Scrapy框架的安装与使用
Scrapy的安装与使用
1. 环境介绍
1.1 前言
自己最近也是一直在学习python,主要原因还是因为自己会或多或少的使用到一些脚本,常常羡慕大佬写的脚本和爬虫,总希望自己也能够编写出好用的脚本和爬虫,本文章主要是介绍python爬虫框架scrapy的使用。
1.2 本机环境
主机系统:Windows 10 专业版
Python 版本:3.8
开发工具:Pycharm
Scrapy 版本:2.4.1
2. Scrapy简介
Scrapy 是一个为了抓取网页数据、提取结构性数据而编写的应用框架,是纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强。该框架是封装的,包含 request (异步调度和处理)、下载器(多线程的 Downloader)、解析器(selector)和 twisted(异步处理)等。对于网站的内容爬取,其速度非常快。
3. Scrapy框架及流程图
3.1 Scrapy框架架构图
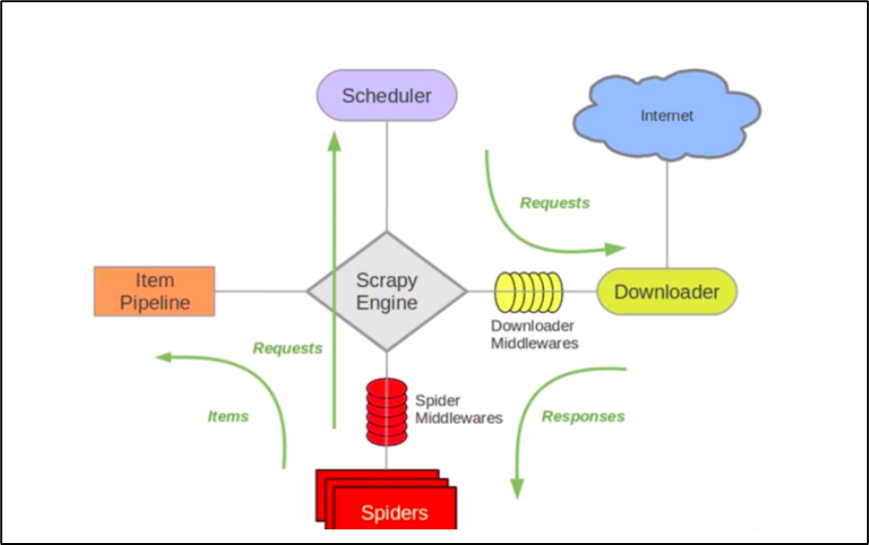
-
ScrapyEngine:引擎。负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 此组件相当于爬虫的“大脑”,是 整个爬虫的调度中心。
-
Schedule:调度器。接收从引擎发过来的requests,并将他们入队。初始爬取url和后续在页面里爬到的待爬取url放入调度器中,等待被爬取。调度器会自动去掉重复的url。
-
Downloader:下载器。负责获取页面数据,并提供给引擎,而后提供给spider。
-
Spider:爬虫。用户编些用于分析response并提取item和额外跟进的url。将额外跟进的url提交给ScrapyEngine,加入到Schedule中。将每个spider负责处理一个特定(或一些)网站。
