词嵌入方法 Word Embedding
Word Meaning
- 目前最常见的方法:用分类资源来处理词义。例如wordnet。
- NLTK(Natural Language Toolkit)自然语言处理工具包是用于自然语言处理的主要python包。
引用NLTK导入wordnet的代码
from nltk.corpus import wordnet as wn #corpus:语料库
panda = wn.synset('panda.n.01') #synset:同义词集合。第一部分是词义,第二部分是词性,第三部分是编号
hyper = lambda s: s.hypernyms() #hypernyms:上位词
list panda.closure(hyper)
关于hyper = lambda s:s.hypernyms()
- lambda:匿名函数。
- :前的是传入的形参。
- 相当于定义一个匿名函数,传入形参s,返回s.hypernyms(),赋值给hyper。
wordnet的缺点
- 容易遗漏词义之间的细微差别。
- 会忽略新词(不可能持续更新)。
- 判断同义词比较主观。
- 需要人力去维护。
- 很难对词汇的相似性给出准确的定义。例如:有人会认为proficient这个词比good更加接近专家(expert)。在wordnet中无法找到这样的差别。
词嵌入方法
One-Hot 独热编码
- 利用一个$R^{|V|×1}$向量来表示单词,$|V|$是词汇表中单词的数量。
- 一个单词在英文词汇表中的索引位置是多少,相对应的那一行就为1,其他行都为0.

缺点
- 没有表示出任何词汇之间的内在关系概念。(例如近义词之间的关系)

分布式表示 Distributed Representation
- 根据训练某种语言的每一个词,映射成一个固定的低维度短向量。
- 向量的每一维都表示潜在的语义或语法特征。
- 所有这些向量构成一个词向量空间,根据词向量之间的距离判断词与词之间语法,语义的相似性。
word2vec
- word2vec只包含输入层,隐藏层和输出层。
- 根据输入的不同,分为CBOW和Skip-Gram模型。
CBOW
- 根据上下文,预测中心词汇。
- 然后根据损失函数判断预测的准确性。
- -t 表示除 t 外所有其他的上下文词汇。
- 目标:调整词汇表示,令损失函数J最小。
Skip-gram
- 根据中心词汇,预测上下文。
- 利用训练样本(input word,output word)训练,所输出的概率分布表示单词在上下文出现的概率。
- 以下图为例,输出即为$P(w_{into}|w_{banking})$、$P(w_{turning}|w_{banking})$、$P(w_{crises}|w_{banking})$、$P(w_{as}|w_{banking})$.
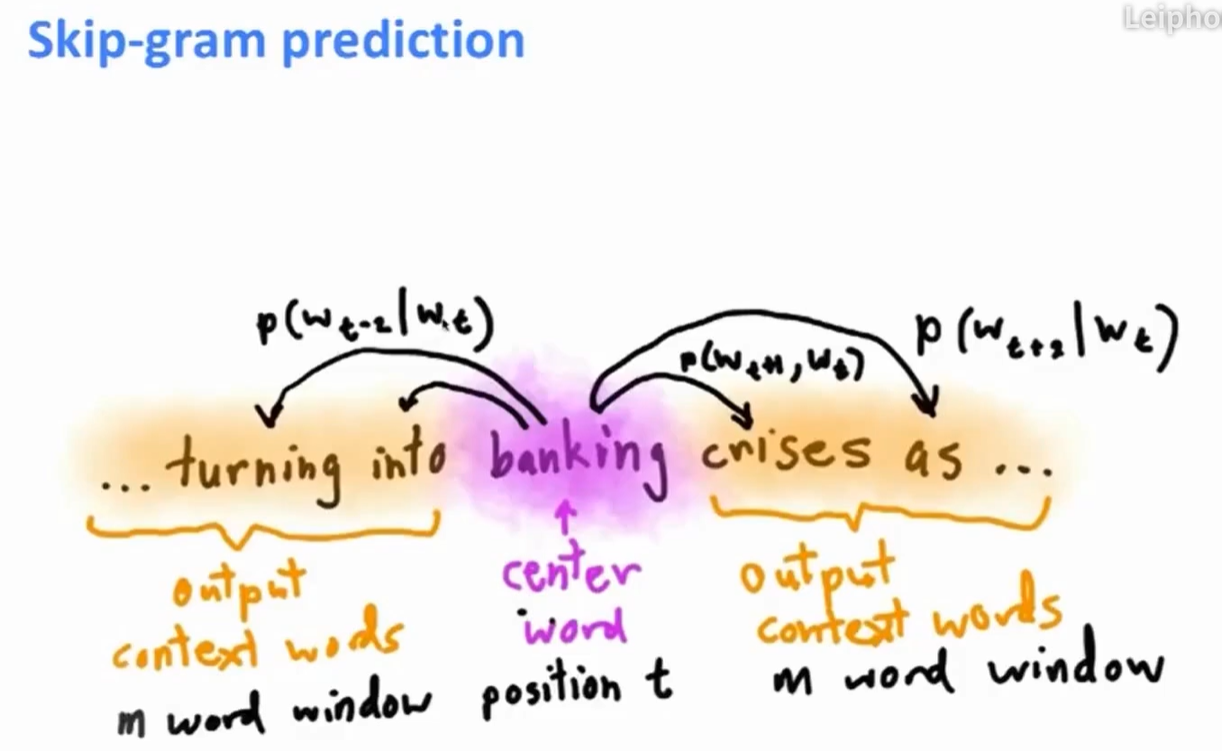
