

P31_完整的模型验证套路
完整的模型验证(测试,demo)套路——利用已经训练好的模型,然后给它提供输入
1.png和jpg格式的图片通道数
(1)png格式的图片是4通道(RGB三通道+透明度通道),jpg格式的图片是3通道(RGB),可以用PIL.Image.convert('RGB')来转换(不同截图软件保留的通道数也不一样)。
(2)transform.Conpose的使用:
Compose()中的参数需要是一个列表:
Compose([transforms参数1,transforms参数2...])
(3)使用案例如下:
点击查看代码
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
2.小细节:
将model设置到model.eval(),with torch.no_grad()可以节约内存,提高性能。
(1)model.eval()
model.eval()是PyTorch中模型的一个方法,用于设置模型为评估模式。在评估模式下,模型的所有层都将正常运行,但不会进行反向传播(backpropagation)和参数更新。
(2)torch.no_grad()
torch.no_grad()是PyTorch的一个上下文管理器,用于在不需要计算梯度的场景下禁用梯度计算。在使用torch.no_grad()上下文管理器的情况下,所有涉及张量操作的函数都将不会计算梯度,从而节省内存和计算资源。
3.将在gpu上训练的模型导入到在cup上运行的程序时要添加:
map_location=torch.device('cpu')关键字参数。
(1)读取dog的照片,并利用train里面跑出来的模型dyl_0.pth进行预测

(2)代码如下
点击查看代码
import torch
import torchvision
from PIL import Image
from torch import nn
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
img_path =r"D:\DeepLearning\Learn_torch\images\dog.png"
#读取这张图片
image = Image.open(img_path)
print(image)
# image.show()
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Dyl(nn.Module):
def __init__(self):
super(Dyl, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2) , #padding为2,之前计算过
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model(x)
return x
#加载网络模型:
# model = torch.load("dyl_0.pth")
#将在gpu上训练的模型导入到在cup上运行的程序时要添加:map_location=torch.device('cpu')关键字参数
