

P26_完整的模型训练套路(一)
1.准备数据集
训练数据集和测试数据集
点击查看代码
#1.准备数据集
#1.1训练数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#1.2测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
2.查看训练/测试数据集有多少张:len()
点击查看代码
#2.查看训练/测试数据集有多少张:len()
train_data_size = len(train_data)
test_data_size = len(test_data)
#打印:python中格式化字符串的一种写法
#如果train_data_size=10,则打印输出:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("训练测试集的长度为:{}".format(test_data_size))
得到:
点击查看代码
训练数据集的长度为:50000
训练测试集的长度为:10000
3.使用DataLoader来加载数据集
点击查看代码
#3.使用DataLoader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
4.搭建神经网络
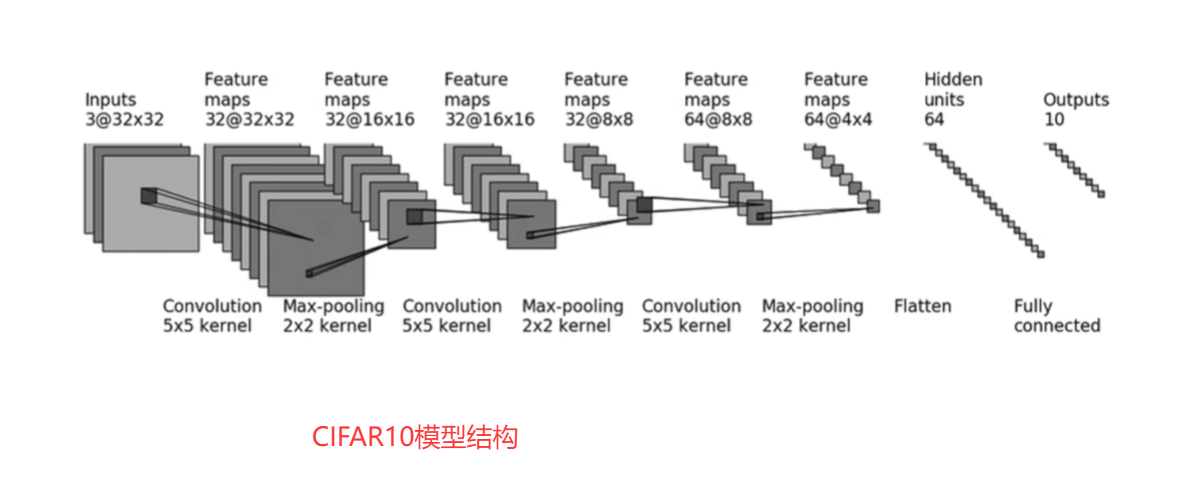

根据上面的模型架构,构建神经网络如下:
点击查看代码
#4.搭建神经网络
import torch
from torch import nn
class Dyl(nn.Module):
def __init__(self):
super(Dyl, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2) , #padding为2,之前计算过
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model(x)
return x
一般情况下,可以单独在同一文件夹下,单独创建一个py文件专门存储以上搭建的神经网络,并加入main函数:
点击查看代码
if __name__ == '__main__':
dyl = Dyl()
#验证网络的正确性:
input = torch.ones((64,3,32,32))
output = dyl(input)
print(output.shape)
输出为:
torch.Size([64, 10])
把以上模型构建和输出保存到P26_model.py中,这样就可以在P26_train代码中引入了:
点击查看代码
#4.从训练文件引入P26_model文件的所有东西
from P26_model import *
5.创建网络模型
点击查看代码
#5.创建网络模型
dyl = Dyl()
6.创建损失函数(交叉熵)
点击查看代码
#6.创建损失函数(交叉熵)
loss_fn = nn.CrossEntropyLoss()
7.定义优化器
点击查看代码
#7.定义优化器
#learning_rate = 0.01
#1e-2=1*(10)^(-2)=1/100=0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(dyl.parameters(),lr = learning_rate)
8.设置训练网络的一些参数
8.1用total_train_step记录训练的次数
8.2用total_test_step记录测试的次数
8.3用epoch记录训练轮次,训练10轮
点击查看代码
#8.设置训练网络的一些参数
#8.1用total_train_step记录训练的次数
total_train_step = 0
#8.2用total_test_step记录测试的次数
total_test_step = 0
#8.3用epoch记录训练轮次,训练10轮
epoch = 10
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
点击查看代码
第1轮训练开始
第2轮训练开始
第3轮训练开始
第4轮训练开始
第5轮训练开始
第6轮训练开始
第7轮训练开始
第8轮训练开始
第9轮训练开始
第10轮训练开始
8.4训练步骤开始:
点击查看代码
#8.设置训练网络的一些参数
#8.1用total_train_step记录训练的次数
total_train_step = 0
#8.2用total_test_step记录测试的次数
total_test_step = 0
#8.3用epoch记录训练轮次,训练10轮
epoch = 10
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#8.4训练步骤开始:
#从训练的dataloader去取数据:
for data in train_dataloader:
imgs,targets = data
outputs = dyl(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
#优化器梯度清零
optimizer.zero_grad()
#损失反向传播:得到每一个参数节点的梯度
loss.backward()
#调用优化器的step:对其中每个参数进行优化
optimizer.step()
total_train_step = total_train_step + 1
print("训练次数:{},loss:{}".format(total_train_step,loss))
#print("训练次数:{},loss:{}".format(total_train_step,loss.item())
其中loss.item()和loss的区别:
点击查看代码
import torch
a = torch.tensor(5)
print(a)
print(a.item())
得到:
点击查看代码
tensor(5)
5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号