- $J'$(目标函数):表示在一篇拥有足够多词汇的文本里,遍历文本中的所有位置,对于每个位置,定义一个围绕中心词汇,大小为2m的窗口(中心词前后各m个单词),得到一个概率分布。然后设置模型的参数$\theta$,令上下文中所有词汇出现的概率尽可能大。这里转化为对数的形式,求最小值。
- $\theta$:词汇的向量表示。

- o表示单词在词汇表空间中的索引,c表示中心词汇的索引。
- o(输出单词),c(中心单词)。
- t和t+j是单词在文本中的位置。
- $u_o$是除中心词以外的词向量,$v_c$是中心词所对应的向量。
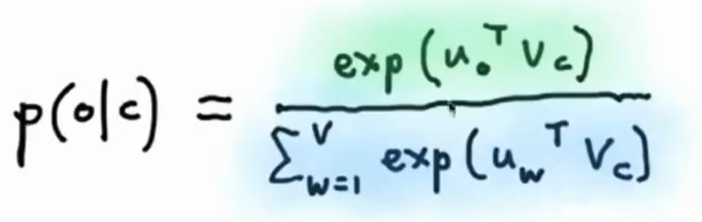
- 运用Softmax函数确定相应的概率分布。Softmax函数能把输入的实数变成分数。
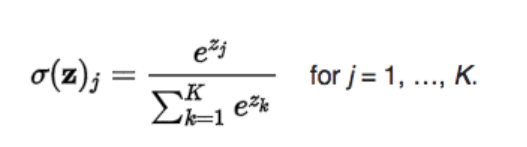
Skipgram算法的实现过程
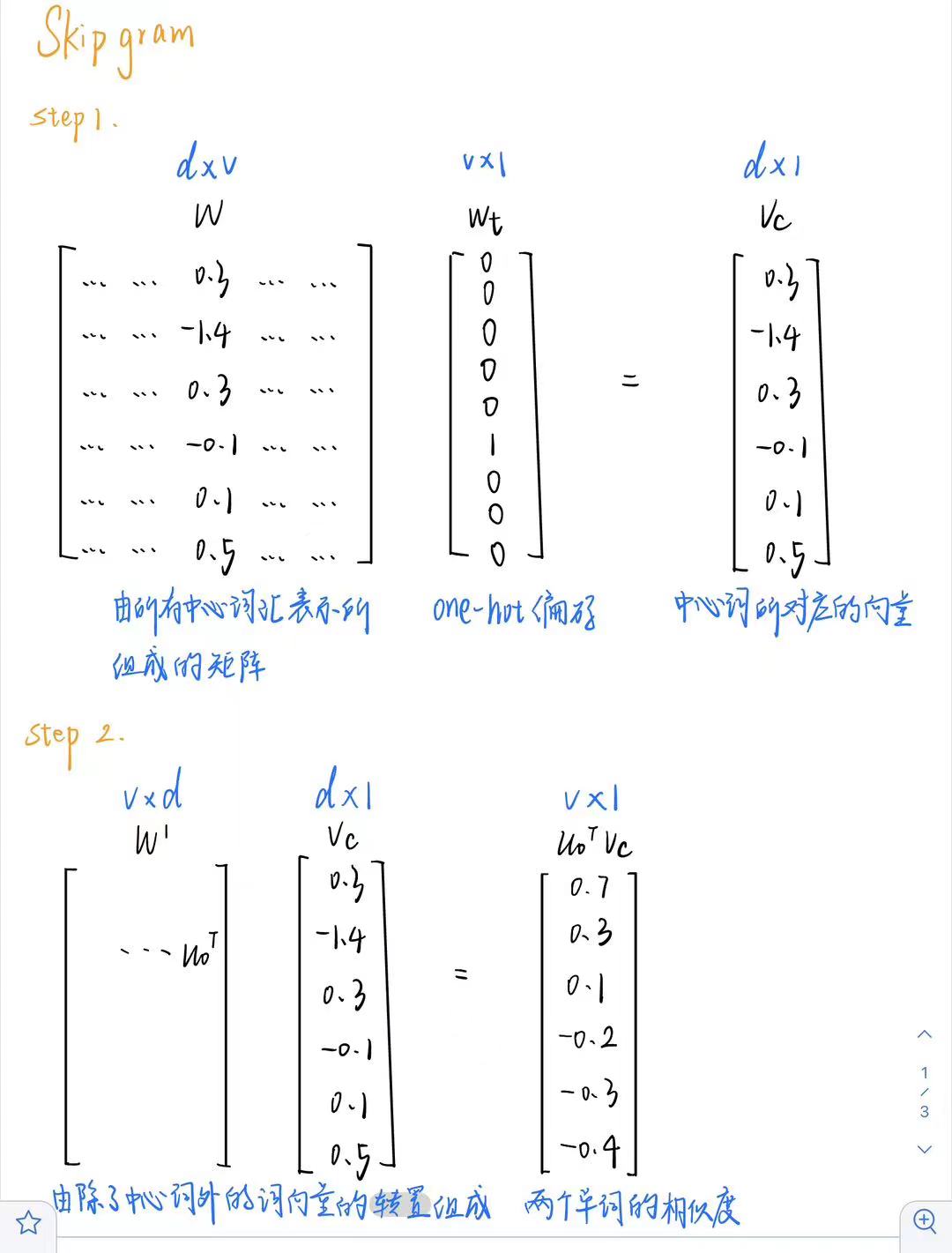

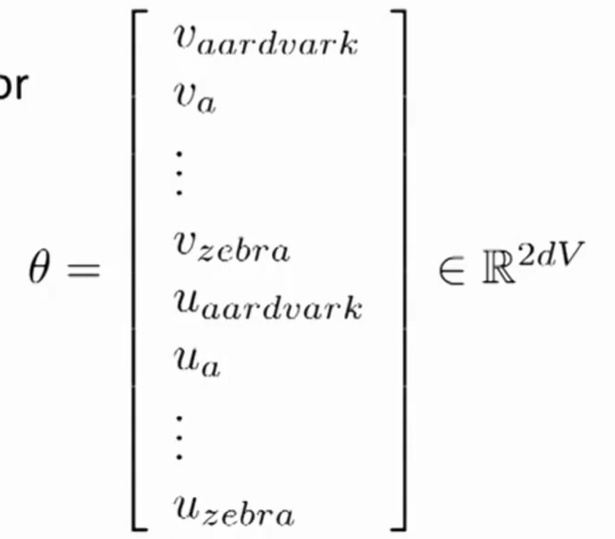
参数 $\theta$
- 将所有的参数放到$\theta$中,每个单词为一个d维向量,$\theta$的长度是2dV。
- 然后优化这些参数。
优化
- 令目标方程$J(\theta)=-\frac{1}{T}\sum_{t=1}^{T}\sum_{-m≤j≤m}logp(w_{t+j}|w_{t})$最小。
- 使用随机梯度下降算法 (SGD)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号