model = torch.load("dyl_0.pth", map_location='cpu')
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
(3)它训练的结果不是很准确:
点击查看代码
<PIL.PngImagePlugin.PngImageFile image mode=RGB size=456x336 at 0x2B5F2FF6A90>
torch.Size([3, 32, 32])
Dyl(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
tensor([[-1.4050, -0.2401, 0.9364, 0.8570, 1.0776, 1.0941, 1.3038, 0.7209,
-2.0690, -1.1032]])
tensor([6])
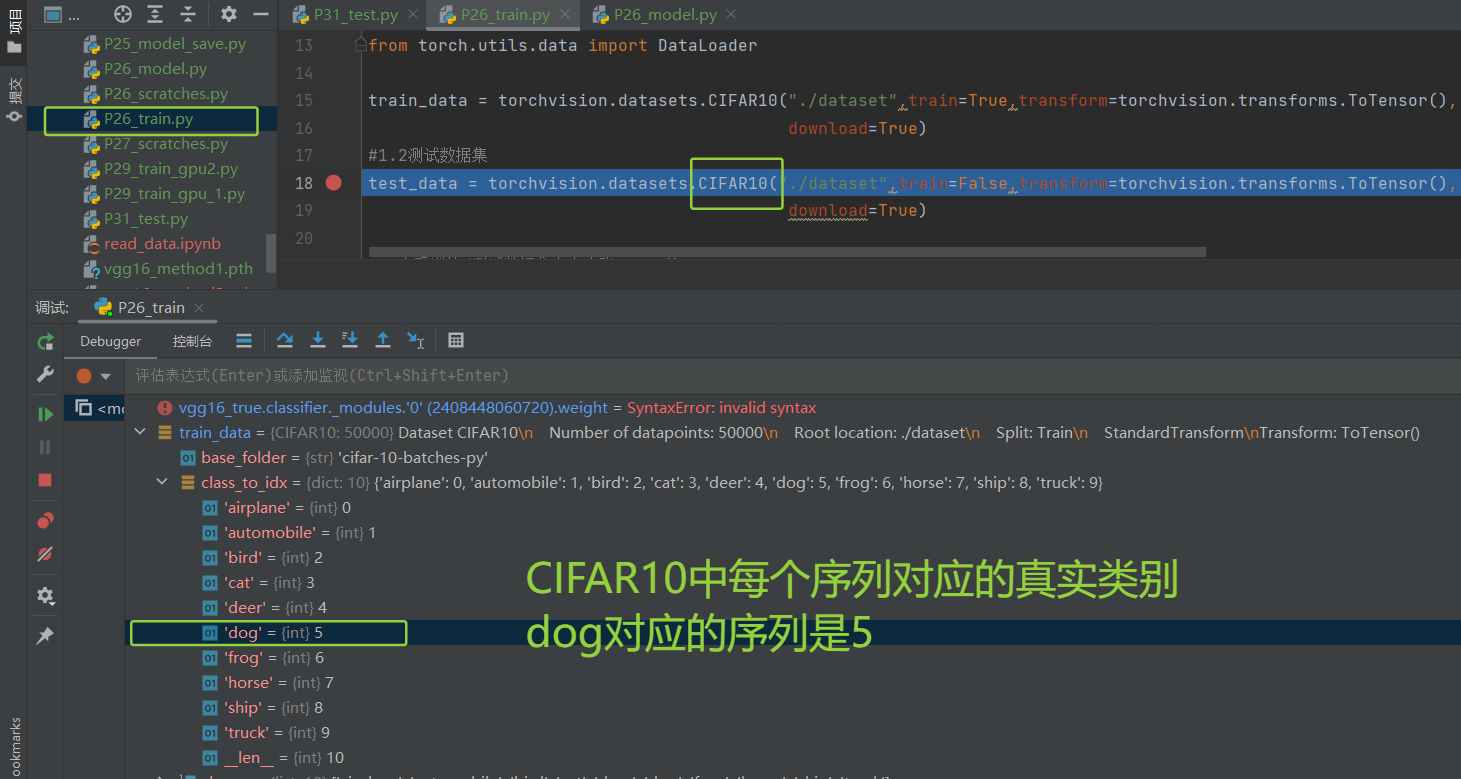
预测结果是tensor([6]),
但是打开P26_train.py的test_data打断点发现CIFAR10中的dog对应的序列是5,而不是6
(4)应对措施:
可以多训练几次
例如把epoch训练10轮改成训练30轮,并使用谷歌的gpu来跑模型,保存模型另设(以作区分):
点击查看代码
#8.3用epoch记录训练轮次,训练10轮
epoch = 30
#11.保存模型(保存每一轮训练的结果)
torch.save(dyl,"dyl_{}_gpu.pth".format(i))