-
ItemPipeline:负责处理被spider提取出来的item。当页面被爬虫解析所需的数据存入Item后,将被发送到Pipeline,并经过设置好次序。
-
DownloaderMiddlewares:下载中间件。是在引擎和下载器之间的特定钩子(specific hook),处理它们之间的请求(request)和响应(response)。提供了一个简单的机制,通过插入自定义代码来扩展Scrapy功能。通过设置DownloaderMiddlewares来实现爬虫自动更换user-agent,IP等。
-
SpiderMiddlewares:Spider中间件。是在引擎和Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items或requests)。提供了同样简单机制,通过插入自定义代码来扩展Scrapy功能。
3.2 Scrapy流程图:
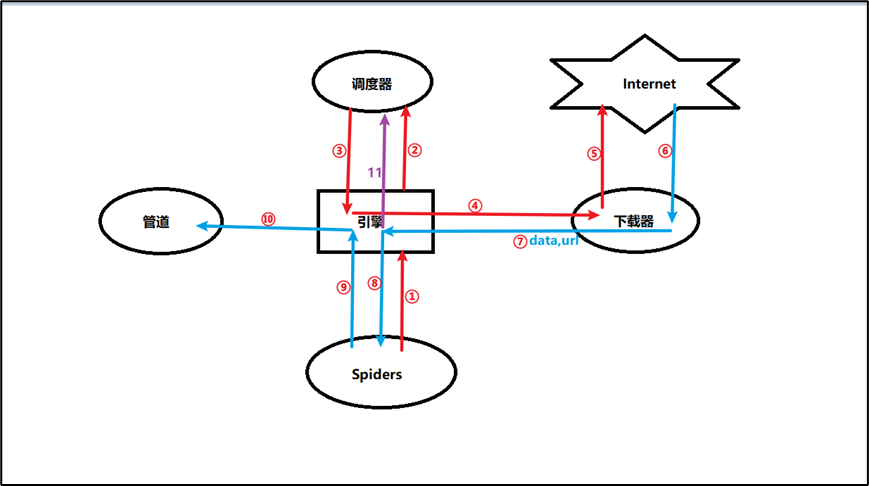
步骤解析:
- spiders将url发送给engine
- engine对url不做任何处理发送给scheduler,scheduler将请求放入队列
- scheduler,生成request交给engine
- engine拿到request,发送给downloader
- downloader拿到request,访问网络资源
- 从Internet拿到相应的response,返回到downloader
- downloader将获取到的response(data + url)发送给engine
- engine获取到response之后,返回给spider,spider的parse()方法对获取到的response进行处理,解析出items或者requests
