)表
行被称为记录,是组织数据的单位。列被称为字段,每一列表示记录的一个属性。
2)主键
主键用于唯一的标识表中的每一条记录。可以定义表中的一列或者多列为主键,
但每张表中主键只能有一个,主键列上不能有两行相同的值,也不能为空值。
二)数据库基本操作
1)从命令行登陆mysql:
mysql -h hostName -u loginName -p
2)查看当前所有数据库:
shwo databases;
3)创建数据库:
create database tang charset utf8;
4)选择数据库:
use tang;
5)查看数据库定义:
show create database tang;
6)删除数据库:
drop database tang;
7)查看数据库支持的引擎类型:
show engins;
三)数据库表基本操作
1.创建与查看
1)查看现有表:
show tables;
2)创建表:
create table user ( id int primary key auto_increment, name varchar(88) );
使用主键约束:
字段名 数据类型 PRIMARY KEY [默认值]
也可在定义完所有列后指定:
PRIMARY KEY[字段名]
多字段组成联合主键:
create table user( -> id varchar(88), -> name varchar(88), -> age int, -> primary key (id,name) -> );
3)外键约束:
一个表可以有一个或者多个外键,一个表的外键可以为空值,若不为空值
则每一个外键必须等于另个一表中主键的某个值。外键不可以是本表的主键。
外键约束不能跨引起使用。
主表:主键所在的那个表。
从表:外键所在的表。
mysql> create table dept ( -> dept_id int auto_increment, -> dept_name varchar(66), -> primary key (dept_id) -> );
mysql> create table person ( -> id int auto_increment, -> name varchar(88), -> dept_id int, -> primary key (id) -> );
mysql> alter table person add constraint fk_test foreign key (dept_id) references dept (dept_id);
4)非空约束
字段名 数据类型 not null,
5)唯一性约束
语法:
字段名 数据类型 UNIQUE
唯一性约束要求该列唯一,允许为空,但只能出现一个空值。唯一约束可以确保一列或者几列不出现重复值。一个表中可以有多个UNIQUE。与主键区别:主键列不允许有空列。
6)默认约束
字段名 数据类型 DEFAULT 默认值
mysql> create table user ( -> id int primary key default 1, -> name varchar(88) unique, -> age int -> );
7)设置表的属性值自动增长
AUTO INCREMENT的初始值为1,一个表中只能有一个字段使用AUTO INCREMENT约束,且该字段必须为主键的一部分。
字段名 数据类型 AUTO INCREMENT
8)查看表的数据结构:
DESC 表名
2.修改与删除数据库表
1)修改表名
alter table user rename new_user;
2)修改字段的数据类型
alter table user modify age varchar(22);
3)修改字段名
alter table user change age how_Old int;
4)添加字段
Alter table 表名 add 新字段名 数据类型 约束条件 [first|after 已存在字段名];
5)删除字段
Alter table 表名 drop 字段名
6)修改字段的排列位置
Alter table 表名 modify 字段1 数据类型 first|after 字段2;
7)更改表的存储引擎
Alter table 表名 engine=更改后的存储引擎名
8)删除外键约束
Alter table 表名 drop foreign key 外键约束名
9)删除表
mysql> drop table if exists user;
