

P27_完整的模型训练套路(二)
如何辨别模型在训练过程中有没有训练好以及有没有达到我需要训练的需求?
不需要对模型进行调优了,直接利用现有的模型来进行一个测试:
9.测试步骤开始:
用with torch.no_grad():环境取消梯度
点击查看代码
#9.测试步骤开始:
total_test_loss = 0
with torch.no_grad(): #梯度没有了,能保证不会对其进行调优
for data in test_dataloader:
imgs,targets = data
outputs = dyl(imgs)
loss = loss_fn(outputs,targets)
# total_test_loss = total_test_loss + loss
#由于total_test_loss初始化为0,是个int类型,而loss是tensor数据类型,使用loss.item()
total_test_loss = total_test_loss + loss.item()
print("整体测试及上的loss为:{}".format(total_test_loss))
10.添加tensorboard
(1)tensorboard代码:
点击查看代码
#10.添加tensorboard
writer = SummaryWriter("logs_train")
...
writer.add_scalar("train_loss",loss.item(),total_train_step)
...
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step = total_test_step + 1
writer.close()
其中,add_sclaer()内的参数:
①tag:Data identifier,要求是一个string,【标题】
②scalar_value:Value to save【要保存的值,作为y轴】
③globalstep:Global step value to record【移动的步数,作为x轴】
(2)整体代码
点击查看代码
import torchvision
#4.从训练文件引入P26_model文件的所有东西
from torch.utils.tensorboard import SummaryWriter
from P26_model import *
#1.准备数据集
#1.1训练数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
#1.2测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#2.查看训练/测试数据集有多少张:len()
train_data_size = len(train_data)
test_data_size = len(test_data)
#打印:python中格式化字符串的一种写法
#如果train_data_size=10,则打印输出:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("训练测试集的长度为:{}".format(test_data_size))
#3.使用DataLoader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#4.搭建神经网络
#(由于CIFAR10有10个类别,则网络为10分类的网络):CIFAR10模型结构
# class Dyl(nn.Module):
# def __init__(self):
# super(Dyl, self).__init__()
# self.model = nn.Sequential(
# nn.Conv2d(3,32,5,1,2) , #padding为2,之前计算过
# nn.MaxPool2d(2),
# nn.Conv2d(32,32,5,1,2),
# nn.MaxPool2d(2),
# nn.Conv2d(32,64,5,1,2),
# nn.MaxPool2d(2),
# nn.Flatten(),
# nn.Linear(1024,64),
# nn.Linear(64,10)
# )
# def forward(self, x):
# x = self.model(x)
# return x
#一般会把以上模型单独保存在一个py文件里面:P26_model.py
#注意:model文件和该train.py要在同一文件夹下
#5.创建网络模型
dyl = Dyl()
#6.创建损失函数(交叉熵)
loss_fn = nn.CrossEntropyLoss()
#7.定义优化器
#learning_rate = 0.01
#1e-2=1*(10)^(-2)=1/100=0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(dyl.parameters(),lr = learning_rate)
#8.设置训练网络的一些参数
#8.1用total_train_step记录训练的次数
total_train_step = 0
#8.2用total_test_step记录测试的次数
total_test_step = 0
#8.3用epoch记录训练轮次,训练10轮
epoch = 10
#10.添加tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#8.4训练步骤开始:
#从训练的dataloader去取数据:
for data in train_dataloader:
imgs,targets = data
outputs = dyl(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
#优化器梯度清零
optimizer.zero_grad()
#损失反向传播:得到每一个参数节点的梯度
loss.backward()
#调用优化器的step:对其中每个参数进行优化
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
#print("训练次数:{},loss:{}".format(total_train_step,loss))
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#9.测试步骤开始:
total_test_loss = 0
with torch.no_grad(): #梯度没有了,能保证不会对其进行调优
for data in test_dataloader:
imgs,targets = data
outputs = dyl(imgs)
loss = loss_fn(outputs,targets)
# total_test_loss = total_test_loss + loss
#由于total_test_loss初始化为0,是个int类型,而loss是tensor数据类型,使用loss.item()
total_test_loss = total_test_loss + loss.item()
print("整体测试集上的loss为:{}".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step = total_test_step + 1
writer.close()
(3)运行结果
点击查看代码
......