- 将解析出来的items或者requests发送给engine
- engine获取到items或者requests,将items发送给ItemPipeline处理
- engine将requests发送给scheduler
4. Scrapy的安装
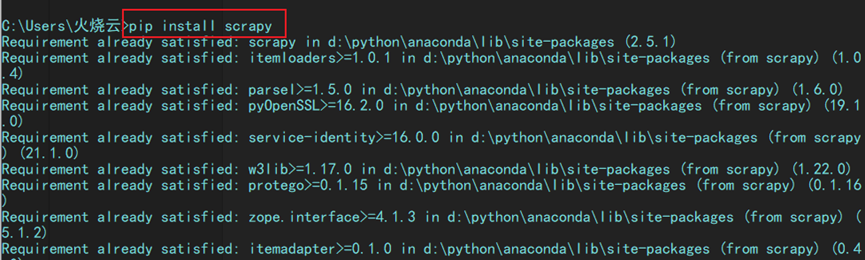
4.1 命令行安装
pip install twisted
pip install scrapy
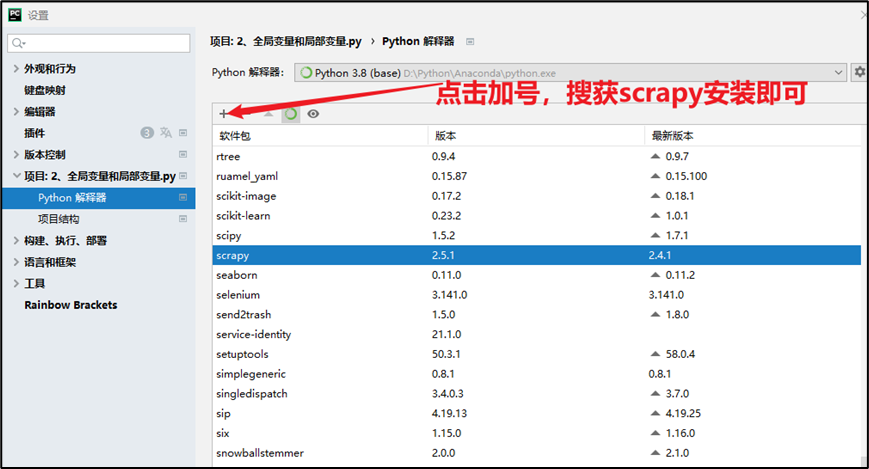
4.2 软件中安装
打开pycharm,点击 文件>设置>项目>python解释器
5. Scrapy的使用介绍
5.1 Scrapy经常使用的命令
创建项目:scrapy startproject xxx
进入项目:cd xxx (进入某个文件夹下)
创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
运行爬虫:scrapy crawl XXX

列出所有爬虫:scrapy list

scrapy项目结构:

5.2 项目介绍:
- 外部的demo目录:整个项目目录
- 内部的demo目录:整个项目的全局目录
- spiders:存放spiders的文件夹;
- items.py:Items的定义,定义爬取的数据结构;
- middlewares.py:项目中间件文件,定义爬取时的中间件
- pipelines.py:项目管道文件,定义数据管道;
- settings:项目设置文件;
- scrapy.cfg:Scrapy部署配置文件;
5.3 settings.py的介绍
BOT_NAME # 爬虫名