四)数据类型
1.整数类型
tinyint ---------- 1字节
smallint ------------ 2字节
mediumint---------- 3字节
int ------------ 4字节
bigint ------------- 8字节
2.小数
1)浮点数:float和double
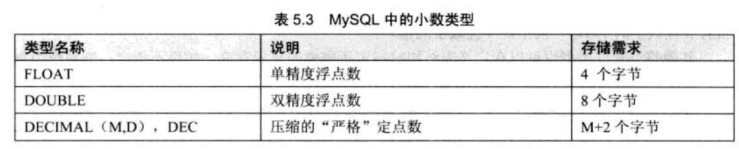
定点类型:DECIMAL
浮点类型和定点类型都可以用(M,N)来表示,其中M为精度表示总共的位数;N为标度
表示小数的位数。DECIMAL实际是以字符串存放的,DECIMAL可能的最大取值范围与DOUBLE一样,
但是其有效的取值范围由M和D的值决定,如果改变M固定D,则其取值范围将随M的变大而变大。
不论是定点还是浮点类型,如果用户指定的精度超出精度范围,四舍五入。但定点数在四舍五入时会给出警告。
3.日期与时间
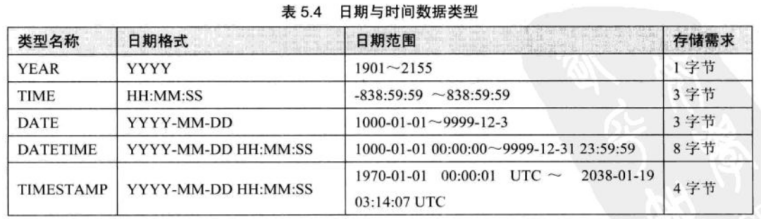
1)YEAR
1.用4位字符串或者4位数字表示,范围:1901~2155. 输入格式为:’YYYY’ 或者YYYY
2.以2位字符串表示YEAR,范围为00到99。插入‘00’~‘69’,则相当于插入2000~2069;如果插入‘70’~‘99’,则相当于插入1970~1999。第二种情况下插入的如果是‘0’,则与插入‘00’效果相同,都是表示2000年。
3.以2位数字表示YEAR。这里0值被转换为0000,其他同上。
2)TIME
1.’D HH:MM:SS’格式字符串。非严格语法:‘HH:MM:SS’、‘D HH:MM’‘D HH’或者‘SS’这里D表示日,可以取0~34之间的值。在插入数据库时,D被转换为小时保存,格式为“D*24+HH”。
2.‘HHMMSS’格式的、没有间隔的字符串或者HHMMSS格式的数值。如‘101112’被理解为‘10:11:12’,但109712是不合法的。
当TIME中使用冒号时被解释为当天的时间,不使用时解释为过去的时间。如‘1112’被解释为00:11:12即11分12秒。‘11:12’则被解释为11:12:00。超出范围但合法的值被转换为范围最接近的端点。非法值被转换为00:00:00.
插入现在时间:insert into tmp4 values(CURRENT_TIME),(NOW());
3)DATE类型
在给DATE类型的字段赋值时,可以使用字符串类型或者数字类型的数据插入,只要符合其格式。
1)‘YYYY-MM-DD’或者‘YYYYMMDD’字符串格式表示日期。
2)‘YY-MM-DD’或者‘YYMMDD’字符串表示,这里的YY表示两位的年值。MySQL使用以下规则解释两位的年值:‘00~69’为‘2000~2069’;‘70~99’为‘1970~1999’。
3)以YY-MM-DD或者YYMMDD数字格式表示日期,与前面类似。
MySQL允许不严格语法:@ . / 都可以做分隔符号。
4)DATETIME
1.‘YYYY-MM-DD HH:MM:SS’或者‘YYYYMMDDHHMMSS’
2.‘YY-MM-DD HH:MM:SS’或者‘YYMMDDHHMMSS’
3.YYYYMMDDHHMMSS或者YYMMDDHHMMSS
5)TIMESTAMP
显示格式与DATETIME相同,显示宽度固定在19个字符。UTC(Coordinated Universal Time,为世界标准时间)TIMESTAMP值的存储是以UTC格式保存的,存储时对当前时区进行转换,检索时再转换为当前时区,即查询时,根据当前时区不同,显示不同。
4.字符串类型

VARCHAR和TEXT类型是变长类型。例如VARCHAR(10)字段能保存最大长度为10个字符的字符串,
实际的存储需求是字符串的长度L,加上1个字节以记录字符串的长度。尾部空格不删除。
CHAR(M)为固定长度字符串,不够空格补,当检索CHAR的值时,尾部的空格将被删除。
ENUM类型创建语法:字段名 ENUM(‘值1’,‘值2’,......)ENUM类型的字段在取值时,只能在指定的枚举列表中取,
而且一次只能取一个值。如果创建的成员中有空格,其尾部的空格将自动被删除。ENUM值在内部用整数表示,
每个枚举值均有一个索引值,列表值所允许的成员值从1开始编号,MySQL存储的就是这个索引编号。
SET类型是一个字符串对象,可以有零个或多个值,其值为表创建时规定的一列值。语法格式为:字段 SET(‘值1’,‘值2’,......)
