HashMap和ConcurrentHashMap的原理
HashMap
- HashMap里面一个数组,数组中每个元素是一个单向链表,链表由一个个Entry构成,每个Entry实例包含四个属性:key,value,hash值和用于单向链表的next。
- 可以存储Null键和Null值,线程不安全;
- 无序
有序的Map:TreeMap, LinkedHashMap,
TreeMap 是通过实现 SortMap 接口,能够把它保存的键值对根据 key 排序,基于红黑树,从而保证 TreeMap 中所有键值对处于有序状态。
LinkedHashMap 则是通过插入排序(就是你 put 的时候的顺序是什么,取出来的时候就是什么样子)和访问排序(改变排序把访问过的放到底部)让键值有序。
put:
- 判断当前数组是否需要初始化;
- 如果Key为空,则put空值;
- 根据key计算hashcode定位出所在桶(数组下标)
- 如果桶是链表,判重,如果没有重复,则放到链表的表头
- 如果桶是空,新增一个entry对象写入当前位置
- 插入新值时需要判断是否需要扩容,扩容后,数组大小为原来的 2 倍。
扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
双倍扩容
get:
根据Key计算hash值,定位数据下标
如果是链表,遍历链表,直到Key和hashcode相等,就返回值
else return null
线程不安全:
hash碰撞:如果多个线程同时操作HashMap,进行Put,而有多个Key的hash值相同。这个时候就需要通过链表解决Hash冲突,如果两个线程恰好都取道了对应位置的插入节点,一定会有一个数据丢失;
扩容:多个线程同时检测到总数量超过门限值的时候就会同时调用resize,各自生成新的数组并且rehash后赋值给map底层的数组table,结果最终只有最后一个线程生成的新数组被赋予table变量。
resize扩容 transfer出现并发问题
Java7---Java8
Treeify-threshold:判断是否需要将链表转为红黑树的阈值;(Hash冲突后,链表会过长)
HashEntry-〉Node
二叉查找树的缺陷:二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成层次很深的问题),遍历查找会非常慢。
而红黑树在插入新数据后可能需要通过左旋、右旋、变色这些操作来保持平衡。
引入红黑树就是为了查找数据快,解决链表查询深度的问题。
我们知道红黑树属于平衡二叉树,为了保持“平衡”是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少。
所以当长度大于8的时候,会使用红黑树;如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
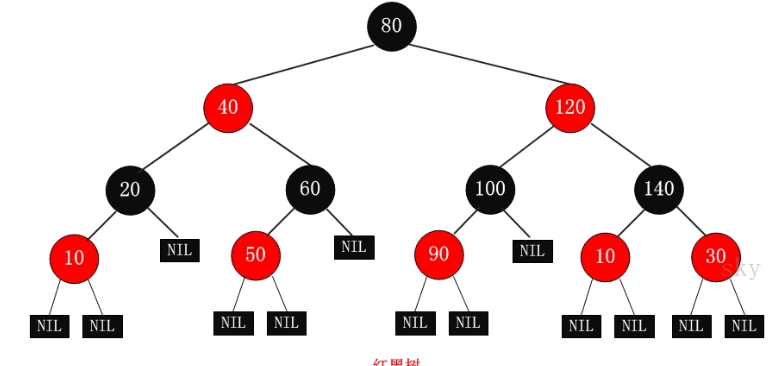
红黑树:
- 每个节点非红即黑
- 根节点总是黑色的
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
- 每个叶子节点都是黑色的空节点(NIL节点)
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
ConcurrentHashMap
- 底层是数组加链表,线程安全;
- 通过把整个Map分成N个Segment
使用volatile 关键字


 浙公网安备 33010602011771号
浙公网安备 33010602011771号