ROBOTSTXT_OBEY =False # 遵守robots协议,一般设置为False
USER_AGENT='' # 指定爬取时使用。一定要更改user-agent,否则访问会报403错误
CONCURRENT_REQUEST = 16 # 默认16个并行
DOWNLOAD_DELAY = 3 # 下载延时
COOKIES_ENABLED = False # 缺省是启用。一般需要登录时才需要开启cookie
DEFAULT_REQUEST_HEADERS = {} # 默认请求头,需要时填写
SPIDER_MIDDLEWARES # 爬虫中间件
DOWNLOADER_MIDDLEWARES # 下载中间件
' demo.middlewares.FirstDownloaderMiddleware': 543 # 543优先级越小越高
' demo.pipelines.FirstscrapyPipeline': 300 # item交给哪一个管道处理,300优先级越小越高
6. Scrapy的实战简介
本次爬取的是糗事百科段子 https://www.qiushibaike.com/text/ 按照前面的步骤创建相应的项目,这里只是简单介绍需要注意的地方。
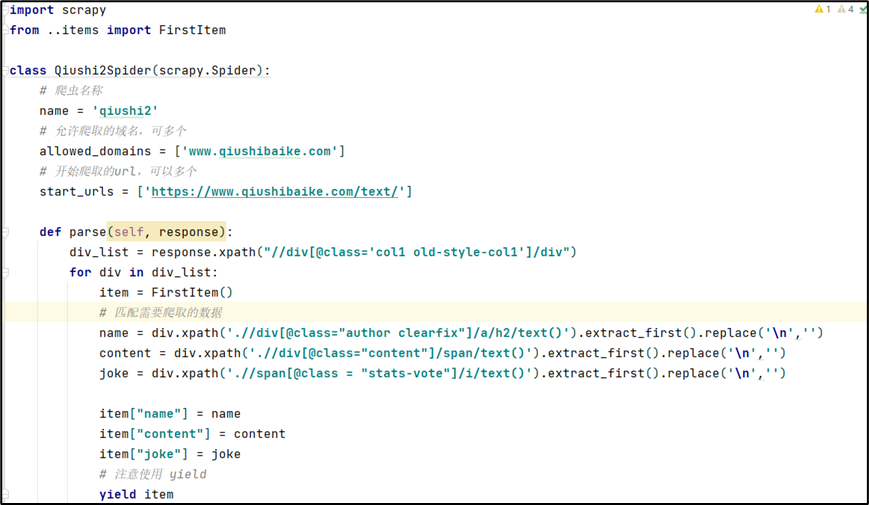
6.1 spider.py文件
在创建的爬虫文件中,写入相应的代码。
- 注意将items模块导入
- 使用yield 将item返回
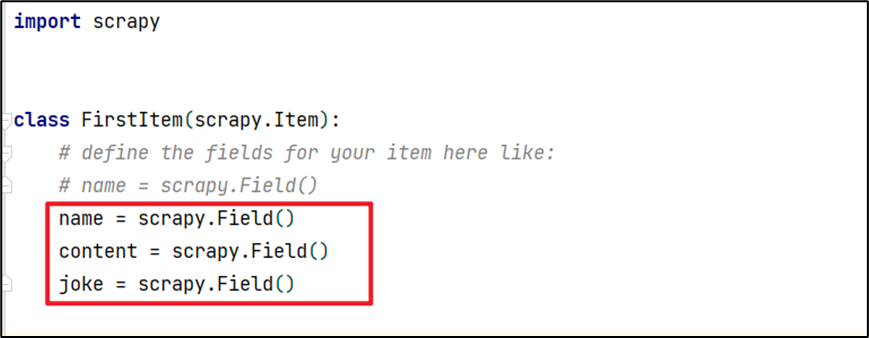
6.2 items.py文件
注意在爬虫文件中使用的参数,需要相对应。
6.3 Pipelines.py文件
该文件主要是对数据进行最后的操作,写入文件或者存入数据库中,两种方式实现过程类似。
将数据写入文件