与ENUM不同的是SET类型的字段可从定义的列值中选择多个字符的联合。

五)运算符
1)算术运算符:+,-,*,/,%
2)比较运算符:比较运算符的结果总是1、0或者NULL。
|
运算符 |
作用 |
|
= |
等于(类型自动换,比NULL时返回NULL) |
|
<=> |
安全等于(可比较NULL) |
|
<>或者!> |
不等于 |
|
<= |
|
|
>= |
|
|
< |
|
|
> |
|
|
IS NULL |
|
|
IS NOT NULL |
|
|
LEAST |
有两个或多个参数时,返回最小值 |
|
GREATEST |
有两个或多个参数时,返回最大值 |
|
BETWEEN AND |
判断一个值是否在两个值之间 |
|
ISNULL |
同IS NULL |
|
IN |
判断一个值是IN列表中的任意一个 |
|
NOT IN |
|
|
LIKE |
通配符匹配 |
|
REGEXP |
正则表达式匹配 |
部分语法格式:3 BETWEEN 2 AND 4, LEAST(2,4,3) 3 IN(2,4,5)
expr LIKE 匹配条件 可以使用的通配符为:“%”匹配任何数目字符,甚至包括零字符。“_”只能匹配一个字符。
1)逻辑运算符
|
运算符 |
作用 |
|
NOT或者! |
逻辑非 |
|
AND或者&& |
逻辑与 |
|
OR或者|| |
逻辑或 |
|
XOR |
逻辑异或 |
XOR:当任意一个操作数为NULL时,返回NULL。对于非NULL:两个值一样为0或非0,返回0,不一样返回1
六)Mysql函数
略
七)查询数据
1.基本查询语句
语法:
select 属性列表
from 表名和视图名
[where 条件表达式]
[group by 属性名 [having 条件表达式] ]
[group by 属性名 [asc desc] ]
1)单表查询
1.查询部分字段:“,”
2.查询全部字段:“*”
3.查询经过计算的值:如:
select sno,sname,year(now())-sage sbir from student; 其中sbir为别名。
4.清除取值重复的行:
select distinct sdpt from student;
5.查询表中满足条件的记录:
select sno,sname ssex from student where sage between 20 and 22;
6.多重查询条件:
select*from sc where cno=1 and grade>80;
7.使用ORDER BY对查询结果进行升序(ASC)或者降序(DESC)的排序,默认为升序。如:
select sno,sname,sage from student order by sage desc;
8.统计函数和记录查询:
|
函数 |
说明 |
|
AVG([DISTINCT]<列名>) |
返回某列平均值 |
|
COUNT([DISTINCT]*) |
返回记录的行数 |
|
COUNG(DISTINCT<列名>) |
返回列中的某个值 |
|
MAX([DISTINCT]<列名>) |
返回某列最大值 |
|
MIN([DISTINCT]<列名>) |
返回某列的最小值 |
|
SUM([DISTINCT]<列名>) |
返回某列和 |
2.group by 子句
使用GROUP BY 将查询结果根据某一列的值进行分组,值相等的为一组。
1)单字段分组
select sdpt,count(*) count_num from student group by sdpt;
该查询结果根据sdpt的值进行分组,sdpt值相同的为一组,分为三组,然后对每一组进行行数统计,得到每一组的人数。
2)多字段分组
select ssex,sage,count(*) from student group by ssex,sage;
3)GROUP BY与HAVING子句一起使用
如果查询结果只想输出满足某种指定条件的组,要使用HAVING子句对组进行筛选,得到符合条件的信息。
select sno,avg(grade) from sc group by sno having avg(grade)>70;
4)GROUP BY与GROUP_CONCAT()函数一起使用
GROUP_CONCAT()函数返回一个字符串结果,该结果由分组中的值链接组合而成。
5)GROUP BY 子句使用ROLLUP
select sno,max(grade),min(grade) from sc group by sno with rollup;
ROLLUP和ORDER BY子句互斥,即不能同时使用。
3.limit限制结果数量
语法如下:
LIMIT [offset] , rows
Offset:偏移量 rows:行数 偏移量初始值为0
select * from student limit 1,3;
4.链接查询
涉及两个及其以上的表的查询为链接查询。链接查询要求参加链接的表必须要是有相同意义的字段。
1)内连查询:
使用比较运算符进行表间某些列数据的比较操作,并列出这些表中与链接条件相匹配的数据组合成新的纪录。
mysql> select * from student;
+----+------+-----+-------+------+---------+
| id | name | sex | class | math | english |
+----+------+-----+-------+------+---------+
| 1 | 张三 | 男 | 班级1 | 90 | 91 |
| 2 | 李四 | 男 | 班级2 | 88 | 86 |
| 3 | 王五 | 女 | 班级3 | 92 | 88 |
| 4 | 赵六 | 女 | 班级1 | 79 | 80 |
| 5 | 孙七 | 女 | 班级2 | 91 | 96 |
| 6 | 李八 | 男 | 班级3 | 90 | 89 |
+----+------+-----+-------+------+---------+
mysql> select * from teacher;
+----+--------+-------+
| id | name | class |
+----+--------+-------+
| 1 | 张老师 | 班级1 |
| 2 | 李老师 | 班级2 |
| 3 | 王老师 | 班级3 |
+----+--------+-------+