第10轮训练开始
训练次数:7100,loss:1.2895336151123047
训练次数:7200,loss:0.9272681474685669
训练次数:7300,loss:1.1410796642303467
训练次数:7400,loss:0.8670981526374817
训练次数:7500,loss:1.230800747871399
训练次数:7600,loss:1.2306654453277588
训练次数:7700,loss:0.8554573655128479
训练次数:7800,loss:1.2604162693023682
整体测试集上的loss为:196.08706438541412
(4)整体代码运行后在tensorboard打开:tensorboard --logdir=logs_train
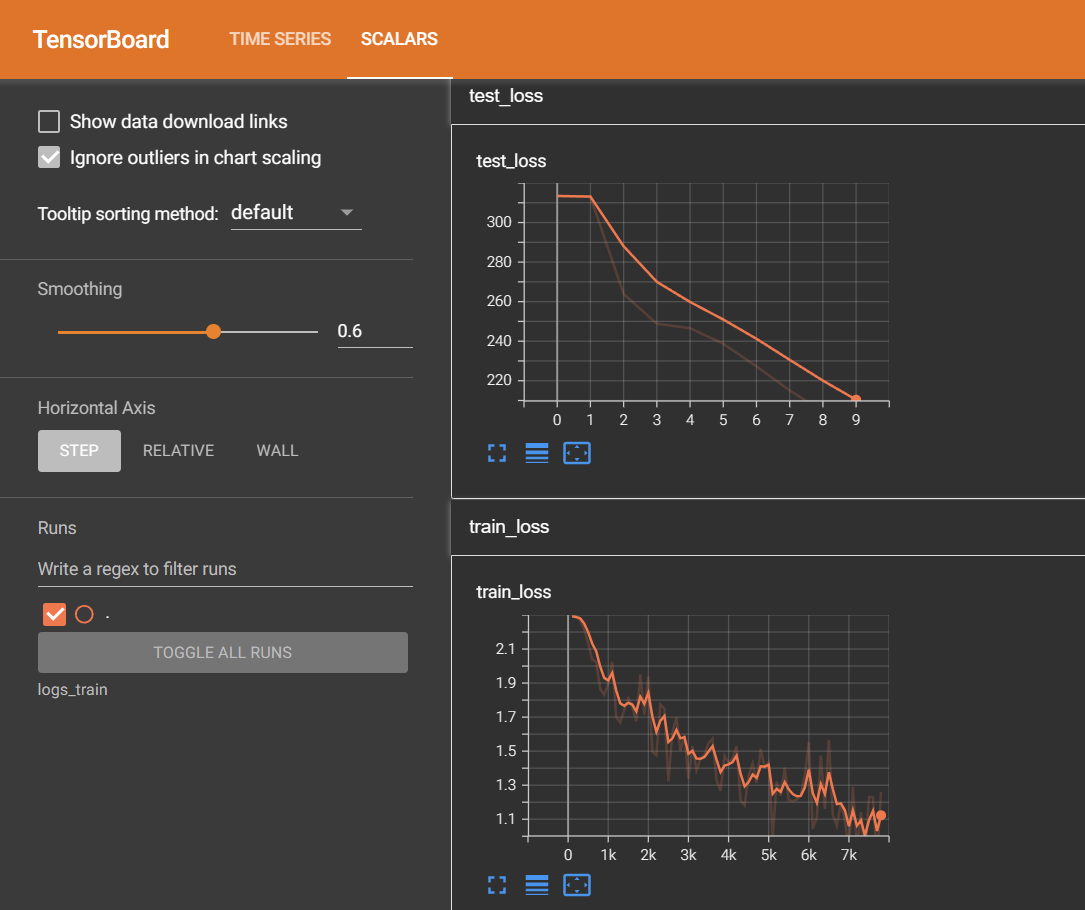
【即便得到整体测试集上的loss,也不能很好的说明在测试集上的表现效果,那么在分类问题中,可以计算正确率】
11.保存模型(保存每一轮训练的结果)
点击查看代码
#11.保存模型(保存每一轮训练的结果)
torch.save(dyl,"dyl_{}.pth".format(i))
print("模型已保存")
官方推荐的模型保存方式:
torch.save(dyl.state_dict(),"dyl_{}.pth".format(i))
12.利用torch.argmax函数计算准确率(针对分类问题)
(1)原理
①argmax(1):横向;argmax(0):纵向
②将以下图片的计算准确率的过程写入代码

③代码如下
点击查看代码
import torch
#经过2分类模型后的分类结果:
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
#横向上,0.1和0.2中0.2大,即0和1的位置中1大,同理,0.3和0.4中1大,输出[1,1]
print(outputs.argmax(1))
preds = outputs.argmax(1) #预测出来是[1,1]
targets = torch.tensor([0,1]) #但是真实target是[0,1]
print(preds == targets) #两者相等就输出True否则False
print((preds == targets).sum()) #计算对应位置相等的个数
④输出为:
点击查看代码
tensor([1, 1])
tensor([False, True])
tensor(1)
(2)代码实战
点击查看代码
......
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#8.4训练步骤开始:
......
#9.测试步骤开始:
......
#12.计算整体正确率
total_accuracy = 0
with torch.no_grad(): #梯度没有了,能保证不会对其进行调优
for data in test_dataloader:
......
accuracy = (outputs.argmax(1) == targets ).sum()
total_accuracy = total_accuracy + accuracy
......
#整体测试集上的正确率 = 总共预测对的数据/测试数据集上的个数
print("整体测试集上的正确率为:{}".format(total_accuracy/test_data_size))
......
#加到tensorboard中
writer.add_scalar("test_accuracy",
total_accuracy/test_data_size,total_test_step)
......
输出为:
点击查看代码
第1轮训练开始
训练次数:100,loss:2.290350914001465
训练次数:200,loss:2.283881187438965
训练次数:300,loss:2.2415573596954346
训练次数:400,loss:2.143307685852051
训练次数:500,loss:2.0154404640197754
训练次数:600,loss:2.030125379562378
训练次数:700,loss:1.9807674884796143
整体测试集上的loss为:311.0230861902237
整体测试集上的正确率为:0.28690001368522644
模型已保存
......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号