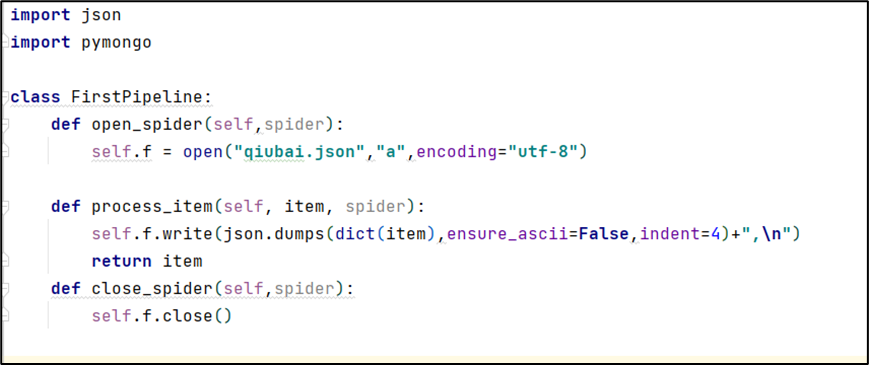
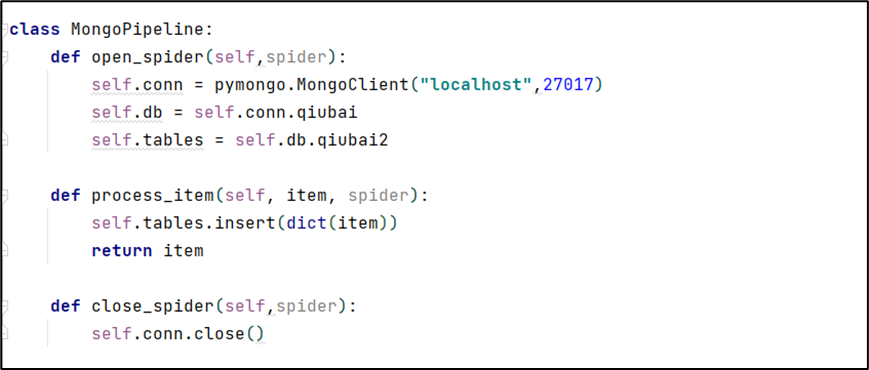
将文件存入数据库(MongoDB)
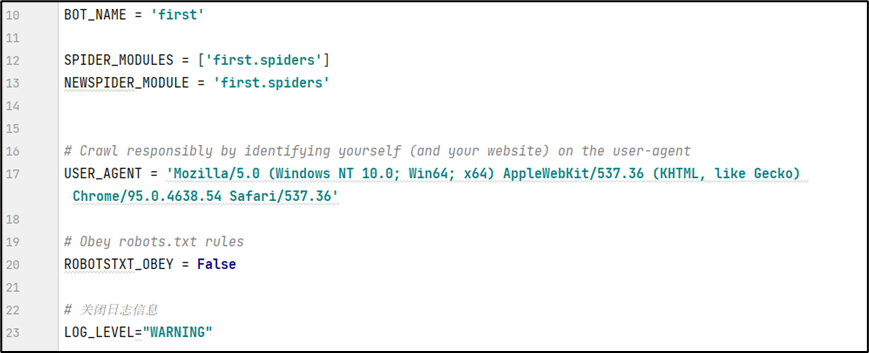
6.4 Settings.py文件
文件需要进行修改,需要使用的地方,解除掉相应的注释。
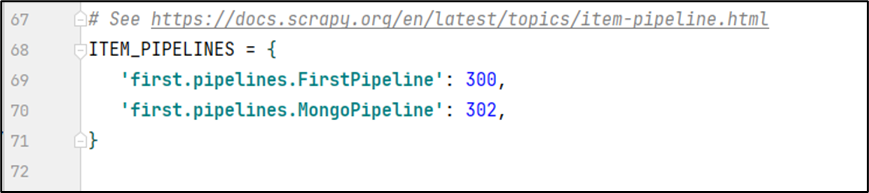
使用到了pipelines,所以需要ITEM_PIPELINES
6.5 运行爬虫文件

文件展示:

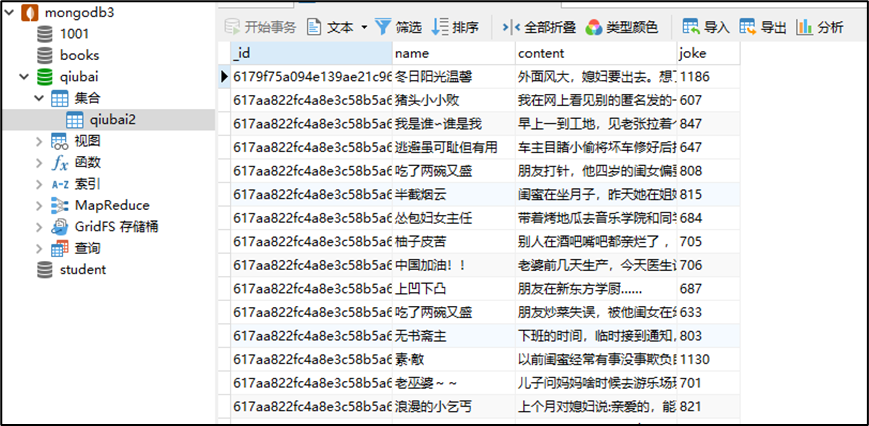
数据库展示:
7. Scrapy的请求方式
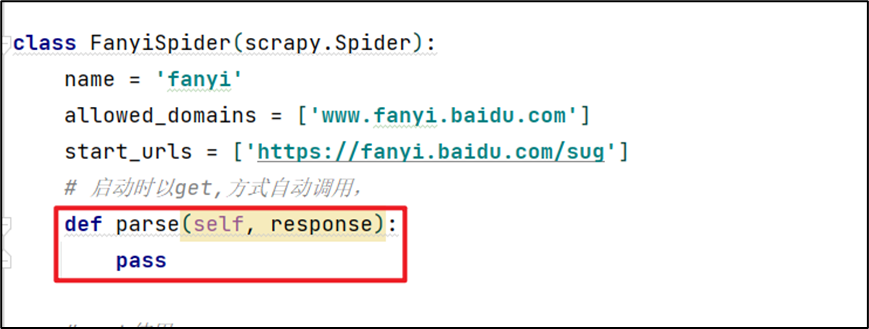
7.1 GET请求方式
在默认情况下,使用的都是get请求方式,在爬虫文件中默认启动 parse()方法。
7.2 POST请求方式
使用post方法,就意味着我有额外数据进行传输。需要重新实现一个方法start_requests(),使用这个方法的时候,主要需要一个新的url,和另外的方法。
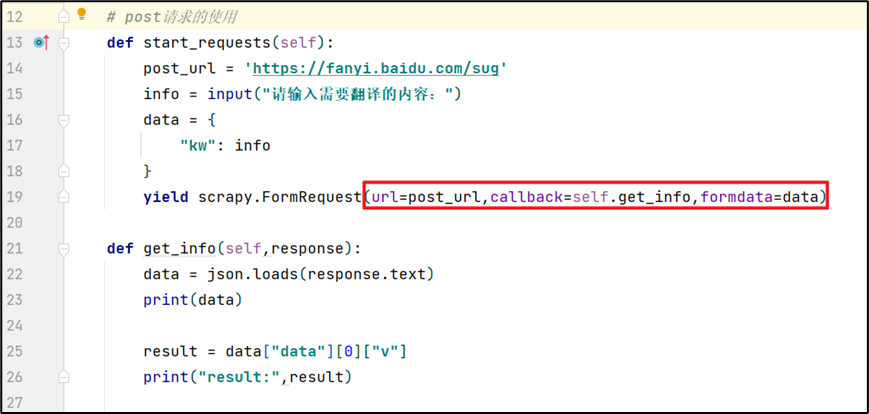
需要注意的地方:
- 使用scrapy.Request()方法,该方法能构建一个requests,同时指定提取数据的callback函数
- url:需要解析的url链接(字符串类型);
- callback:指定传入的url交给哪个解析函数去处理;
- 解析的函数定义需要有response参数
8. Scrapy常见问题
8.1 关于运行流程
只有调度器中不存在request时,程序才停止,及时请求失败scrapy也会重新进行请求
8.2 屏蔽日志信息