mysql> select student.name,student.class,teacher.name from student,teacher where student.class = teacher.class;
使用内联的查询方式:
mysql> select student.name,student.class,teacher.name from student inner join teacher on student.class = teacher.class;
在一个连接查询中,如果涉及到的两个表都是同一个表,这种查询称为字连接查询。
字连接查询是一种特殊的内链接,他是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表
mysql> select distinct s1.id,s1.name from student as s1,student as s2 where s1.class = s2.class and s2.class = '班级1';
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 4 | 赵六 |
+----+------+
2)外联查询
1.left join:左表中所有记录和右表中满足链接条件的记录信息。
2.right join:.....
select s.sno,sname,cno,grade from student s left join sc on s.sno=sc.sno;
5.子查询
子查询是指将一个查询语句嵌套在另一个查询语句中。
1)带any,some,all操作符的子查询。
select * from user where age>=all(select age from user);
2)in 和not in子查询
select * from user where age in (select age from user);
3)EXISTS和NOT EXISTS子查询
这两个操作符根据子查询是否返回数据来判断真假。
6.合并查询结果
SELECT......
UNION[ALL | DISTINCT]
SELECT......
UNION[ALL | DISTINCT]
SELECT......
UNION.....
八)插入、更新与删除数据
1.插入数据
1)
INSERT INTO table_name(colum_list)
VALUES(values_list1),(value_list2)......;
可以不指定colum_list直接插入,此时顺序必须与创建时相同。
2)将查询结果插入到表中
INSERT INTO table_name1 (column_list1)
SELECT (colum_list2) FROM table_name2 WHERE (condition);
2.更新数据
基本语法结构:
UPDATE table_name
SET column_name1=value1,colum_name2=value2,......column_namen=valuen
WHRER (condition);
3.删除数据
基本语法格式:
DELETE FROM table_name WHERE (condition);
九)索引
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。索引大大提高了查询速度,同时却会降低更新表的速度,
如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
1.索引的分类
1)普通索引:允许在定义索引的列插入重复值和空值。
2)唯一索引:索引值必须为唯一,但允许有空值。如果是组合索引,则列值组合必须唯一。
3)单列索引:一个索引只包含单个列,一个表可以有多个单列索引。
4)组合索引:在表的多个字段组合上创建的索引,只有在查询条件是使用了这些字段的左边字段时,索引才会被使用。
5)全文索引:允许列种插入重复值和空值,在定义索引的列上支持值的全文查找。全文索引可以在CHAR、VACHAR、TEXT类型的列上创建。MySQL中只有MyISAM支持全文索引。
6)空间索引:对空间数据类型(GEOMETRY,POINT,LINSTRING,POLYGON)创建的索引,其列必须声明为NOT NULL
2.创建索引
1)使用alter table语句创建索引:
ALTER TABLE可用于创建普通索引、UNIQUE索引和PRIMARY KEY索引3种索引格式,table_name是要增加索引的表名,
column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,
MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以同时创建多个索引。
ALTER TABLE 表名 ADD 索引类型 (unique,primary key,fulltext,index)[索引名](字段名)
//普通索引 alter table table_name add index index_name (column_list) ; //唯一索引 alter table table_name add unique (column_list) ; //主键索引 alter table table_name add primary key (column_list) ;
2)create index 语句创建索引
CREATE INDEX index_name ON table_name(username(length));
//只能添加这两种索引; CREATE INDEX index_name ON table_name (column_list) CREATE UNIQUE INDEX index_name ON table_name (column_list)
table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。
另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
3.删除索引
drop index index_name on table_name ; alter table table_name drop index index_name ; alter table table_name drop primary key ;
十)存储过程和函数
暂略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号