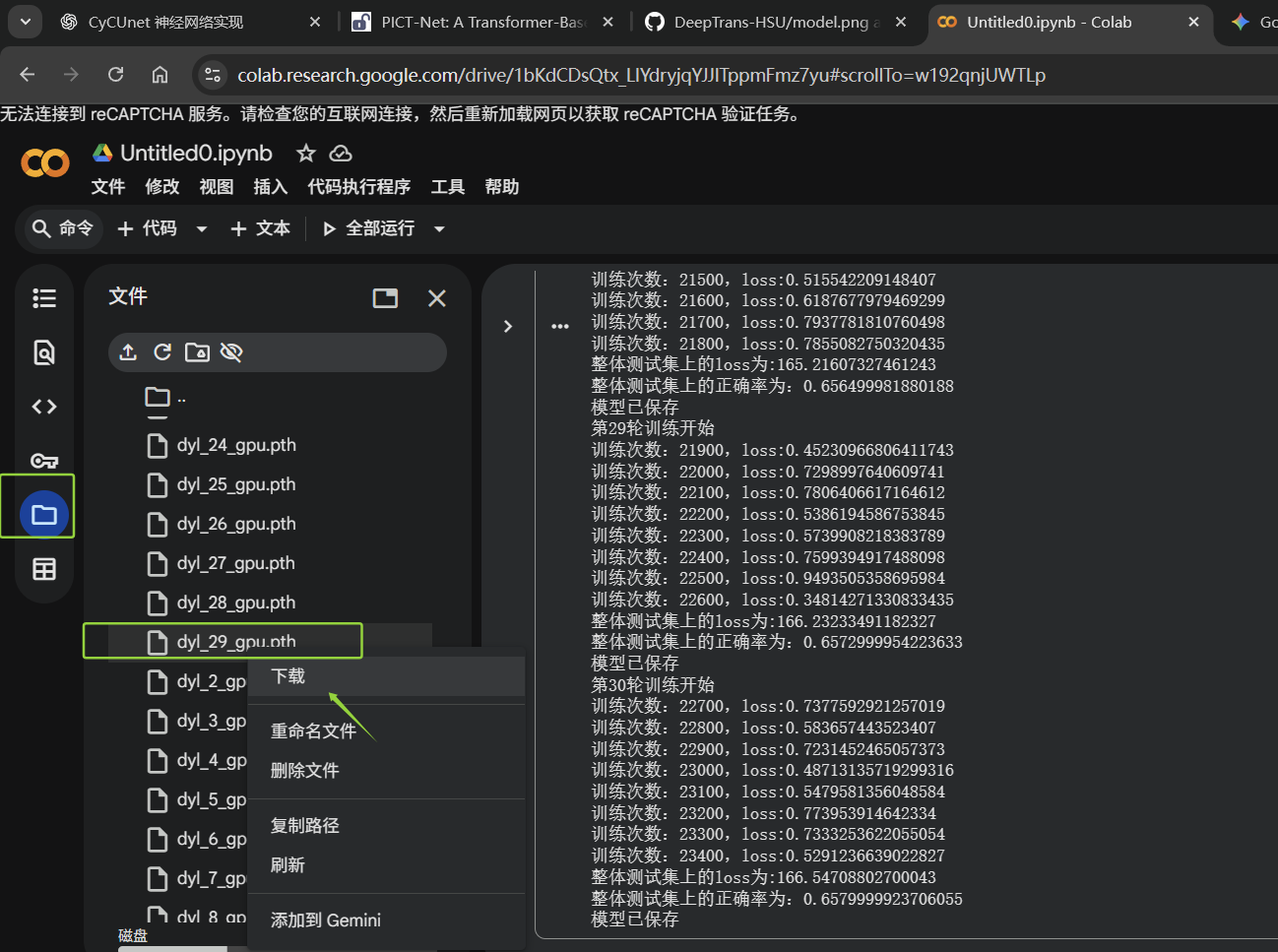
(5)把训练的模型下载到对应文件夹目录
训练了3分钟
把dyl_29_gpu.pth、dyl_28_gpu.pth、dyl_27_gpu.pth和dyl_16_gpu.pth等都下载下来了,
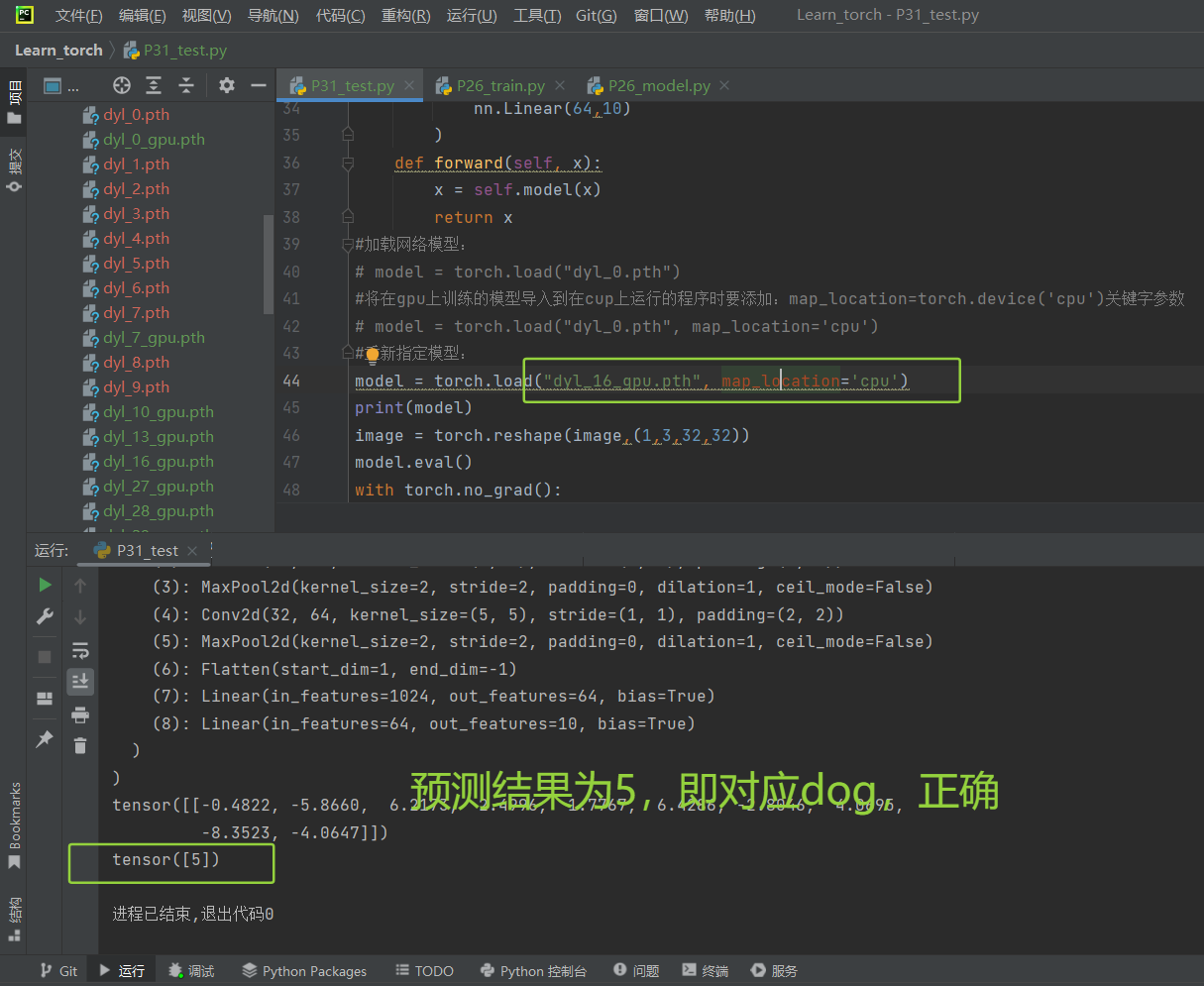
(6)打开pycharm,重新指定模型:
我试的是dyl_16_gpu.pth,使得运行成果是tensor([5])即dog
【我试了好几个模型包括dyl_29_gpu.pth,但是预测的效果不是很好,是tensor([2])即预测成了bird】
点击查看代码
#将在gpu上训练的模型导入到在cup上运行的程序时要添加:map_location=torch.device('cpu')关键字参数
#model = torch.load("dyl_0.pth", map_location='cpu')
#重新指定模型:
model = torch.load("dyl_16_gpu.pth", map_location='cpu')
(7)运行成果:
tensor([5])
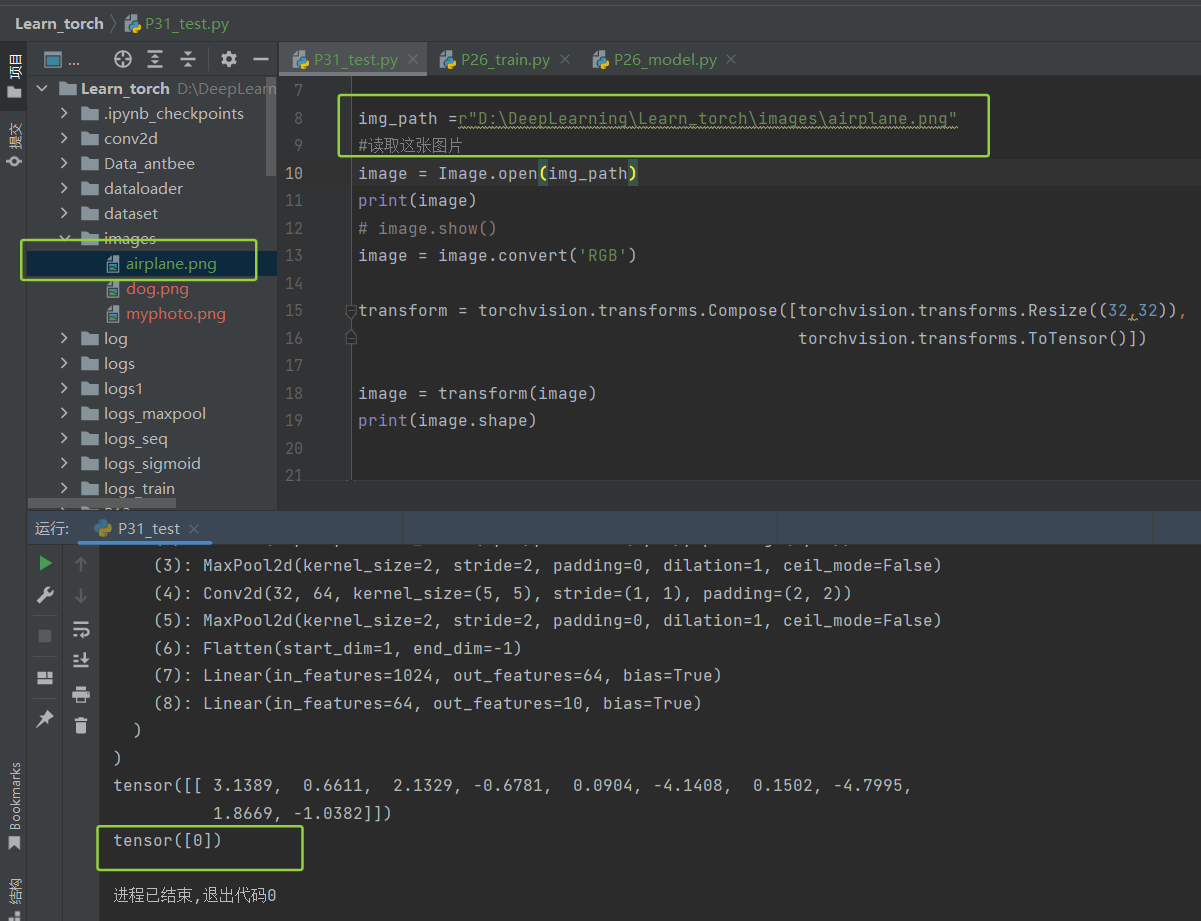
(8)把dog换成了airplane 试试:

预测airplane得到tensor[0],预测正确:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号