文件运行后发现终端里面多了很多log日志,这时可以通过在settings.py添加以下代码,就可以屏蔽这些log日志:
LOG_LEVEL="WARNING"
8.3 路径问题
将数据保存在文件中时,如果使用的是相对路径,则会以运行爬虫文件的目录作为相对路径,避免文件路径设置错误。
8.4 保存数据问题
数据可以保存在文件和数据库中,先保存在文件中,然后再保存在数据库中,因为使用的时mongo数据库时,会被多加上一个id字段,管道会将数据全部返回出来,所以再写入时,会出现问题。可以在settings.py中设置权重,决定顺序。(权重越小越先执行)
8.5 返回数据的方式
在spider爬虫中返回数据使用yield,那么为什么要使用yield,我用return不能行吗?行,但yield是让整个函数变成一个生成器,每次遍历的时候挨个读到内存中,这样不会导致内存的占用量瞬间变高。
8.6 pipelines文件问题
pipeline中的process_item()方法名不能修改为其他的名称,同时注意函数方法都是规定的,变量名称不能修改,因为变量会被多个回调函数调用,定义新类之后,需要在settings.py文件中添加相应的名称。
8.7 爬虫启动方式
- 命令行指令
一开始使用爬虫都是在CMD命令行使用scrapy crawl xxx。

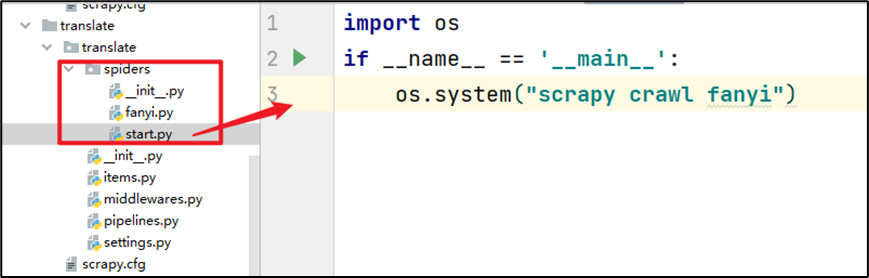
这种方法在我们需要进行交互的时候,就有些不太方便,内容显示的格式也不太清晰。每次运行需要cmd窗口,不是很方便,为了解决这个问题那就用脚本运行脚本。 - 脚本文件运行
直接在相应的项目下面创建一个脚本文件,输入简单的语句,直接运行start.py文件就直接可以启动爬虫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号